 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEviProp: Seeded Relevance Diffusion on Chunk-Page Graphs for Long Multimodal Document Retrieval
Jun 08, 2026Retrieving evidence pages from visually rich long documents is a key challenge in document question answering. Existing page-level visual retrievers operate under an independent matching paradigm: each page is scored in isolation based on query-page similarity. This paradigm can under-rank evidence pages whose signals are localized in fine-grained chunks or depend on document-internal associations. We propose EviProp, a retrieval method that recovers such pages via seeded relevance diffusion. EviProp models each document as a multimodal Chunk-Page graph with hierarchical, sequential, and similarity links. Given a query, it combines dense visual page priors with sparse chunk seeds, then runs Personalized PageRank to diffuse relevance over the graph. Experiments on MMLongBench-Doc and LongDocURL show consistent gains in evidence-page retrieval over independent visual retrieval and text-visual fusion baselines. Downstream QA results further show that improved retrieval translates into better answer accuracy, with negligible online retrieval overhead. Our code is released at https://github.com/Flyecnu/EviProp.
IA-RAG: Interval-Algebra-Driven Temporal Reasoning for Dynamic Knowledge Retrieval
Jun 04, 2026Retrieval-Augmented Generation (RAG) has shown strong effectiveness in grounding Large Language Models (LLMs) with external knowledge. However, existing RAG and Graph RAG frameworks largely treat knowledge as static or associate time with coarse-grained timestamps or metadata, failing to capture rich temporal structures such as duration, overlap, and containment. We propose IA-RAG, a hierarchical temporal RAG framework that models knowledge as time intervals and performs retrieval under formal temporal constraints. IA-RAG represents facts as Interval Event Units (IEUs) and organizes them into a hierarchical Thematic Forest, where temporal dependencies are governed by Allen's Interval Algebra. To handle incomplete or uncertain temporal boundaries, IA-RAG further introduces a Sub-graph Time Tightening mechanism that refines fuzzy intervals through logical constraints within connected event subgraphs. In addition, IA-RAG supports implicit temporal semantic retrieval through interval-algebra-guided traversal. Experiments on multiple temporal question answering benchmarks, including TimeQA, TempReason, and ComplexTR, demonstrate that IA-RAG achieves strong temporal retrieval and reasoning performance, particularly on complex compositional temporal reasoning tasks. Our code is released at https://github.com/xiaoAugenstern/LogicalRAG_TemporalQA.
LeanRAG: Knowledge-Graph-Based Generation with Semantic Aggregation and Hierarchical Retrieval
Aug 14, 2025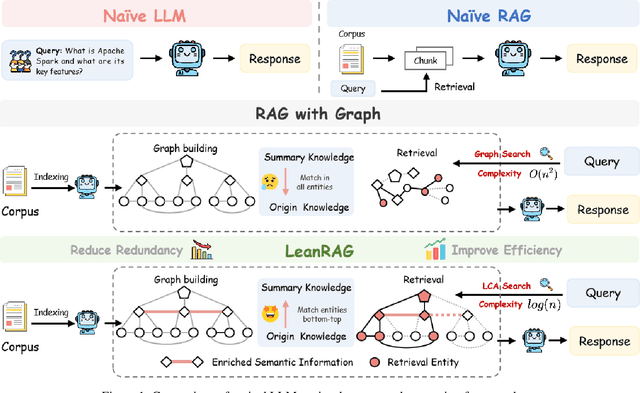
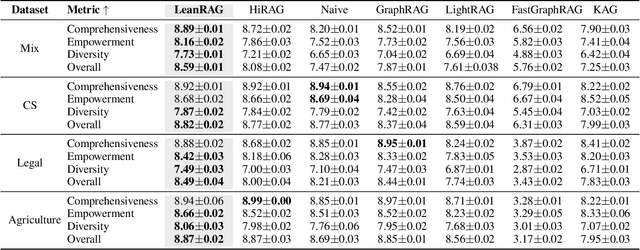
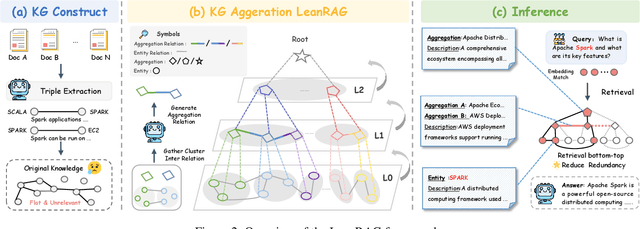

Retrieval-Augmented Generation (RAG) plays a crucial role in grounding Large Language Models by leveraging external knowledge, whereas the effectiveness is often compromised by the retrieval of contextually flawed or incomplete information. To address this, knowledge graph-based RAG methods have evolved towards hierarchical structures, organizing knowledge into multi-level summaries. However, these approaches still suffer from two critical, unaddressed challenges: high-level conceptual summaries exist as disconnected ``semantic islands'', lacking the explicit relations needed for cross-community reasoning; and the retrieval process itself remains structurally unaware, often degenerating into an inefficient flat search that fails to exploit the graph's rich topology. To overcome these limitations, we introduce LeanRAG, a framework that features a deeply collaborative design combining knowledge aggregation and retrieval strategies. LeanRAG first employs a novel semantic aggregation algorithm that forms entity clusters and constructs new explicit relations among aggregation-level summaries, creating a fully navigable semantic network. Then, a bottom-up, structure-guided retrieval strategy anchors queries to the most relevant fine-grained entities and then systematically traverses the graph's semantic pathways to gather concise yet contextually comprehensive evidence sets. The LeanRAG can mitigate the substantial overhead associated with path retrieval on graphs and minimizes redundant information retrieval. Extensive experiments on four challenging QA benchmarks with different domains demonstrate that LeanRAG significantly outperforming existing methods in response quality while reducing 46\% retrieval redundancy. Code is available at: https://github.com/RaZzzyz/LeanRAG
MELLA: Bridging Linguistic Capability and Cultural Groundedness for Low-Resource Language MLLMs
Aug 07, 2025Multimodal Large Language Models (MLLMs) have shown remarkable performance in high-resource languages. However, their effectiveness diminishes significantly in the contexts of low-resource languages. Current multilingual enhancement methods are often limited to text modality or rely solely on machine translation. While such approaches help models acquire basic linguistic capabilities and produce "thin descriptions", they neglect the importance of multimodal informativeness and cultural groundedness, both of which are crucial for serving low-resource language users effectively. To bridge this gap, in this study, we identify two significant objectives for a truly effective MLLM in low-resource language settings, namely 1) linguistic capability and 2) cultural groundedness, placing special emphasis on cultural awareness. To achieve these dual objectives, we propose a dual-source strategy that guides the collection of data tailored to each goal, sourcing native web alt-text for culture and MLLM-generated captions for linguistics. As a concrete implementation, we introduce MELLA, a multimodal, multilingual dataset. Experiment results show that after fine-tuning on MELLA, there is a general performance improvement for the eight languages on various MLLM backbones, with models producing "thick descriptions". We verify that the performance gains are from both cultural knowledge enhancement and linguistic capability enhancement. Our dataset can be found at https://opendatalab.com/applyMultilingualCorpus.
RAKG:Document-level Retrieval Augmented Knowledge Graph Construction
Apr 14, 2025With the rise of knowledge graph based retrieval-augmented generation (RAG) techniques such as GraphRAG and Pike-RAG, the role of knowledge graphs in enhancing the reasoning capabilities of large language models (LLMs) has become increasingly prominent. However, traditional Knowledge Graph Construction (KGC) methods face challenges like complex entity disambiguation, rigid schema definition, and insufficient cross-document knowledge integration. This paper focuses on the task of automatic document-level knowledge graph construction. It proposes the Document-level Retrieval Augmented Knowledge Graph Construction (RAKG) framework. RAKG extracts pre-entities from text chunks and utilizes these pre-entities as queries for RAG, effectively addressing the issue of long-context forgetting in LLMs and reducing the complexity of Coreference Resolution. In contrast to conventional KGC methods, RAKG more effectively captures global information and the interconnections among disparate nodes, thereby enhancing the overall performance of the model. Additionally, we transfer the RAG evaluation framework to the KGC field and filter and evaluate the generated knowledge graphs, thereby avoiding incorrectly generated entities and relationships caused by hallucinations in LLMs. We further developed the MINE dataset by constructing standard knowledge graphs for each article and experimentally validated the performance of RAKG. The results show that RAKG achieves an accuracy of 95.91 % on the MINE dataset, a 6.2 % point improvement over the current best baseline, GraphRAG (89.71 %). The code is available at https://github.com/LMMApplication/RAKG.
Aligning Vision to Language: Text-Free Multimodal Knowledge Graph Construction for Enhanced LLMs Reasoning
Mar 17, 2025Multimodal reasoning in Large Language Models (LLMs) struggles with incomplete knowledge and hallucination artifacts, challenges that textual Knowledge Graphs (KGs) only partially mitigate due to their modality isolation. While Multimodal Knowledge Graphs (MMKGs) promise enhanced cross-modal understanding, their practical construction is impeded by semantic narrowness of manual text annotations and inherent noise in visual-semantic entity linkages. In this paper, we propose Vision-align-to-Language integrated Knowledge Graph (VaLiK), a novel approach for constructing MMKGs that enhances LLMs reasoning through cross-modal information supplementation. Specifically, we cascade pre-trained Vision-Language Models (VLMs) to align image features with text, transforming them into descriptions that encapsulate image-specific information. Furthermore, we developed a cross-modal similarity verification mechanism to quantify semantic consistency, effectively filtering out noise introduced during feature alignment. Even without manually annotated image captions, the refined descriptions alone suffice to construct the MMKG. Compared to conventional MMKGs construction paradigms, our approach achieves substantial storage efficiency gains while maintaining direct entity-to-image linkage capability. Experimental results on multimodal reasoning tasks demonstrate that LLMs augmented with VaLiK outperform previous state-of-the-art models. Our code is published at https://github.com/Wings-Of-Disaster/VaLiK.
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
Realistic Rainy Weather Simulation for LiDARs in CARLA Simulator
Dec 20, 2023



Employing data augmentation methods to enhance perception performance in adverse weather has attracted considerable attention recently. Most of the LiDAR augmentation methods post-process the existing dataset by physics-based models or machine-learning methods. However, due to the limited environmental annotations and the fixed vehicle trajectories in the existing dataset, it is challenging to edit the scene and expand the diversity of traffic flow and scenario. To this end, we propose a simulator-based physical modeling approach to augment LiDAR data in rainy weather in order to improve the perception performance of LiDAR in this scenario. We complete the modeling task of the rainy weather in the CARLA simulator and establish a pipeline for LiDAR data collection. In particular, we pay special attention to the spray and splash rolled up by the wheels of surrounding vehicles in rain and complete the simulation of this special scenario through the Spray Emitter method we developed. In addition, we examine the influence of different weather conditions on the intensity of the LiDAR echo, develop a prediction network for the intensity of the LiDAR echo, and complete the simulation of 4-feat LiDAR point cloud data. In the experiment, we observe that the model augmented by the synthetic data improves the object detection task's performance in the rainy sequence of the Waymo Open Dataset. Both the code and the dataset will be made publicly available at https://github.com/PJLab-ADG/PCSim#rainypcsim.
Calib-Anything: Zero-training LiDAR-Camera Extrinsic Calibration Method Using Segment Anything
Jun 05, 2023



The research on extrinsic calibration between Light Detection and Ranging(LiDAR) and camera are being promoted to a more accurate, automatic and generic manner. Since deep learning has been employed in calibration, the restrictions on the scene are greatly reduced. However, data driven method has the drawback of low transfer-ability. It cannot adapt to dataset variations unless additional training is taken. With the advent of foundation model, this problem can be significantly mitigated. By using the Segment Anything Model(SAM), we propose a novel LiDAR-camera calibration method, which requires zero extra training and adapts to common scenes. With an initial guess, we opimize the extrinsic parameter by maximizing the consistency of points that are projected inside each image mask. The consistency includes three properties of the point cloud: the intensity, normal vector and categories derived from some segmentation methods. The experiments on different dataset have demonstrated the generality and comparable accuracy of our method. The code is available at https://github.com/OpenCalib/CalibAnything.
Automatic Surround Camera Calibration Method in Road Scene for Self-driving Car
May 26, 2023



With the development of autonomous driving technology, sensor calibration has become a key technology to achieve accurate perception fusion and localization. Accurate calibration of the sensors ensures that each sensor can function properly and accurate information aggregation can be achieved. Among them, camera calibration based on surround view has received extensive attention. In autonomous driving applications, the calibration accuracy of the camera can directly affect the accuracy of perception and depth estimation. For online calibration of surround-view cameras, traditional feature extraction-based methods will suffer from strong distortion when the initial extrinsic parameters error is large, making these methods less robust and inaccurate. More existing methods use the sparse direct method to calibrate multi-cameras, which can ensure both accuracy and real-time performance and is theoretically achievable. However, this method requires a better initial value, and the initial estimate with a large error is often stuck in a local optimum. To this end, we introduce a robust automatic multi-cameras (pinhole or fisheye cameras) calibration and refinement method in the road scene. We utilize the coarse-to-fine random-search strategy, and it can solve large disturbances of initial extrinsic parameters, which can make up for falling into optimal local value in nonlinear optimization methods. In the end, quantitative and qualitative experiments are conducted in actual and simulated environments, and the result shows the proposed method can achieve accuracy and robustness performance. The open-source code is available at https://github.com/OpenCalib/SurroundCameraCalib.