 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Dec 23, 2024



With the rapid growth in the scale and complexity of large language models (LLMs), the costs of training and inference have risen substantially. Model compression has emerged as a mainstream solution to reduce memory usage and computational overhead. This paper presents Group Quantization and Sparse Acceleration (\textbf{GQSA}), a novel compression technique tailored for LLMs. Traditional methods typically focus exclusively on either quantization or sparsification, but relying on a single strategy often results in significant performance loss at high compression rates. In contrast, GQSA integrates quantization and sparsification in a tightly coupled manner, leveraging GPU-friendly structured group sparsity and quantization for efficient acceleration. The proposed method consists of three key steps. First, GQSA applies group structured pruning to adhere to GPU-friendly sparse pattern constraints. Second, a two-stage sparsity-aware training process is employed to maximize performance retention after compression. Finally, the framework adopts the Block Sparse Row (BSR) format to enable practical deployment and efficient execution. Experimental results on the LLaMA model family show that GQSA achieves an excellent balance between model speed and accuracy. Furthermore, on the latest LLaMA-3 and LLaMA-3.1 models, GQSA outperforms existing LLM compression techniques significantly.
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Aug 13, 2024



Stable Diffusion Models (SDMs) have shown remarkable proficiency in image synthesis. However, their broad application is impeded by their large model sizes and intensive computational requirements, which typically require expensive cloud servers for deployment. On the flip side, while there are many compact models tailored for edge devices that can reduce these demands, they often compromise on semantic integrity and visual quality when compared to full-sized SDMs. To bridge this gap, we introduce Hybrid SD, an innovative, training-free SDMs inference framework designed for edge-cloud collaborative inference. Hybrid SD distributes the early steps of the diffusion process to the large models deployed on cloud servers, enhancing semantic planning. Furthermore, small efficient models deployed on edge devices can be integrated for refining visual details in the later stages. Acknowledging the diversity of edge devices with differing computational and storage capacities, we employ structural pruning to the SDMs U-Net and train a lightweight VAE. Empirical evaluations demonstrate that our compressed models achieve state-of-the-art parameter efficiency (225.8M) on edge devices with competitive image quality. Additionally, Hybrid SD reduces the cloud cost by 66% with edge-cloud collaborative inference.
FoldGPT: Simple and Effective Large Language Model Compression Scheme
Jul 01, 2024The demand for deploying large language models(LLMs) on mobile devices continues to increase, driven by escalating data security concerns and cloud costs. However, network bandwidth and memory limitations pose challenges for deploying billion-level models on mobile devices. In this study, we investigate the outputs of different layers across various scales of LLMs and found that the outputs of most layers exhibit significant similarity. Moreover, this similarity becomes more pronounced as the model size increases, indicating substantial redundancy in the depth direction of the LLMs. Based on this observation, we propose an efficient model volume compression strategy, termed FoldGPT, which combines block removal and block parameter sharing.This strategy consists of three parts: (1) Based on the learnable gating parameters, we determine the block importance ranking while modeling the coupling effect between blocks. Then we delete some redundant layers based on the given removal rate. (2) For the retained blocks, we apply a specially designed group parameter sharing strategy, where blocks within the same group share identical weights, significantly compressing the number of parameters and slightly reducing latency overhead. (3) After sharing these Blocks, we "cure" the mismatch caused by sparsity with a minor amount of fine-tuning and introduce a tail-layer distillation strategy to improve the performance. Experiments demonstrate that FoldGPT outperforms previous state-of-the-art(SOTA) methods in efficient model compression, demonstrating the feasibility of achieving model lightweighting through straightforward block removal and parameter sharing.
PatchScaler: An Efficient Patch-independent Diffusion Model for Super-Resolution
May 27, 2024



Diffusion models significantly improve the quality of super-resolved images with their impressive content generation capabilities. However, the huge computational costs limit the applications of these methods.Recent efforts have explored reasonable inference acceleration to reduce the number of sampling steps, but the computational cost remains high as each step is performed on the entire image.This paper introduces PatchScaler, a patch-independent diffusion-based single image super-resolution (SR) method, designed to enhance the efficiency of the inference process.The proposed method is motivated by the observation that not all the image patches within an image need the same sampling steps for reconstructing high-resolution images.Based on this observation, we thus develop a Patch-adaptive Group Sampling (PGS) to divide feature patches into different groups according to the patch-level reconstruction difficulty and dynamically assign an appropriate sampling configuration for each group so that the inference speed can be better accelerated.In addition, to improve the denoising ability at each step of the sampling, we develop a texture prompt to guide the estimations of the diffusion model by retrieving high-quality texture priors from a patch-independent reference texture memory.Experiments show that our PatchScaler achieves favorable performance in both quantitative and qualitative evaluations with fast inference speed.Our code and model are available at \url{https://github.com/yongliuy/PatchScaler}.
UniFL: Improve Stable Diffusion via Unified Feedback Learning
Apr 08, 2024



Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications. However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed. In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models
Mar 04, 2024



Recent advancement in text-to-image models (e.g., Stable Diffusion) and corresponding personalized technologies (e.g., DreamBooth and LoRA) enables individuals to generate high-quality and imaginative images. However, they often suffer from limitations when generating images with resolutions outside of their trained domain. To overcome this limitation, we present the Resolution Adapter (ResAdapter), a domain-consistent adapter designed for diffusion models to generate images with unrestricted resolutions and aspect ratios. Unlike other multi-resolution generation methods that process images of static resolution with complex post-process operations, ResAdapter directly generates images with the dynamical resolution. Especially, after learning a deep understanding of pure resolution priors, ResAdapter trained on the general dataset, generates resolution-free images with personalized diffusion models while preserving their original style domain. Comprehensive experiments demonstrate that ResAdapter with only 0.5M can process images with flexible resolutions for arbitrary diffusion models. More extended experiments demonstrate that ResAdapter is compatible with other modules (e.g., ControlNet, IP-Adapter and LCM-LoRA) for image generation across a broad range of resolutions, and can be integrated into other multi-resolution model (e.g., ElasticDiffusion) for efficiently generating higher-resolution images. Project link is https://res-adapter.github.io
SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity
Oct 30, 2023



To address the challenge of increasing network size, researchers have developed sparse models through network pruning. However, maintaining model accuracy while achieving significant speedups on general computing devices remains an open problem. In this paper, we present a novel mobile inference acceleration framework SparseByteNN, which leverages fine-grained kernel sparsity to achieve real-time execution as well as high accuracy. Our framework consists of two parts: (a) A fine-grained kernel sparsity schema with a sparsity granularity between structured pruning and unstructured pruning. It designs multiple sparse patterns for different operators. Combined with our proposed whole network rearrangement strategy, the schema achieves a high compression rate and high precision at the same time. (b) Inference engine co-optimized with the sparse pattern. The conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet-v1 outperform strong dense baselines on the efficiency-accuracy curve. Experimental results on Qualcomm 855 show that for 30% sparse MobileNet-v1, SparseByteNN achieves 1.27x speedup over the dense version and 1.29x speedup over the state-of-the-art sparse inference engine MNN with a slight accuracy drop of 0.224%. The source code of SparseByteNN will be available at https://github.com/lswzjuer/SparseByteNN
Unfolding Once is Enough: A Deployment-Friendly Transformer Unit for Super-Resolution
Aug 05, 2023



Recent years have witnessed a few attempts of vision transformers for single image super-resolution (SISR). Since the high resolution of intermediate features in SISR models increases memory and computational requirements, efficient SISR transformers are more favored. Based on some popular transformer backbone, many methods have explored reasonable schemes to reduce the computational complexity of the self-attention module while achieving impressive performance. However, these methods only focus on the performance on the training platform (e.g., Pytorch/Tensorflow) without further optimization for the deployment platform (e.g., TensorRT). Therefore, they inevitably contain some redundant operators, posing challenges for subsequent deployment in real-world applications. In this paper, we propose a deployment-friendly transformer unit, namely UFONE (i.e., UnFolding ONce is Enough), to alleviate these problems. In each UFONE, we introduce an Inner-patch Transformer Layer (ITL) to efficiently reconstruct the local structural information from patches and a Spatial-Aware Layer (SAL) to exploit the long-range dependencies between patches. Based on UFONE, we propose a Deployment-friendly Inner-patch Transformer Network (DITN) for the SISR task, which can achieve favorable performance with low latency and memory usage on both training and deployment platforms. Furthermore, to further boost the deployment efficiency of the proposed DITN on TensorRT, we also provide an efficient substitution for layer normalization and propose a fusion optimization strategy for specific operators. Extensive experiments show that our models can achieve competitive results in terms of qualitative and quantitative performance with high deployment efficiency. Code is available at \url{https://github.com/yongliuy/DITN}.
Boosting Video Super Resolution with Patch-Based Temporal Redundancy Optimization
Jul 18, 2022

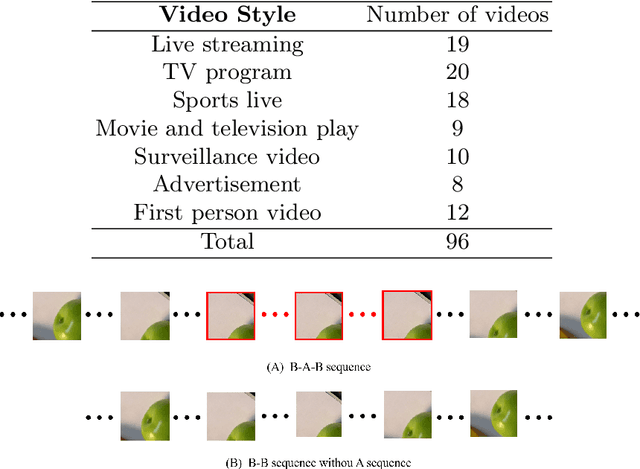

The success of existing video super-resolution (VSR) algorithms stems mainly exploiting the temporal information from the neighboring frames. However, none of these methods have discussed the influence of the temporal redundancy in the patches with stationary objects and background and usually use all the information in the adjacent frames without any discrimination. In this paper, we observe that the temporal redundancy will bring adverse effect to the information propagation,which limits the performance of the most existing VSR methods. Motivated by this observation, we aim to improve existing VSR algorithms by handling the temporal redundancy patches in an optimized manner. We develop two simple yet effective plug and play methods to improve the performance of existing local and non-local propagation-based VSR algorithms on widely-used public videos. For more comprehensive evaluating the robustness and performance of existing VSR algorithms, we also collect a new dataset which contains a variety of public videos as testing set. Extensive evaluations show that the proposed methods can significantly improve the performance of existing VSR methods on the collected videos from wild scenarios while maintain their performance on existing commonly used datasets. The code is available at https://github.com/HYHsimon/Boosted-VSR.