 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoPolicy: Improving Robotic Manipulation Policies via Stereo Perception
May 11, 2026Recent advances in robot imitation learning have yielded powerful visuomotor policies capable of manipulating a wide variety of objects directly from monocular visual inputs. However, monocular observations inherently lack reliable depth cues and spatial awareness, which are critical for precise manipulation in cluttered or geometrically complex scenes. To address this limitation, we introduce StereoPolicy, a new visuomotor policy learning framework that directly leverages synchronized stereo image pairs to strengthen geometric reasoning, without requiring explicit 3D reconstruction or camera calibration. StereoPolicy employs pretrained 2D vision encoders to process each image independently and fuses the resulting representations through a Stereo Transformer. This design implicitly captures spatial correspondence and disparity cues. The framework integrates seamlessly with diffusion-based and pretrained vision-language-action (VLA) policies, delivering consistent improvements over RGB, RGB-D, point cloud, and multi-view baselines across three simulation benchmarks: RoboMimic, RoboCasa, and OmniGibson. We further validate StereoPolicy on real-robot experiments spanning both tabletop and bimanual mobile manipulation settings. Our results underscore stereo vision as a scalable and robust modality that bridges 2D pretrained representations with 3D geometric understanding for robotic manipulation.
CAGE-SGG: Counterfactual Active Graph Evidence for Open-Vocabulary Scene Graph Generation
Apr 28, 2026Open-vocabulary scene graph generation (SGG) aims to describe visual scenes with flexible and fine-grained relation phrases beyond a fixed predicate vocabulary. While recent vision-language models greatly expand the semantic coverage of SGG, they also introduce a critical reliability issue: predicted relations may be driven by language priors or object co-occurrence rather than grounded visual evidence. In this paper, we propose an evidence-rounded open-vocabulary SGG framework based on counterfactual relation verification. Instead of directly accepting plausible relation proposals, our method verifies whether each candidate relation is supported by relation-pecific visual, geometric, and contextual evidence. Specifically, we first generate open-vocabulary relation candidates with a vision-language proposer, then decompose predicate phrases into soft evidence bases such as support, contact, containment, depth, motion, and state. A relation-conditioned evidence encoder extracts predicate-relevant cues, while a counterfactual verifier tests whether the relation score decreases when necessary vidence is removed and remains stable under irrelevant perturbations. We further introduce contradiction-aware predicate learning and graph-level preference optimization to improve fine-grained discrimination and global graph consistency. Experiments on conventional, open-vocabulary, and panoptic SGG benchmarks show that our method consistently improves standard recall-based metrics, unseen predicate generalization, and counterfactual grounding quality. These results demonstrate that moving from relation generation to relation verification leads to more reliable, interpretable, and evidence-grounded scene graphs.
IMPASTO: Integrating Model-Based Planning with Learned Dynamics Models for Robotic Oil Painting Reproduction
Mar 31, 2026Robotic reproduction of oil paintings using soft brushes and pigments requires force-sensitive control of deformable tools, prediction of brushstroke effects, and multi-step stroke planning, often without human step-by-step demonstrations or faithful simulators. Given only a sequence of target oil painting images, can a robot infer and execute the stroke trajectories, forces, and colors needed to reproduce it? We present IMPASTO, a robotic oil-painting system that integrates learned pixel dynamics models with model-based planning. The dynamics models predict canvas updates from image observations and parameterized stroke actions; a receding-horizon model predictive control optimizer then plans trajectories and forces, while a force-sensitive controller executes strokes on a 7-DoF robot arm. IMPASTO integrates low-level force control, learned dynamics models, and high-level closed-loop planning, learns solely from robot self-play, and approximates human artists' single-stroke datasets and multi-stroke artworks, outperforming baselines in reproduction accuracy. Project website: https://impasto-robopainting.github.io/
FruitTouch: A Perceptive Gripper for Gentle and Scalable Fruit Harvesting
Feb 22, 2026The automation of fruit harvesting has gained increasing significance in response to rising labor shortages. A sensorized gripper is a key component of this process, which must be compact enough for confined spaces, able to stably grasp diverse fruits, and provide reliable feedback on fruit conditions for efficient harvesting. To address this need, we propose FruitTouch, a compact gripper that integrates high-resolution, vision-based tactile sensing through an optimized optical design. This configuration accommodates a wide range of fruit sizes while maintaining low cost and mechanical simplicity. Tactile images captured by an embedded camera provide rich information for real-time force estimation, slip detection, and softness prediction. We validate the gripper in real-world fruit harvesting experiments, demonstrating robust grasp stability and effective damage prevention.
Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?
Feb 04, 2026Spatial embodied intelligence requires agents to act to acquire information under partial observability. While multimodal foundation models excel at passive perception, their capacity for active, self-directed exploration remains understudied. We propose Theory of Space, defined as an agent's ability to actively acquire information through self-directed, active exploration and to construct, revise, and exploit a spatial belief from sequential, partial observations. We evaluate this through a benchmark where the goal is curiosity-driven exploration to build an accurate cognitive map. A key innovation is spatial belief probing, which prompts models to reveal their internal spatial representations at each step. Our evaluation of state-of-the-art models reveals several critical bottlenecks. First, we identify an Active-Passive Gap, where performance drops significantly when agents must autonomously gather information. Second, we find high inefficiency, as models explore unsystematically compared to program-based proxies. Through belief probing, we diagnose that while perception is an initial bottleneck, global beliefs suffer from instability that causes spatial knowledge to degrade over time. Finally, using a false belief paradigm, we uncover Belief Inertia, where agents fail to update obsolete priors with new evidence. This issue is present in text-based agents but is particularly severe in vision-based models. Our findings suggest that current foundation models struggle to maintain coherent, revisable spatial beliefs during active exploration.
Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow
Dec 31, 2025Generative video modeling has emerged as a compelling tool to zero-shot reason about plausible physical interactions for open-world manipulation. Yet, it remains a challenge to translate such human-led motions into the low-level actions demanded by robotic systems. We observe that given an initial image and task instruction, these models excel at synthesizing sensible object motions. Thus, we introduce Dream2Flow, a framework that bridges video generation and robotic control through 3D object flow as an intermediate representation. Our method reconstructs 3D object motions from generated videos and formulates manipulation as object trajectory tracking. By separating the state changes from the actuators that realize those changes, Dream2Flow overcomes the embodiment gap and enables zero-shot guidance from pre-trained video models to manipulate objects of diverse categories-including rigid, articulated, deformable, and granular. Through trajectory optimization or reinforcement learning, Dream2Flow converts reconstructed 3D object flow into executable low-level commands without task-specific demonstrations. Simulation and real-world experiments highlight 3D object flow as a general and scalable interface for adapting video generation models to open-world robotic manipulation. Videos and visualizations are available at https://dream2flow.github.io/.
UAD: Unsupervised Affordance Distillation for Generalization in Robotic Manipulation
Jun 10, 2025Understanding fine-grained object affordances is imperative for robots to manipulate objects in unstructured environments given open-ended task instructions. However, existing methods of visual affordance predictions often rely on manually annotated data or conditions only on a predefined set of tasks. We introduce UAD (Unsupervised Affordance Distillation), a method for distilling affordance knowledge from foundation models into a task-conditioned affordance model without any manual annotations. By leveraging the complementary strengths of large vision models and vision-language models, UAD automatically annotates a large-scale dataset with detailed $<$instruction, visual affordance$>$ pairs. Training only a lightweight task-conditioned decoder atop frozen features, UAD exhibits notable generalization to in-the-wild robotic scenes and to various human activities, despite only being trained on rendered objects in simulation. Using affordance provided by UAD as the observation space, we show an imitation learning policy that demonstrates promising generalization to unseen object instances, object categories, and even variations in task instructions after training on as few as 10 demonstrations. Project website: https://unsup-affordance.github.io/
Learning Compositional Behaviors from Demonstration and Language
May 28, 2025
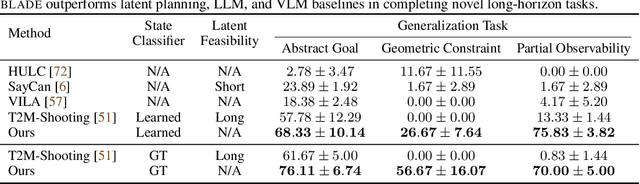
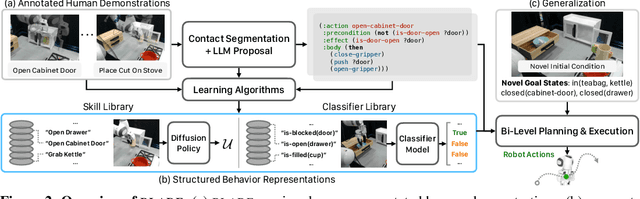

We introduce Behavior from Language and Demonstration (BLADE), a framework for long-horizon robotic manipulation by integrating imitation learning and model-based planning. BLADE leverages language-annotated demonstrations, extracts abstract action knowledge from large language models (LLMs), and constructs a library of structured, high-level action representations. These representations include preconditions and effects grounded in visual perception for each high-level action, along with corresponding controllers implemented as neural network-based policies. BLADE can recover such structured representations automatically, without manually labeled states or symbolic definitions. BLADE shows significant capabilities in generalizing to novel situations, including novel initial states, external state perturbations, and novel goals. We validate the effectiveness of our approach both in simulation and on real robots with a diverse set of objects with articulated parts, partial observability, and geometric constraints.
Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models
Apr 17, 2025Learning to perform manipulation tasks from human videos is a promising approach for teaching robots. However, many manipulation tasks require changing control parameters during task execution, such as force, which visual data alone cannot capture. In this work, we leverage sensing devices such as armbands that measure human muscle activities and microphones that record sound, to capture the details in the human manipulation process, and enable robots to extract task plans and control parameters to perform the same task. To achieve this, we introduce Chain-of-Modality (CoM), a prompting strategy that enables Vision Language Models to reason about multimodal human demonstration data -- videos coupled with muscle or audio signals. By progressively integrating information from each modality, CoM refines a task plan and generates detailed control parameters, enabling robots to perform manipulation tasks based on a single multimodal human video prompt. Our experiments show that CoM delivers a threefold improvement in accuracy for extracting task plans and control parameters compared to baselines, with strong generalization to new task setups and objects in real-world robot experiments. Videos and code are available at https://chain-of-modality.github.io
BEHAVIOR Robot Suite: Streamlining Real-World Whole-Body Manipulation for Everyday Household Activities
Mar 07, 2025Real-world household tasks present significant challenges for mobile manipulation robots. An analysis of existing robotics benchmarks reveals that successful task performance hinges on three key whole-body control capabilities: bimanual coordination, stable and precise navigation, and extensive end-effector reachability. Achieving these capabilities requires careful hardware design, but the resulting system complexity further complicates visuomotor policy learning. To address these challenges, we introduce the BEHAVIOR Robot Suite (BRS), a comprehensive framework for whole-body manipulation in diverse household tasks. Built on a bimanual, wheeled robot with a 4-DoF torso, BRS integrates a cost-effective whole-body teleoperation interface for data collection and a novel algorithm for learning whole-body visuomotor policies. We evaluate BRS on five challenging household tasks that not only emphasize the three core capabilities but also introduce additional complexities, such as long-range navigation, interaction with articulated and deformable objects, and manipulation in confined spaces. We believe that BRS's integrated robotic embodiment, data collection interface, and learning framework mark a significant step toward enabling real-world whole-body manipulation for everyday household tasks. BRS is open-sourced at https://behavior-robot-suite.github.io/