 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Diffusion-Yielded Score Priors for Image Restoration
Jul 28, 2025Deep image restoration models aim to learn a mapping from degraded image space to natural image space. However, they face several critical challenges: removing degradation, generating realistic details, and ensuring pixel-level consistency. Over time, three major classes of methods have emerged, including MSE-based, GAN-based, and diffusion-based methods. However, they fail to achieve a good balance between restoration quality, fidelity, and speed. We propose a novel method, HYPIR, to address these challenges. Our solution pipeline is straightforward: it involves initializing the image restoration model with a pre-trained diffusion model and then fine-tuning it with adversarial training. This approach does not rely on diffusion loss, iterative sampling, or additional adapters. We theoretically demonstrate that initializing adversarial training from a pre-trained diffusion model positions the initial restoration model very close to the natural image distribution. Consequently, this initialization improves numerical stability, avoids mode collapse, and substantially accelerates the convergence of adversarial training. Moreover, HYPIR inherits the capabilities of diffusion models with rich user control, enabling text-guided restoration and adjustable texture richness. Requiring only a single forward pass, it achieves faster convergence and inference speed than diffusion-based methods. Extensive experiments show that HYPIR outperforms previous state-of-the-art methods, achieving efficient and high-quality image restoration.
Improving Training and Inference of Face Recognition Models via Random Temperature Scaling
Dec 02, 2022



Data uncertainty is commonly observed in the images for face recognition (FR). However, deep learning algorithms often make predictions with high confidence even for uncertain or irrelevant inputs. Intuitively, FR algorithms can benefit from both the estimation of uncertainty and the detection of out-of-distribution (OOD) samples. Taking a probabilistic view of the current classification model, the temperature scalar is exactly the scale of uncertainty noise implicitly added in the softmax function. Meanwhile, the uncertainty of images in a dataset should follow a prior distribution. Based on the observation, a unified framework for uncertainty modeling and FR, Random Temperature Scaling (RTS), is proposed to learn a reliable FR algorithm. The benefits of RTS are two-fold. (1) In the training phase, it can adjust the learning strength of clean and noisy samples for stability and accuracy. (2) In the test phase, it can provide a score of confidence to detect uncertain, low-quality and even OOD samples, without training on extra labels. Extensive experiments on FR benchmarks demonstrate that the magnitude of variance in RTS, which serves as an OOD detection metric, is closely related to the uncertainty of the input image. RTS can achieve top performance on both the FR and OOD detection tasks. Moreover, the model trained with RTS can perform robustly on datasets with noise. The proposed module is light-weight and only adds negligible computation cost to the model.
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
Mar 14, 2022
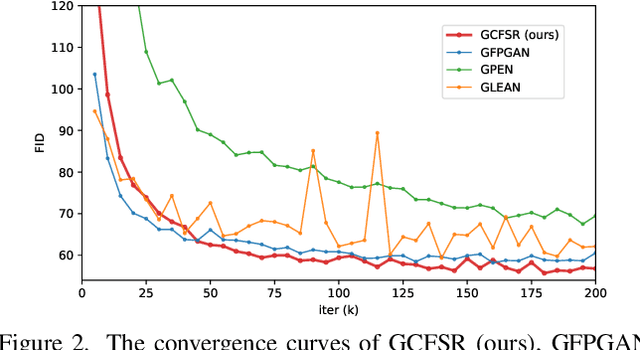

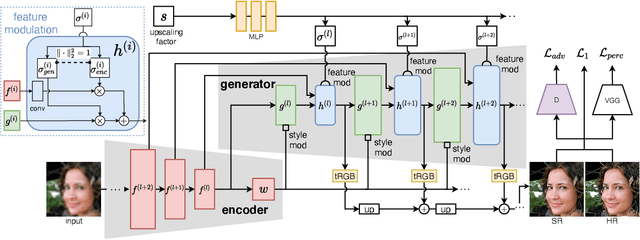
Face image super resolution (face hallucination) usually relies on facial priors to restore realistic details and preserve identity information. Recent advances can achieve impressive results with the help of GAN prior. They either design complicated modules to modify the fixed GAN prior or adopt complex training strategies to finetune the generator. In this work, we propose a generative and controllable face SR framework, called GCFSR, which can reconstruct images with faithful identity information without any additional priors. Generally, GCFSR has an encoder-generator architecture. Two modules called style modulation and feature modulation are designed for the multi-factor SR task. The style modulation aims to generate realistic face details and the feature modulation dynamically fuses the multi-level encoded features and the generated ones conditioned on the upscaling factor. The simple and elegant architecture can be trained from scratch in an end-to-end manner. For small upscaling factors (<=8), GCFSR can produce surprisingly good results with only adversarial loss. After adding L1 and perceptual losses, GCFSR can outperform state-of-the-art methods for large upscaling factors (16, 32, 64). During the test phase, we can modulate the generative strength via feature modulation by changing the conditional upscaling factor continuously to achieve various generative effects.
Learning to Synthesize Fashion Textures
Nov 18, 2019

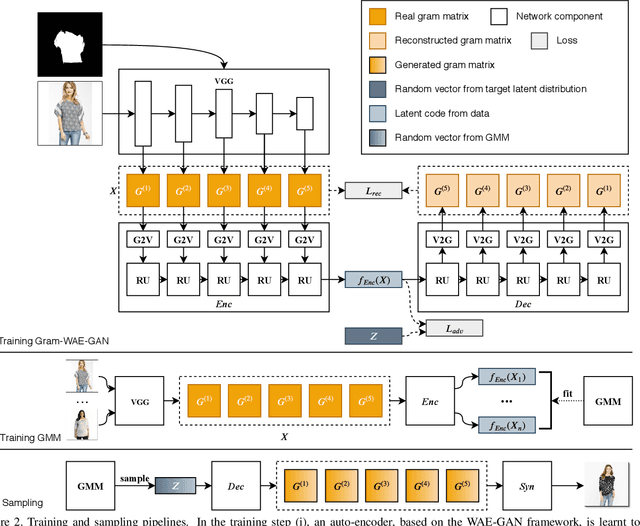

Existing unconditional generative models mainly focus on modeling general objects, such as faces and indoor scenes. Fashion textures, another important type of visual elements around us, have not been extensively studied. In this work, we propose an effective generative model for fashion textures and also comprehensively investigate the key components involved: internal representation, latent space sampling and the generator architecture. We use Gram matrix as a suitable internal representation for modeling realistic fashion textures, and further design two dedicated modules for modulating Gram matrix into a low-dimension vector. Since fashion textures are scale-dependent, we propose a recursive auto-encoder to capture the dependency between multiple granularity levels of texture feature. Another important observation is that fashion textures are multi-modal. We fit and sample from a Gaussian mixture model in the latent space to improve the diversity of the generated textures. Extensive experiments demonstrate that our approach is capable of synthesizing more realistic and diverse fashion textures over other state-of-the-art methods.