 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlueprint Separable Residual Network for Efficient Image Super-Resolution
May 12, 2022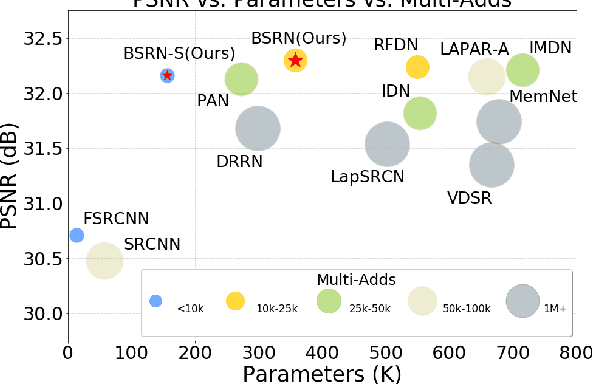



Recent advances in single image super-resolution (SISR) have achieved extraordinary performance, but the computational cost is too heavy to apply in edge devices. To alleviate this problem, many novel and effective solutions have been proposed. Convolutional neural network (CNN) with the attention mechanism has attracted increasing attention due to its efficiency and effectiveness. However, there is still redundancy in the convolution operation. In this paper, we propose Blueprint Separable Residual Network (BSRN) containing two efficient designs. One is the usage of blueprint separable convolution (BSConv), which takes place of the redundant convolution operation. The other is to enhance the model ability by introducing more effective attention modules. The experimental results show that BSRN achieves state-of-the-art performance among existing efficient SR methods. Moreover, a smaller variant of our model BSRN-S won the first place in model complexity track of NTIRE 2022 Efficient SR Challenge. The code is available at https://github.com/xiaom233/BSRN.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
RepSR: Training Efficient VGG-style Super-Resolution Networks with Structural Re-Parameterization and Batch Normalization
May 11, 2022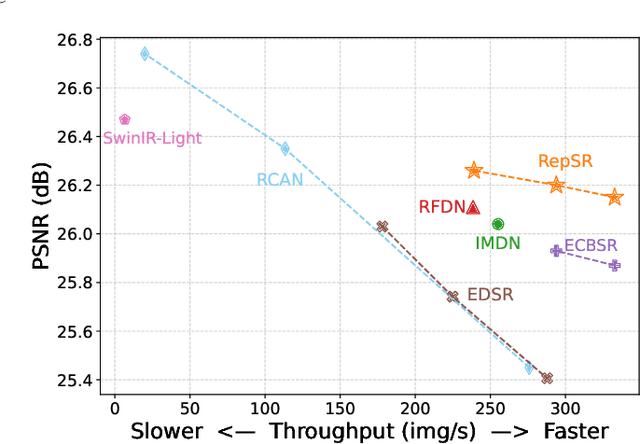
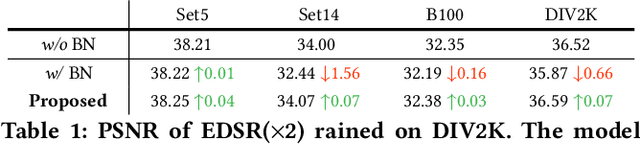
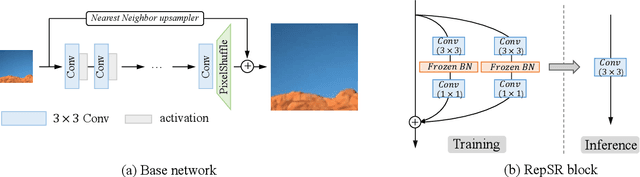
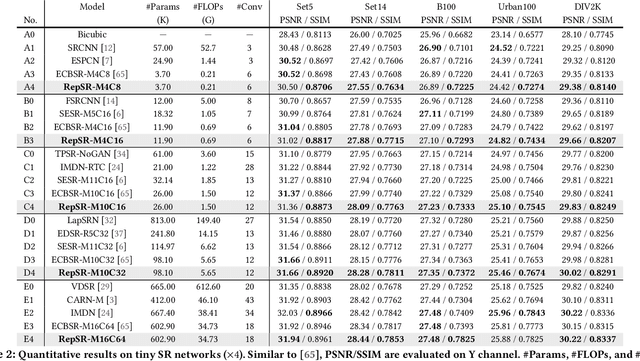
This paper explores training efficient VGG-style super-resolution (SR) networks with the structural re-parameterization technique. The general pipeline of re-parameterization is to train networks with multi-branch topology first, and then merge them into standard 3x3 convolutions for efficient inference. In this work, we revisit those primary designs and investigate essential components for re-parameterizing SR networks. First of all, we find that batch normalization (BN) is important to bring training non-linearity and improve the final performance. However, BN is typically ignored in SR, as it usually degrades the performance and introduces unpleasant artifacts. We carefully analyze the cause of BN issue and then propose a straightforward yet effective solution. In particular, we first train SR networks with mini-batch statistics as usual, and then switch to using population statistics at the later training period. While we have successfully re-introduced BN into SR, we further design a new re-parameterizable block tailored for SR, namely RepSR. It consists of a clean residual path and two expand-and-squeeze convolution paths with the modified BN. Extensive experiments demonstrate that our simple RepSR is capable of achieving superior performance to previous SR re-parameterization methods among different model sizes. In addition, our RepSR can achieve a better trade-off between performance and actual running time (throughput) than previous SR methods. Codes will be available at https://github.com/TencentARC/RepSR.
Metric Learning based Interactive Modulation for Real-World Super-Resolution
May 10, 2022
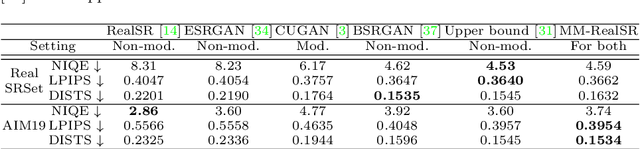

Interactive image restoration aims to restore images by adjusting several controlling coefficients, which determine the restoration strength. Existing methods are restricted in learning the controllable functions under the supervision of known degradation types and levels. They usually suffer from a severe performance drop when the real degradation is different from their assumptions. Such a limitation is due to the complexity of real-world degradations, which can not provide explicit supervision to the interactive modulation during training. However, how to realize the interactive modulation in real-world super-resolution has not yet been studied. In this work, we present a Metric Learning based Interactive Modulation for Real-World Super-Resolution (MM-RealSR). Specifically, we propose an unsupervised degradation estimation strategy to estimate the degradation level in real-world scenarios. Instead of using known degradation levels as explicit supervision to the interactive mechanism, we propose a metric learning strategy to map the unquantifiable degradation levels in real-world scenarios to a metric space, which is trained in an unsupervised manner. Moreover, we introduce an anchor point strategy in the metric learning process to normalize the distribution of metric space. Extensive experiments demonstrate that the proposed MM-RealSR achieves excellent modulation and restoration performance in real-world super-resolution. Codes are available at https://github.com/TencentARC/MM-RealSR.
A Closer Look at Blind Super-Resolution: Degradation Models, Baselines, and Performance Upper Bounds
May 10, 2022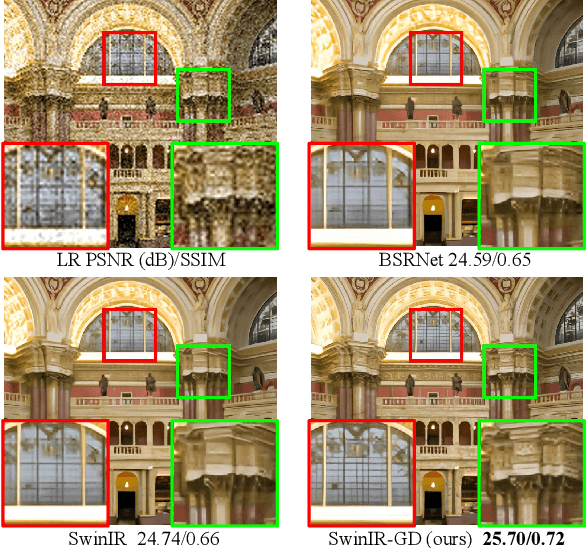

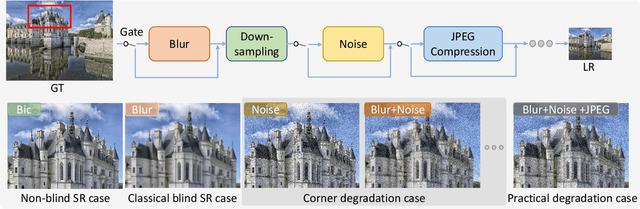
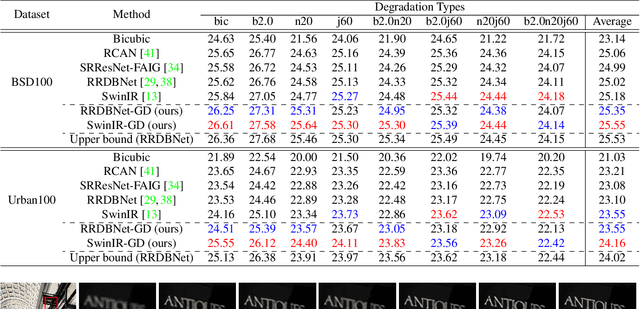
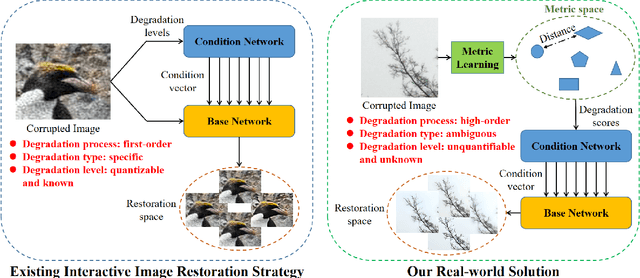
Degradation models play an important role in Blind super-resolution (SR). The classical degradation model, which mainly involves blur degradation, is too simple to simulate real-world scenarios. The recently proposed practical degradation model includes a full spectrum of degradation types, but only considers complex cases that use all degradation types in the degradation process, while ignoring many important corner cases that are common in the real world. To address this problem, we propose a unified gated degradation model to generate a broad set of degradation cases using a random gate controller. Based on the gated degradation model, we propose simple baseline networks that can effectively handle non-blind, classical, practical degradation cases as well as many other corner cases. To fairly evaluate the performance of our baseline networks against state-of-the-art methods and understand their limits, we introduce the performance upper bound of an SR network for every degradation type. Our empirical analysis shows that with the unified gated degradation model, the proposed baselines can achieve much better performance than existing methods in quantitative and qualitative results, which are close to the performance upper bounds.
VFHQ: A High-Quality Dataset and Benchmark for Video Face Super-Resolution
May 06, 2022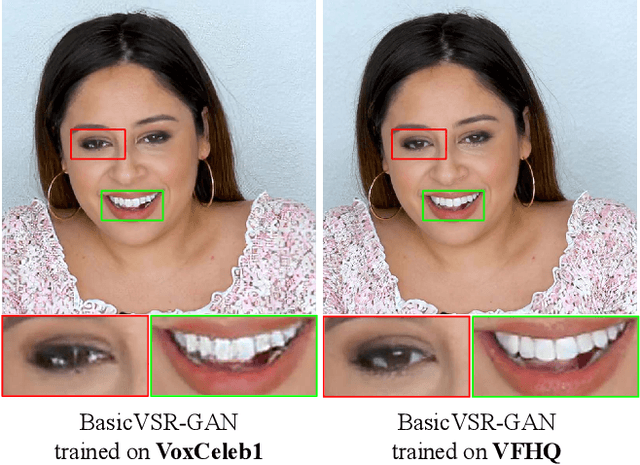
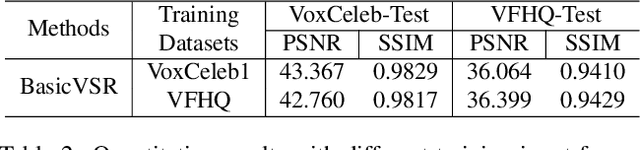

Most of the existing video face super-resolution (VFSR) methods are trained and evaluated on VoxCeleb1, which is designed specifically for speaker identification and the frames in this dataset are of low quality. As a consequence, the VFSR models trained on this dataset can not output visual-pleasing results. In this paper, we develop an automatic and scalable pipeline to collect a high-quality video face dataset (VFHQ), which contains over $16,000$ high-fidelity clips of diverse interview scenarios. To verify the necessity of VFHQ, we further conduct experiments and demonstrate that VFSR models trained on our VFHQ dataset can generate results with sharper edges and finer textures than those trained on VoxCeleb1. In addition, we show that the temporal information plays a pivotal role in eliminating video consistency issues as well as further improving visual performance. Based on VFHQ, by analyzing the benchmarking study of several state-of-the-art algorithms under bicubic and blind settings. See our project page: https://liangbinxie.github.io/projects/vfhq
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022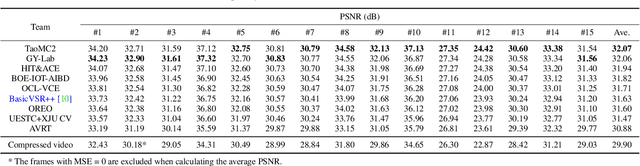
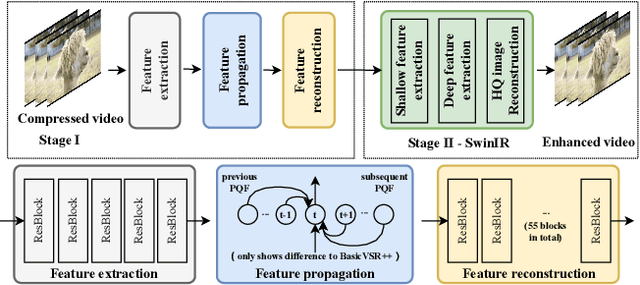
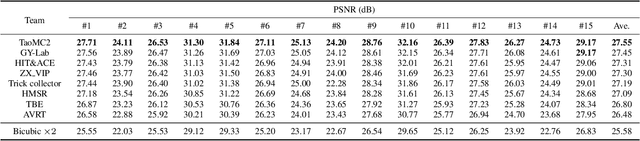

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
Mar 14, 2022
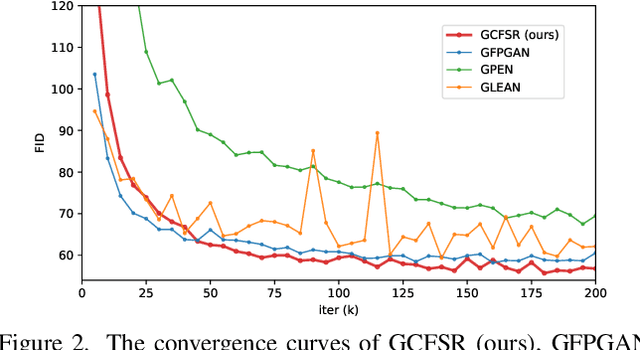

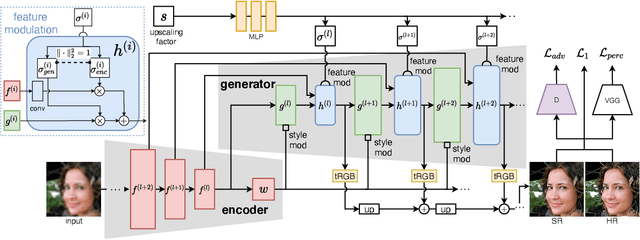
Face image super resolution (face hallucination) usually relies on facial priors to restore realistic details and preserve identity information. Recent advances can achieve impressive results with the help of GAN prior. They either design complicated modules to modify the fixed GAN prior or adopt complex training strategies to finetune the generator. In this work, we propose a generative and controllable face SR framework, called GCFSR, which can reconstruct images with faithful identity information without any additional priors. Generally, GCFSR has an encoder-generator architecture. Two modules called style modulation and feature modulation are designed for the multi-factor SR task. The style modulation aims to generate realistic face details and the feature modulation dynamically fuses the multi-level encoded features and the generated ones conditioned on the upscaling factor. The simple and elegant architecture can be trained from scratch in an end-to-end manner. For small upscaling factors (<=8), GCFSR can produce surprisingly good results with only adversarial loss. After adding L1 and perceptual losses, GCFSR can outperform state-of-the-art methods for large upscaling factors (16, 32, 64). During the test phase, we can modulate the generative strength via feature modulation by changing the conditional upscaling factor continuously to achieve various generative effects.
Hierarchical Aerial Computing for Internet of Things via Cooperation of HAPs and UAVs
Feb 12, 2022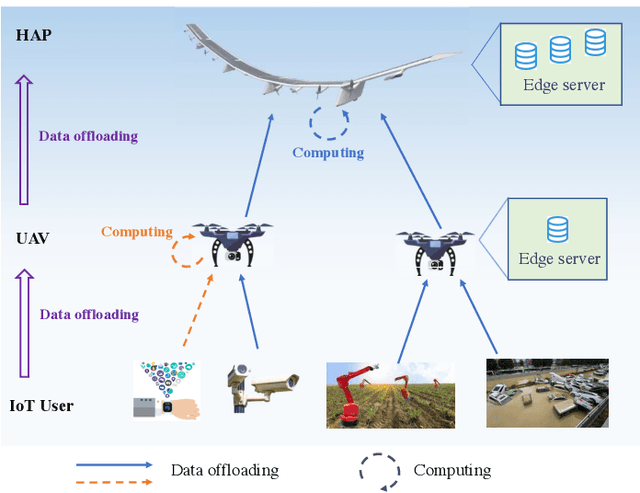
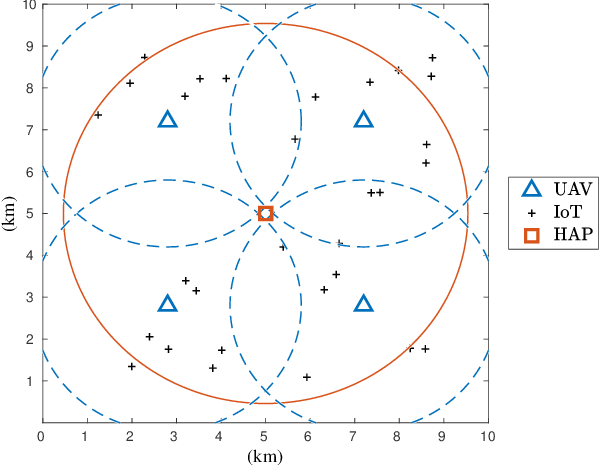
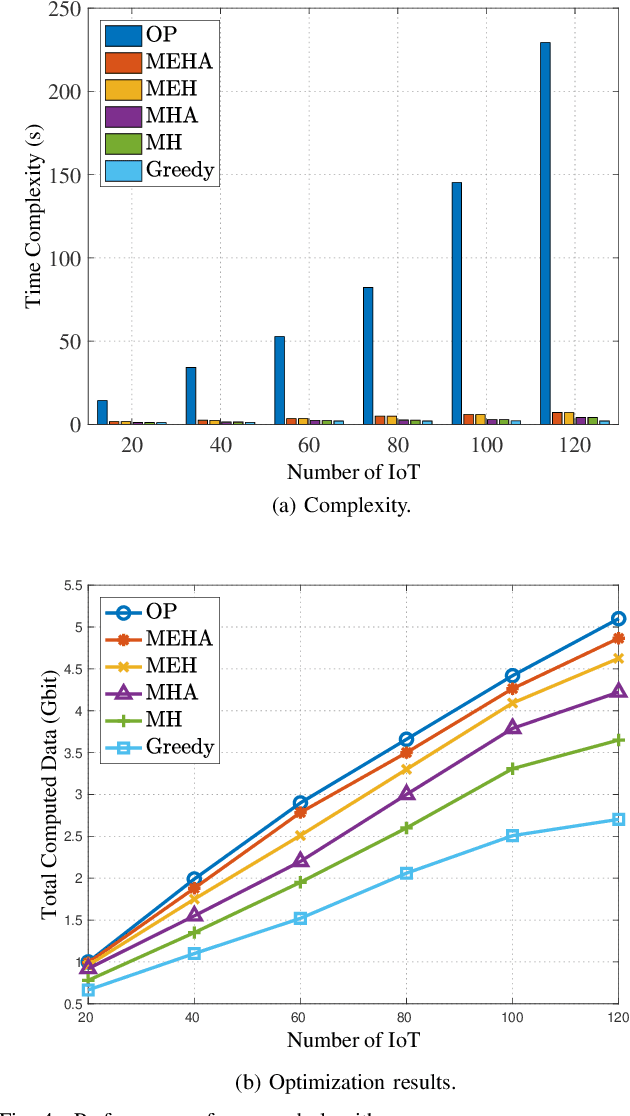
With the explosive increment of computation requirements, the multi-access edge computing (MEC) paradigm appears as an effective mechanism. Besides, as for the Internet of Things (IoT) in disasters or remote areas requiring MEC services, unmanned aerial vehicles (UAVs) and high altitude platforms (HAPs) are available to provide aerial computing services for these IoT devices. In this paper, we develop the hierarchical aerial computing framework composed of HAPs and UAVs, to provide MEC services for various IoT applications. In particular, the problem is formulated to maximize the total IoT data computed by the aerial MEC platforms, restricted by the delay requirement of IoT and multiple resource constraints of UAVs and HAPs, which is an integer programming problem and intractable to solve. Due to the prohibitive complexity of exhaustive search, we handle the problem by presenting the matching game theory based algorithm to deal with the offloading decisions from IoT devices to UAVs, as well as a heuristic algorithm for the offloading decisions between UAVs and HAPs. The external effect affected by interplay of different IoT devices in the matching is tackled by the externality elimination mechanism. Besides, an adjustment algorithm is also proposed to make the best of aerial resources. The complexity of proposed algorithms is analyzed and extensive simulation results verify the efficiency of the proposed algorithms, and the system performances are also analyzed by the numerical results.
Unmanned Aerial Vehicle Swarm-Enabled Edge Computing: Potentials, Promising Technologies, and Challenges
Jan 21, 2022
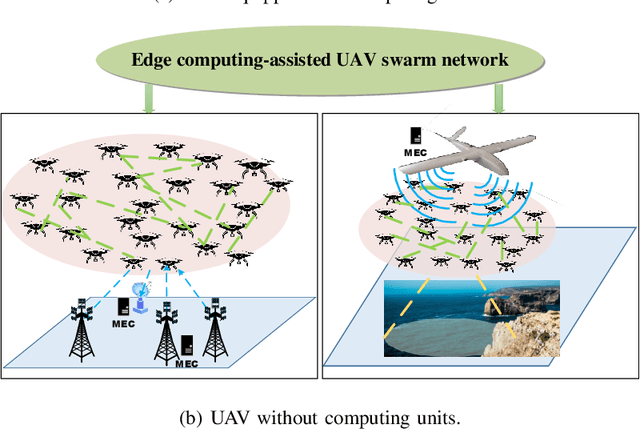
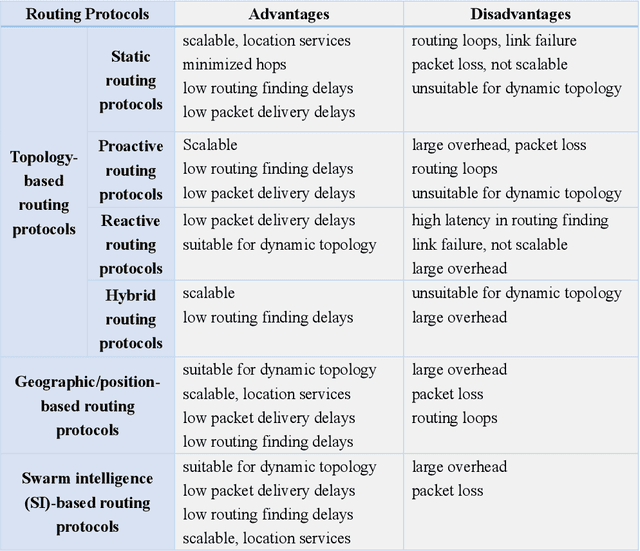
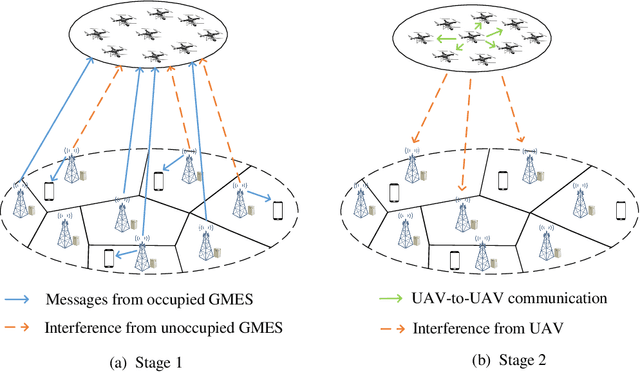
Unmanned aerial vehicle (UAV) swarm enabled edge computing is envisioned to be promising in the sixth generation wireless communication networks due to their wide application sensories and flexible deployment. However, most of the existing works focus on edge computing enabled by a single or a small scale UAVs, which are very different from UAV swarm-enabled edge computing. In order to facilitate the practical applications of UAV swarm-enabled edge computing, the state of the art research is presented in this article. The potential applications, architectures and implementation considerations are illustrated. Moreover, the promising enabling technologies for UAV swarm-enabled edge computing are discussed. Furthermore, we outline challenges and open issues in order to shed light on the future research directions.