 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemur: Log Parsing with Entropy Sampling and Chain-of-Thought Merging
Mar 02, 2024Logs produced by extensive software systems are integral to monitoring system behaviors. Advanced log analysis facilitates the detection, alerting, and diagnosis of system faults. Log parsing, which entails transforming raw log messages into structured templates, constitutes a critical phase in the automation of log analytics. Existing log parsers fail to identify the correct templates due to reliance on human-made rules. Besides, These methods focus on statistical features while ignoring semantic information in log messages. To address these challenges, we introduce a cutting-edge \textbf{L}og parsing framework with \textbf{E}ntropy sampling and Chain-of-Thought \textbf{M}erging (Lemur). Specifically, to discard the tedious manual rules. We propose a novel sampling method inspired by information entropy, which efficiently clusters typical logs. Furthermore, to enhance the merging of log templates, we design a chain-of-thought method for large language models (LLMs). LLMs exhibit exceptional semantic comprehension, deftly distinguishing between parameters and invariant tokens. We have conducted experiments on large-scale public datasets. Extensive evaluation demonstrates that Lemur achieves the state-of-the-art performance and impressive efficiency.
VisionLLaMA: A Unified LLaMA Interface for Vision Tasks
Mar 01, 2024Large language models are built on top of a transformer-based architecture to process textual inputs. For example, the LLaMA stands out among many open-source implementations. Can the same transformer be used to process 2D images? In this paper, we answer this question by unveiling a LLaMA-like vision transformer in plain and pyramid forms, termed VisionLLaMA, which is tailored for this purpose. VisionLLaMA is a unified and generic modelling framework for solving most vision tasks. We extensively evaluate its effectiveness using typical pre-training paradigms in a good portion of downstream tasks of image perception and especially image generation. In many cases, VisionLLaMA have exhibited substantial gains over the previous state-of-the-art vision transformers. We believe that VisionLLaMA can serve as a strong new baseline model for vision generation and understanding. Our code will be released at https://github.com/Meituan-AutoML/VisionLLaMA.
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Feb 22, 2024



A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
ChartX & ChartVLM: A Versatile Benchmark and Foundation Model for Complicated Chart Reasoning
Feb 19, 2024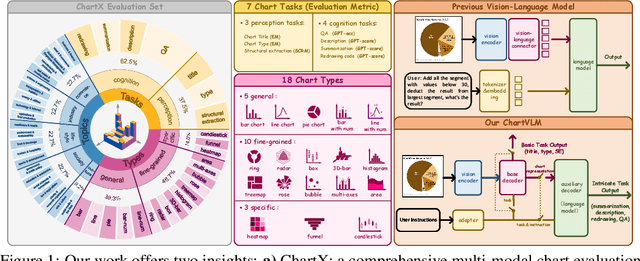
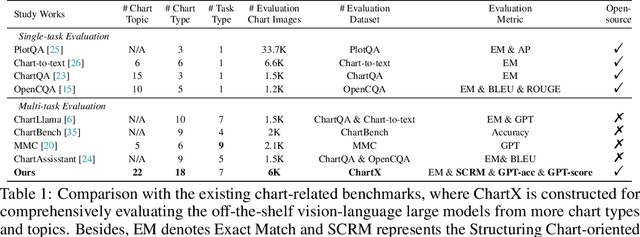
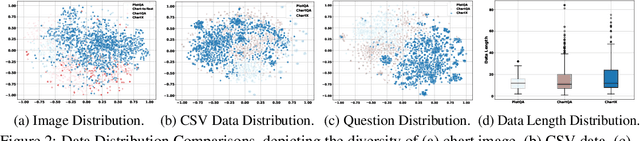
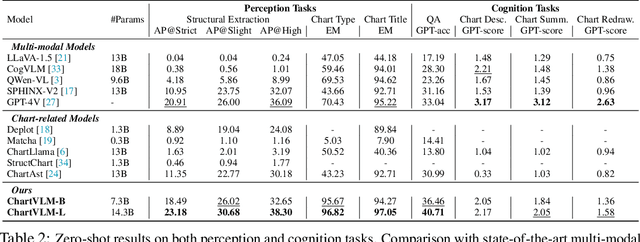
Recently, many versatile Multi-modal Large Language Models (MLLMs) have emerged continuously. However, their capacity to query information depicted in visual charts and engage in reasoning based on the queried contents remains under-explored. In this paper, to comprehensively and rigorously benchmark the ability of the off-the-shelf MLLMs in the chart domain, we construct ChartX, a multi-modal evaluation set covering 18 chart types, 7 chart tasks, 22 disciplinary topics, and high-quality chart data. Besides, we develop ChartVLM to offer a new perspective on handling multi-modal tasks that strongly depend on interpretable patterns, such as reasoning tasks in the field of charts or geometric images. We evaluate the chart-related ability of mainstream MLLMs and our ChartVLM on the proposed ChartX evaluation set. Extensive experiments demonstrate that ChartVLM surpasses both versatile and chart-related large models, achieving results comparable to GPT-4V. We believe that our study can pave the way for further exploration in creating a more comprehensive chart evaluation set and developing more interpretable multi-modal models. Both ChartX and ChartVLM are available at: https://github.com/UniModal4Reasoning/ChartVLM
Cross-Task Linearity Emerges in the Pretraining-Finetuning Paradigm
Feb 06, 2024



The pretraining-finetuning paradigm has become the prevailing trend in modern deep learning. In this work, we discover an intriguing linear phenomenon in models that are initialized from a common pretrained checkpoint and finetuned on different tasks, termed as Cross-Task Linearity (CTL). Specifically, if we linearly interpolate the weights of two finetuned models, the features in the weight-interpolated model are approximately equal to the linear interpolation of features in two finetuned models at each layer. Such cross-task linearity has not been noted in peer literature. We provide comprehensive empirical evidence supporting that CTL consistently occurs for finetuned models that start from the same pretrained checkpoint. We conjecture that in the pretraining-finetuning paradigm, neural networks essentially function as linear maps, mapping from the parameter space to the feature space. Based on this viewpoint, our study unveils novel insights into explaining model merging/editing, particularly by translating operations from the parameter space to the feature space. Furthermore, we delve deeper into the underlying factors for the emergence of CTL, emphasizing the impact of pretraining.
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Feb 06, 2024We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
LiDAR-PTQ: Post-Training Quantization for Point Cloud 3D Object Detection
Jan 29, 2024Due to highly constrained computing power and memory, deploying 3D lidar-based detectors on edge devices equipped in autonomous vehicles and robots poses a crucial challenge. Being a convenient and straightforward model compression approach, Post-Training Quantization (PTQ) has been widely adopted in 2D vision tasks. However, applying it directly to 3D lidar-based tasks inevitably leads to performance degradation. As a remedy, we propose an effective PTQ method called LiDAR-PTQ, which is particularly curated for 3D lidar detection (both SPConv-based and SPConv-free). Our LiDAR-PTQ features three main components, \textbf{(1)} a sparsity-based calibration method to determine the initialization of quantization parameters, \textbf{(2)} a Task-guided Global Positive Loss (TGPL) to reduce the disparity between the final predictions before and after quantization, \textbf{(3)} an adaptive rounding-to-nearest operation to minimize the layerwise reconstruction error. Extensive experiments demonstrate that our LiDAR-PTQ can achieve state-of-the-art quantization performance when applied to CenterPoint (both Pillar-based and Voxel-based). To our knowledge, for the very first time in lidar-based 3D detection tasks, the PTQ INT8 model's accuracy is almost the same as the FP32 model while enjoying $3\times$ inference speedup. Moreover, our LiDAR-PTQ is cost-effective being $30\times$ faster than the quantization-aware training method. Code will be released at \url{https://github.com/StiphyJay/LiDAR-PTQ}.
MLAD: A Unified Model for Multi-system Log Anomaly Detection
Jan 15, 2024In spite of the rapid advancements in unsupervised log anomaly detection techniques, the current mainstream models still necessitate specific training for individual system datasets, resulting in costly procedures and limited scalability due to dataset size, thereby leading to performance bottlenecks. Furthermore, numerous models lack cognitive reasoning capabilities, posing challenges in direct transferability to similar systems for effective anomaly detection. Additionally, akin to reconstruction networks, these models often encounter the "identical shortcut" predicament, wherein the majority of system logs are classified as normal, erroneously predicting normal classes when confronted with rare anomaly logs due to reconstruction errors. To address the aforementioned issues, we propose MLAD, a novel anomaly detection model that incorporates semantic relational reasoning across multiple systems. Specifically, we employ Sentence-bert to capture the similarities between log sequences and convert them into highly-dimensional learnable semantic vectors. Subsequently, we revamp the formulas of the Attention layer to discern the significance of each keyword in the sequence and model the overall distribution of the multi-system dataset through appropriate vector space diffusion. Lastly, we employ a Gaussian mixture model to highlight the uncertainty of rare words pertaining to the "identical shortcut" problem, optimizing the vector space of the samples using the maximum expectation model. Experiments on three real-world datasets demonstrate the superiority of MLAD.
LogFormer: A Pre-train and Tuning Pipeline for Log Anomaly Detection
Jan 09, 2024



Log anomaly detection is a key component in the field of artificial intelligence for IT operations (AIOps). Considering log data of variant domains, retraining the whole network for unknown domains is inefficient in real industrial scenarios. However, previous deep models merely focused on extracting the semantics of log sequences in the same domain, leading to poor generalization on multi-domain logs. To alleviate this issue, we propose a unified Transformer-based framework for Log anomaly detection (LogFormer) to improve the generalization ability across different domains, where we establish a two-stage process including the pre-training and adapter-based tuning stage. Specifically, our model is first pre-trained on the source domain to obtain shared semantic knowledge of log data. Then, we transfer such knowledge to the target domain via shared parameters. Besides, the Log-Attention module is proposed to supplement the information ignored by the log-paring. The proposed method is evaluated on three public and one real-world datasets. Experimental results on multiple benchmarks demonstrate the effectiveness of our LogFormer with fewer trainable parameters and lower training costs.