 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies
Mar 12, 2026Vision-Language-Action (VLA) models have significant potential to enable general-purpose robotic systems for a range of vision-language tasks. However, the performance of VLA-based robots is highly sensitive to the precise wording of language instructions, and it remains difficult to predict when such robots will fail. To improve the robustness of VLAs to different wordings, we present Q-DIG (Quality Diversity for Diverse Instruction Generation), which performs red-teaming by scalably identifying diverse natural language task descriptions that induce failures while remaining task-relevant. Q-DIG integrates Quality Diversity (QD) techniques with Vision-Language Models (VLMs) to generate a broad spectrum of adversarial instructions that expose meaningful vulnerabilities in VLA behavior. Our results across multiple simulation benchmarks show that Q-DIG finds more diverse and meaningful failure modes compared to baseline methods, and that fine-tuning VLAs on the generated instructions improves task success rates. Furthermore, results from a user study highlight that Q-DIG generates prompts judged to be more natural and human-like than those from baselines. Finally, real-world evaluations of Q-DIG prompts show results consistent with simulation, and fine-tuning VLAs on the generated prompts further success rates on unseen instructions. Together, these findings suggest that Q-DIG is a promising approach for identifying vulnerabilities and improving the robustness of VLA-based robots. Our anonymous project website is at qdigvla.github.io.
Causally Robust Reward Learning from Reason-Augmented Preference Feedback
Mar 05, 2026Preference-based reward learning is widely used for shaping agent behavior to match a user's preference, yet its sparse binary feedback makes it especially vulnerable to causal confusion. The learned reward often latches onto spurious features that merely co-occur with preferred trajectories during training, collapsing when those correlations disappear or reverse at test time. We introduce ReCouPLe, a lightweight framework that uses natural language rationales to provide the missing causal signal. Each rationale is treated as a guiding projection axis in an embedding space, training the model to score trajectories based on features aligned with that axis while de-emphasizing context that is unrelated to the stated reason. Because the same rationales (e.g., "avoids collisions", "completes the task faster") can appear across multiple tasks, ReCouPLe naturally reuses the same causal direction whenever tasks share semantics, and transfers preference knowledge to novel tasks without extra data or language-model fine-tuning. Our learned reward model can ground preferences on the articulated reason, aligning better with user intent and generalizing beyond spurious features. ReCouPLe outperforms baselines by up to 1.5x in reward accuracy under distribution shifts, and 2x in downstream policy performance in novel tasks. We have released our code at https://github.com/mj-hwang/ReCouPLe
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024



We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
NOIR: Neural Signal Operated Intelligent Robots for Everyday Activities
Nov 02, 2023



We present Neural Signal Operated Intelligent Robots (NOIR), a general-purpose, intelligent brain-robot interface system that enables humans to command robots to perform everyday activities through brain signals. Through this interface, humans communicate their intended objects of interest and actions to the robots using electroencephalography (EEG). Our novel system demonstrates success in an expansive array of 20 challenging, everyday household activities, including cooking, cleaning, personal care, and entertainment. The effectiveness of the system is improved by its synergistic integration of robot learning algorithms, allowing for NOIR to adapt to individual users and predict their intentions. Our work enhances the way humans interact with robots, replacing traditional channels of interaction with direct, neural communication. Project website: https://noir-corl.github.io/.
Primitive Skill-based Robot Learning from Human Evaluative Feedback
Aug 02, 2023Reinforcement learning (RL) algorithms face significant challenges when dealing with long-horizon robot manipulation tasks in real-world environments due to sample inefficiency and safety issues. To overcome these challenges, we propose a novel framework, SEED, which leverages two approaches: reinforcement learning from human feedback (RLHF) and primitive skill-based reinforcement learning. Both approaches are particularly effective in addressing sparse reward issues and the complexities involved in long-horizon tasks. By combining them, SEED reduces the human effort required in RLHF and increases safety in training robot manipulation with RL in real-world settings. Additionally, parameterized skills provide a clear view of the agent's high-level intentions, allowing humans to evaluate skill choices before they are executed. This feature makes the training process even safer and more efficient. To evaluate the performance of SEED, we conducted extensive experiments on five manipulation tasks with varying levels of complexity. Our results show that SEED significantly outperforms state-of-the-art RL algorithms in sample efficiency and safety. In addition, SEED also exhibits a substantial reduction of human effort compared to other RLHF methods. Further details and video results can be found at https://seediros23.github.io/.
Task-Driven Graph Attention for Hierarchical Relational Object Navigation
Jun 23, 2023



Embodied AI agents in large scenes often need to navigate to find objects. In this work, we study a naturally emerging variant of the object navigation task, hierarchical relational object navigation (HRON), where the goal is to find objects specified by logical predicates organized in a hierarchical structure - objects related to furniture and then to rooms - such as finding an apple on top of a table in the kitchen. Solving such a task requires an efficient representation to reason about object relations and correlate the relations in the environment and in the task goal. HRON in large scenes (e.g. homes) is particularly challenging due to its partial observability and long horizon, which invites solutions that can compactly store the past information while effectively exploring the scene. We demonstrate experimentally that scene graphs are the best-suited representation compared to conventional representations such as images or 2D maps. We propose a solution that uses scene graphs as part of its input and integrates graph neural networks as its backbone, with an integrated task-driven attention mechanism, and demonstrate its better scalability and learning efficiency than state-of-the-art baselines.
Decentralized Vehicle Coordination: The Berkeley DeepDrive Drone Dataset
Sep 22, 2022
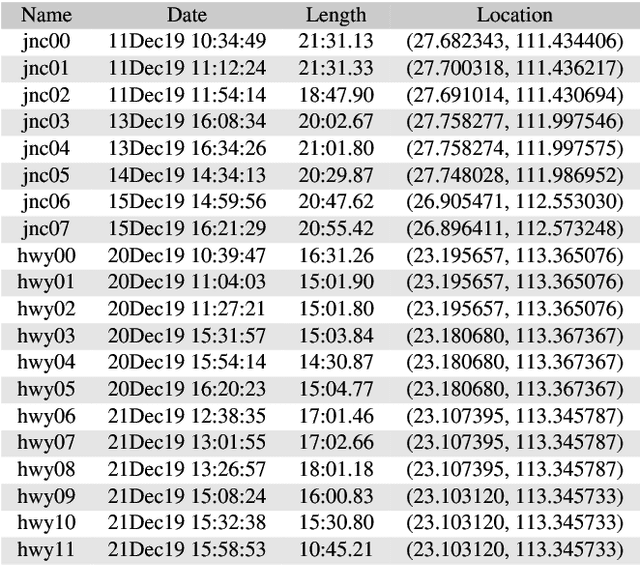


Decentralized multiagent planning has been an important field of research in robotics. An interesting and impactful application in the field is decentralized vehicle coordination in understructured road environments. For example, in an intersection, it is useful yet difficult to deconflict multiple vehicles of intersecting paths in absence of a central coordinator. We learn from common sense that, for a vehicle to navigate through such understructured environments, the driver must understand and conform to the implicit "social etiquette" observed by nearby drivers. To study this implicit driving protocol, we collect the Berkeley DeepDrive Drone dataset. The dataset contains 1) a set of aerial videos recording understructured driving, 2) a collection of images and annotations to train vehicle detection models, and 3) a kit of development scripts for illustrating typical usages. We believe that the dataset is of primary interest for studying decentralized multiagent planning employed by human drivers and, of secondary interest, for computer vision in remote sensing settings.
Text Analytics for Resilience-Enabled Extreme EventsReconnaissance
Nov 26, 2020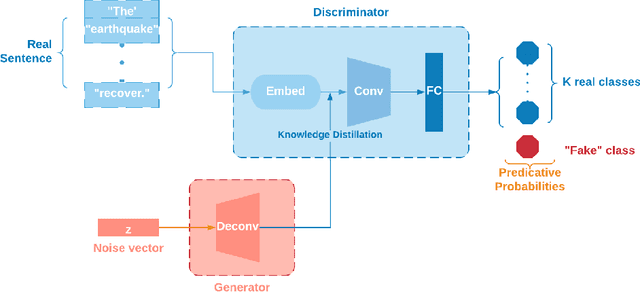
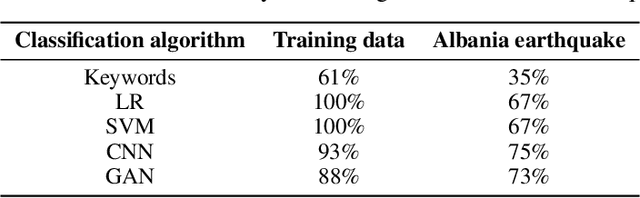
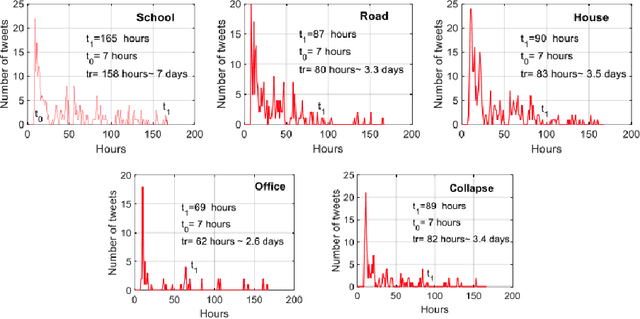

Post-hazard reconnaissance for natural disasters (e.g., earthquakes) is important for understanding the performance of the built environment, speeding up the recovery, enhancing resilience and making informed decisions related to current and future hazards. Natural language processing (NLP) is used in this study for the purposes of increasing the accuracy and efficiency of natural hazard reconnaissance through automation. The study particularly focuses on (1) automated data (news and social media) collection hosted by the Pacific Earthquake Engineering Research (PEER) Center server, (2) automatic generation of reconnaissance reports, and (3) use of social media to extract post-hazard information such as the recovery time. Obtained results are encouraging for further development and wider usage of various NLP methods in natural hazard reconnaissance.
Minority Reports Defense: Defending Against Adversarial Patches
Apr 28, 2020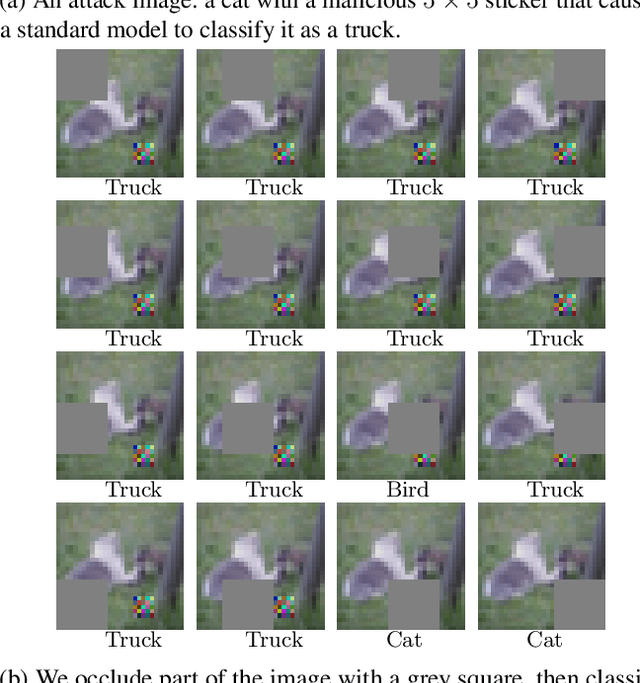
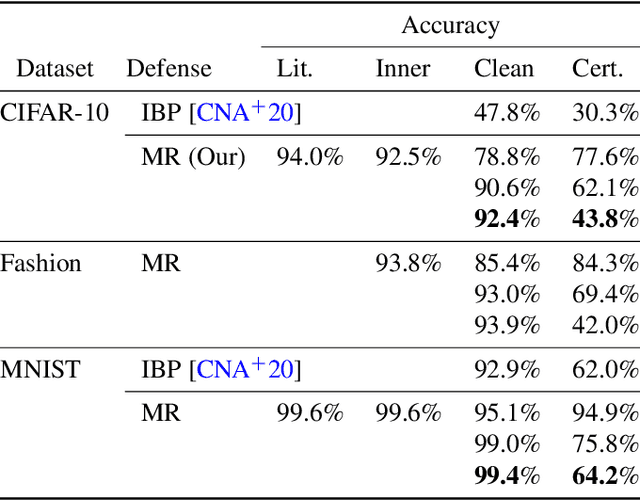
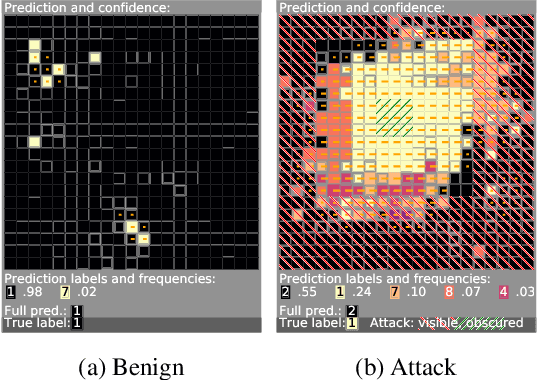
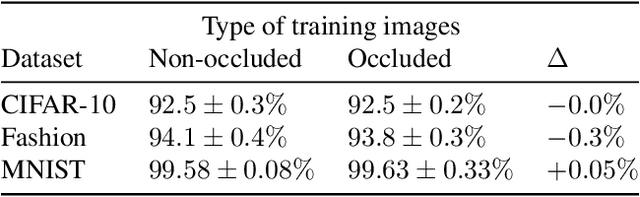
Deep learning image classification is vulnerable to adversarial attack, even if the attacker changes just a small patch of the image. We propose a defense against patch attacks based on partially occluding the image around each candidate patch location, so that a few occlusions each completely hide the patch. We demonstrate on CIFAR-10, Fashion MNIST, and MNIST that our defense provides certified security against patch attacks of a certain size.