 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQ-Jarvis: Retrieval-Augmented Video Restoration Agent with Sharp Vision and Fast Thought
Mar 24, 2026Video restoration in real-world scenarios is challenged by heterogeneous degradations, where static architectures and fixed inference pipelines often fail to generalize. Recent agent-based approaches offer dynamic decision making, yet existing video restoration agents remain limited by insufficient quality perception and inefficient search strategies. We propose VQ-Jarvis, a retrieval-augmented, all-in-one intelligent video restoration agent with sharper vision and faster thought. VQ-Jarvis is designed to accurately perceive degradations and subtle differences among paired restoration results, while efficiently discovering optimal restoration trajectories. To enable sharp vision, we construct VSR-Compare, the first large-scale video paired enhancement dataset with 20K comparison pairs covering 7 degradation types, 11 enhancement operators, and diverse content domains. Based on this dataset, we train a multiple operator judge model and a degradation perception model to guide agent decisions. To achieve fast thought, we introduce a hierarchical operator scheduling strategy that adapts to video difficulty: for easy cases, optimal restoration trajectories are retrieved in a one-step manner from a retrieval-augmented generation (RAG) library; for harder cases, a step-by-step greedy search is performed to balance efficiency and accuracy. Extensive experiments demonstrate that VQ-Jarvis consistently outperforms existing methods on complex degraded videos.
OARS: Process-Aware Online Alignment for Generative Real-World Image Super-Resolution
Mar 13, 2026Aligning generative real-world image super-resolution models with human visual preference is challenging due to the perception--fidelity trade-off and diverse, unknown degradations. Prior approaches rely on offline preference optimization and static metric aggregation, which are often non-interpretable and prone to pseudo-diversity under strong conditioning. We propose OARS, a process-aware online alignment framework built on COMPASS, a MLLM-based reward that evaluates the LR to SR transition by jointly modeling fidelity preservation and perceptual gain with an input-quality-adaptive trade-off. To train COMPASS, we curate COMPASS-20K spanning synthetic and real degradations, and introduce a three-stage perceptual annotation pipeline that yields calibrated, fine-grained training labels. Guided by COMPASS, OARS performs progressive online alignment from cold-start flow matching to full-reference and finally reference-free RL via shallow LoRA optimization for on-policy exploration. Extensive experiments and user studies demonstrate consistent perceptual improvements while maintaining fidelity, achieving state-of-the-art performance on Real-ISR benchmarks.
Breaking the Multi-Enhancement Bottleneck: Domain-Consistent Quality Enhancement for Compressed Images
Jun 17, 2025Quality enhancement methods have been widely integrated into visual communication pipelines to mitigate artifacts in compressed images. Ideally, these quality enhancement methods should perform robustly when applied to images that have already undergone prior enhancement during transmission. We refer to this scenario as multi-enhancement, which generalizes the well-known multi-generation scenario of image compression. Unfortunately, current quality enhancement methods suffer from severe degradation when applied in multi-enhancement. To address this challenge, we propose a novel adaptation method that transforms existing quality enhancement models into domain-consistent ones. Specifically, our method enhances a low-quality compressed image into a high-quality image within the natural domain during the first enhancement, and ensures that subsequent enhancements preserve this quality without further degradation. Extensive experiments validate the effectiveness of our method and show that various existing models can be successfully adapted to maintain both fidelity and perceptual quality in multi-enhancement scenarios.
MarsSQE: Stereo Quality Enhancement for Martian Images Using Bi-level Cross-view Attention
Dec 30, 2024



Stereo images captured by Mars rovers are transmitted after lossy compression due to the limited bandwidth between Mars and Earth. Unfortunately, this process results in undesirable compression artifacts. In this paper, we present a novel stereo quality enhancement approach for Martian images, named MarsSQE. First, we establish the first dataset of stereo Martian images. Through extensive analysis of this dataset, we observe that cross-view correlations in Martian images are notably high. Leveraging this insight, we design a bi-level cross-view attention-based quality enhancement network that fully exploits these inherent cross-view correlations. Specifically, our network integrates pixel-level attention for precise matching and patch-level attention for broader contextual information. Experimental results demonstrate the effectiveness of our MarsSQE approach.
MarsQE: Semantic-Informed Quality Enhancement for Compressed Martian Image
Apr 15, 2024Lossy image compression is essential for Mars exploration missions, due to the limited bandwidth between Earth and Mars. However, the compression may introduce visual artifacts that complicate the geological analysis of the Martian surface. Existing quality enhancement approaches, primarily designed for Earth images, fall short for Martian images due to a lack of consideration for the unique Martian semantics. In response to this challenge, we conduct an in-depth analysis of Martian images, yielding two key insights based on semantics: the presence of texture similarities and the compact nature of texture representations in Martian images. Inspired by these findings, we introduce MarsQE, an innovative, semantic-informed, two-phase quality enhancement approach specifically designed for Martian images. The first phase involves the semantic-based matching of texture-similar reference images, and the second phase enhances image quality by transferring texture patterns from these reference images to the compressed image. We also develop a post-enhancement network to further reduce compression artifacts and achieve superior compression quality. Our extensive experiments demonstrate that MarsQE significantly outperforms existing approaches for Earth images, establishing a new benchmark for the quality enhancement on Martian images.
Enhancing Quality of Compressed Images by Mitigating Enhancement Bias Towards Compression Domain
Mar 10, 2024Existing quality enhancement methods for compressed images focus on aligning the enhancement domain with the raw domain to yield realistic images. However, these methods exhibit a pervasive enhancement bias towards the compression domain, inadvertently regarding it as more realistic than the raw domain. This bias makes enhanced images closely resemble their compressed counterparts, thus degrading their perceptual quality. In this paper, we propose a simple yet effective method to mitigate this bias and enhance the quality of compressed images. Our method employs a conditional discriminator with the compressed image as a key condition, and then incorporates a domain-divergence regularization to actively distance the enhancement domain from the compression domain. Through this dual strategy, our method enables the discrimination against the compression domain, and brings the enhancement domain closer to the raw domain. Comprehensive quality evaluations confirm the superiority of our method over other state-of-the-art methods without incurring inference overheads.
DAQE: Enhancing the Quality of Compressed Images by Finding the Secret of Defocus
Nov 20, 2022



Image defocus is inherent in the physics of image formation caused by the optical aberration of lenses, providing plentiful information on image quality. Unfortunately, the existing quality enhancement approaches for compressed images neglect the inherent characteristic of defocus, resulting in inferior performance. This paper finds that in compressed images, the significantly defocused regions are with better compression quality and two regions with different defocus values possess diverse texture patterns. These findings motivate our defocus-aware quality enhancement (DAQE) approach. Specifically, we propose a novel dynamic region-based deep learning architecture of the DAQE approach, which considers the region-wise defocus difference of compressed images in two aspects. (1) The DAQE approach employs fewer computational resources to enhance the quality of significantly defocused regions, while more resources on enhancing the quality of other regions; (2) The DAQE approach learns to separately enhance diverse texture patterns for the regions with different defocus values, such that texture-wise one-on-one enhancement can be achieved. Extensive experiments validate the superiority of our DAQE approach in terms of quality enhancement and resource-saving, compared with other state-of-the-art approaches.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022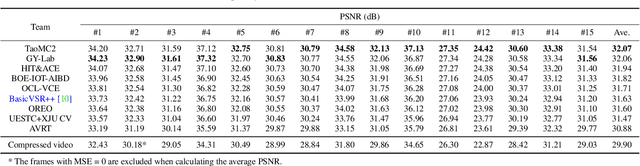
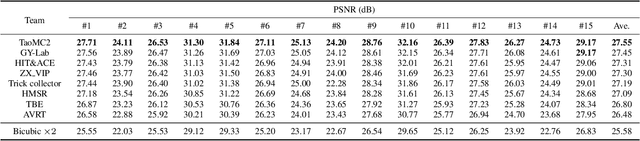

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Progressive Training of A Two-Stage Framework for Video Restoration
Apr 21, 2022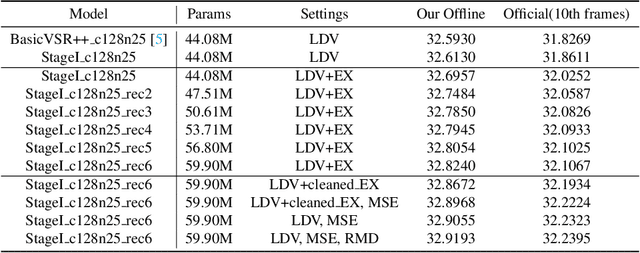
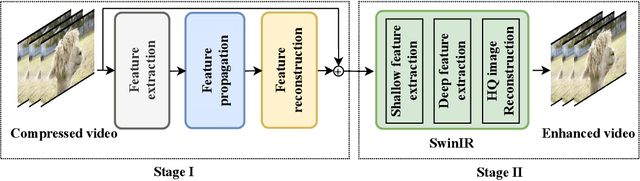
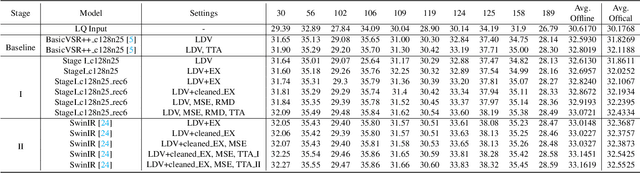
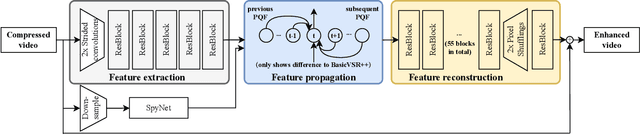
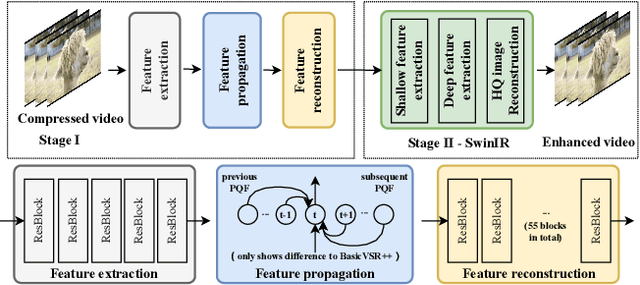
As a widely studied task, video restoration aims to enhance the quality of the videos with multiple potential degradations, such as noises, blurs and compression artifacts. Among video restorations, compressed video quality enhancement and video super-resolution are two of the main tacks with significant values in practical scenarios. Recently, recurrent neural networks and transformers attract increasing research interests in this field, due to their impressive capability in sequence-to-sequence modeling. However, the training of these models is not only costly but also relatively hard to converge, with gradient exploding and vanishing problems. To cope with these problems, we proposed a two-stage framework including a multi-frame recurrent network and a single-frame transformer. Besides, multiple training strategies, such as transfer learning and progressive training, are developed to shorten the training time and improve the model performance. Benefiting from the above technical contributions, our solution wins two champions and a runner-up in the NTIRE 2022 super-resolution and quality enhancement of compressed video challenges.
Early Exit Or Not: Resource-Efficient Blind Quality Enhancement for Compressed Images
Jul 09, 2020
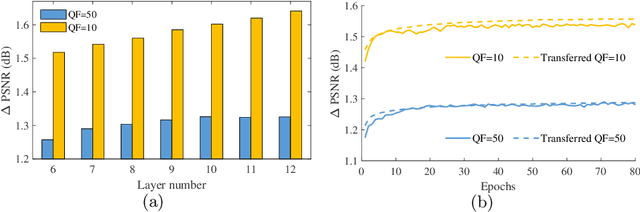
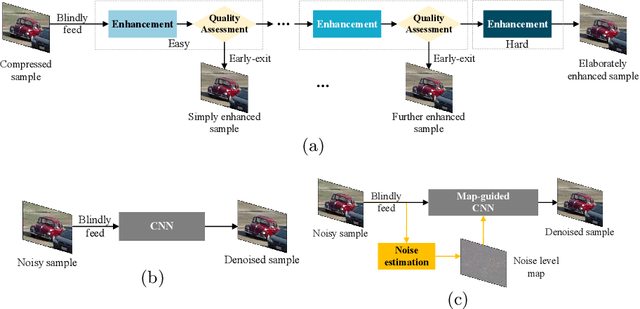
Lossy image compression is pervasively conducted to save communication bandwidth, resulting in undesirable compression artifacts. Recently, extensive approaches have been proposed to reduce image compression artifacts at the decoder side; however, they require a series of architecture-identical models to process images with different quality, which are inefficient and resource-consuming. Besides, it is common in practice that compressed images are with unknown quality and it is intractable for existing approaches to select a suitable model for blind quality enhancement. In this paper, we propose a resource-efficient blind quality enhancement (RBQE) approach for compressed images. Specifically, our approach blindly and progressively enhances the quality of compressed images through a dynamic deep neural network (DNN), in which an early-exit strategy is embedded. Then, our approach can automatically decide to terminate or continue enhancement according to the assessed quality of enhanced images. Consequently, slight artifacts can be removed in a simpler and faster process, while the severe artifacts can be further removed in a more elaborate process. Extensive experiments demonstrate that our RBQE approach achieves state-of-the-art performance in terms of both blind quality enhancement and resource efficiency.