 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurst Image Quality Assessment: A New Benchmark and Unified Framework for Multiple Downstream Tasks
Nov 11, 2025



In recent years, the development of burst imaging technology has improved the capture and processing capabilities of visual data, enabling a wide range of applications. However, the redundancy in burst images leads to the increased storage and transmission demands, as well as reduced efficiency of downstream tasks. To address this, we propose a new task of Burst Image Quality Assessment (BuIQA), to evaluate the task-driven quality of each frame within a burst sequence, providing reasonable cues for burst image selection. Specifically, we establish the first benchmark dataset for BuIQA, consisting of $7,346$ burst sequences with $45,827$ images and $191,572$ annotated quality scores for multiple downstream scenarios. Inspired by the data analysis, a unified BuIQA framework is proposed to achieve an efficient adaption for BuIQA under diverse downstream scenarios. Specifically, a task-driven prompt generation network is developed with heterogeneous knowledge distillation, to learn the priors of the downstream task. Then, the task-aware quality assessment network is introduced to assess the burst image quality based on the task prompt. Extensive experiments across 10 downstream scenarios demonstrate the impressive BuIQA performance of the proposed approach, outperforming the state-of-the-art. Furthermore, it can achieve $0.33$ dB PSNR improvement in the downstream tasks of denoising and super-resolution, by applying our approach to select the high-quality burst frames.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022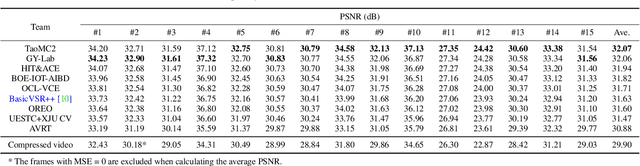
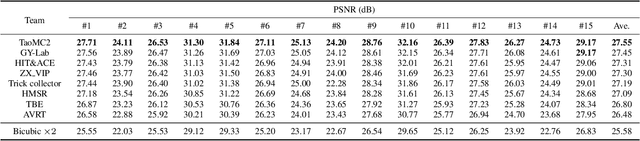

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Progressive Training of A Two-Stage Framework for Video Restoration
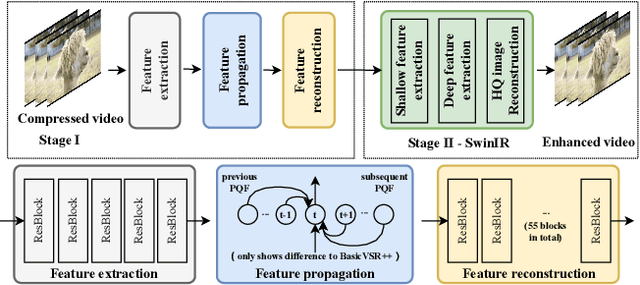
Apr 21, 2022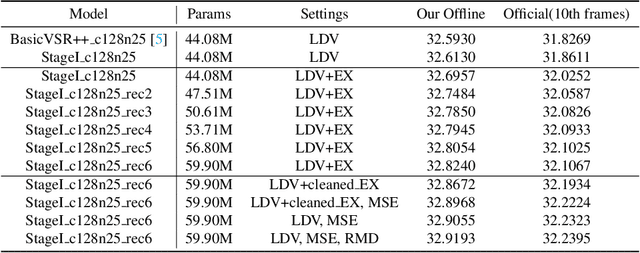
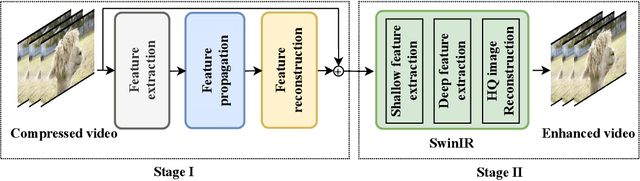
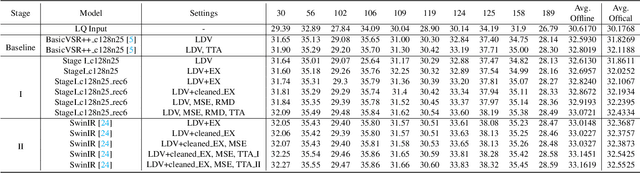
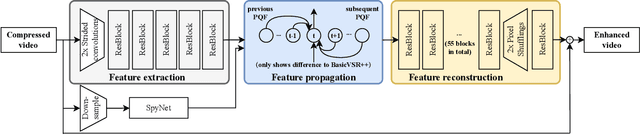
As a widely studied task, video restoration aims to enhance the quality of the videos with multiple potential degradations, such as noises, blurs and compression artifacts. Among video restorations, compressed video quality enhancement and video super-resolution are two of the main tacks with significant values in practical scenarios. Recently, recurrent neural networks and transformers attract increasing research interests in this field, due to their impressive capability in sequence-to-sequence modeling. However, the training of these models is not only costly but also relatively hard to converge, with gradient exploding and vanishing problems. To cope with these problems, we proposed a two-stage framework including a multi-frame recurrent network and a single-frame transformer. Besides, multiple training strategies, such as transfer learning and progressive training, are developed to shorten the training time and improve the model performance. Benefiting from the above technical contributions, our solution wins two champions and a runner-up in the NTIRE 2022 super-resolution and quality enhancement of compressed video challenges.
Joint Learning of Visual-Audio Saliency Prediction and Sound Source Localization on Multi-face Videos
Nov 05, 2021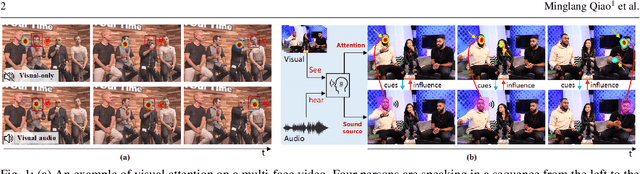
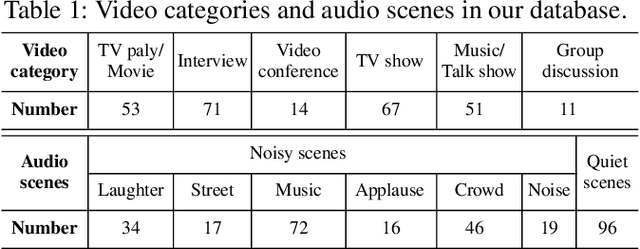

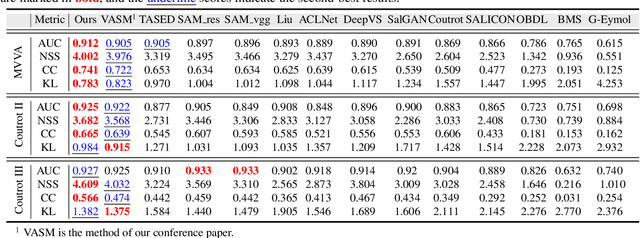
Visual and audio events simultaneously occur and both attract attention. However, most existing saliency prediction works ignore the influence of audio and only consider vision modality. In this paper, we propose a multitask learning method for visual-audio saliency prediction and sound source localization on multi-face video by leveraging visual, audio and face information. Specifically, we first introduce a large-scale database of multi-face video in visual-audio condition (MVVA), containing eye-tracking data and sound source annotations. Using this database, we find that sound influences human attention, and conversly attention offers a cue to determine sound source on multi-face video. Guided by these findings, a visual-audio multi-task network (VAM-Net) is introduced to predict saliency and locate sound source. VAM-Net consists of three branches corresponding to visual, audio and face modalities. Visual branch has a two-stream architecture to capture spatial and temporal information. Face and audio branches encode audio signals and faces, respectively. Finally, a spatio-temporal multi-modal graph (STMG) is constructed to model the interaction among multiple faces. With joint optimization of these branches, the intrinsic correlation of the tasks of saliency prediction and sound source localization is utilized and their performance is boosted by each other. Experiments show that the proposed method outperforms 12 state-of-the-art saliency prediction methods, and achieves competitive results in sound source localization.
Learning to Predict Salient Faces: A Novel Visual-Audio Saliency Model
Mar 29, 2021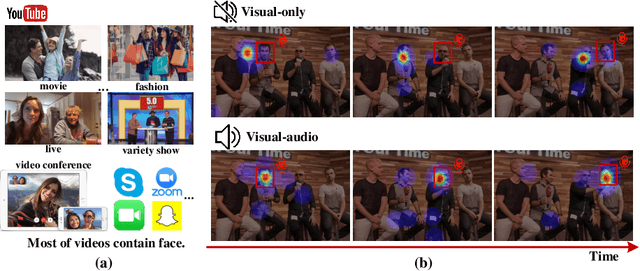
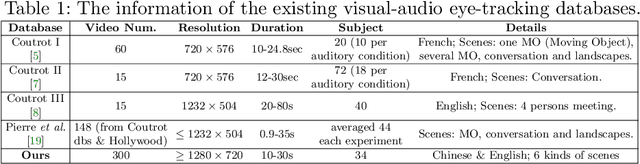
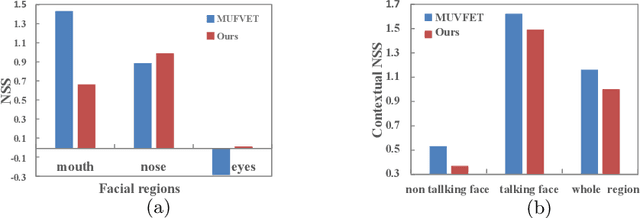
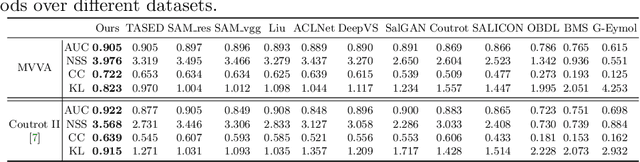
Recently, video streams have occupied a large proportion of Internet traffic, most of which contain human faces. Hence, it is necessary to predict saliency on multiple-face videos, which can provide attention cues for many content based applications. However, most of multiple-face saliency prediction works only consider visual information and ignore audio, which is not consistent with the naturalistic scenarios. Several behavioral studies have established that sound influences human attention, especially during the speech turn-taking in multiple-face videos. In this paper, we thoroughly investigate such influences by establishing a large-scale eye-tracking database of Multiple-face Video in Visual-Audio condition (MVVA). Inspired by the findings of our investigation, we propose a novel multi-modal video saliency model consisting of three branches: visual, audio and face. The visual branch takes the RGB frames as the input and encodes them into visual feature maps. The audio and face branches encode the audio signal and multiple cropped faces, respectively. A fusion module is introduced to integrate the information from three modalities, and to generate the final saliency map. Experimental results show that the proposed method outperforms 11 state-of-the-art saliency prediction works. It performs closer to human multi-modal attention.
Predicting Head Movement in Panoramic Video: A Deep Reinforcement Learning Approach
Sep 21, 2018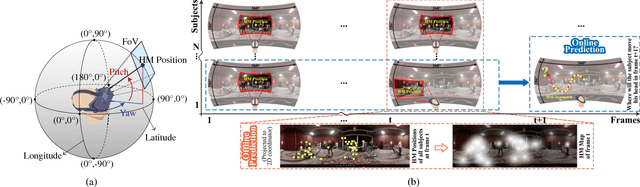

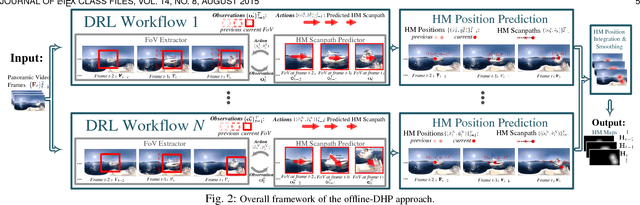
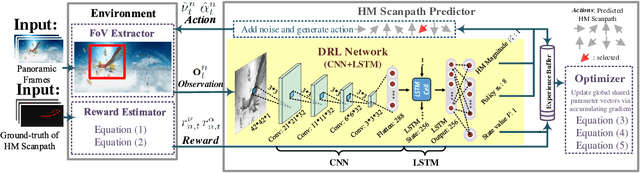
Panoramic video provides immersive and interactive experience by enabling humans to control the field of view (FoV) through head movement (HM). Thus, HM plays a key role in modeling human attention on panoramic video. This paper establishes a database collecting subjects' HM in panoramic video sequences. From this database, we find that the HM data are highly consistent across subjects. Furthermore, we find that deep reinforcement learning (DRL) can be applied to predict HM positions, via maximizing the reward of imitating human HM scanpaths through the agent's actions. Based on our findings, we propose a DRL-based HM prediction (DHP) approach with offline and online versions, called offline-DHP and online-DHP. In offline-DHP, multiple DRL workflows are run to determine potential HM positions at each panoramic frame. Then, a heat map of the potential HM positions, named the HM map, is generated as the output of offline-DHP. In online-DHP, the next HM position of one subject is estimated given the currently observed HM position, which is achieved by developing a DRL algorithm upon the learned offline-DHP model. Finally, the experiments validate that our approach is effective in both offline and online prediction of HM positions for panoramic video, and that the learned offline-DHP model can improve the performance of online-DHP.
* 15 pages, 10 figures, published on TPAMI 2018