 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Transformers Learn to Plan via Multi-Token Prediction
Apr 13, 2026While next-token prediction (NTP) has been the standard objective for training language models, it often struggles to capture global structure in reasoning tasks. Multi-token prediction (MTP) has recently emerged as a promising alternative, yet its underlying mechanisms remain poorly understood. In this paper, we study how MTP facilitates reasoning, with a focus on planning. Empirically, we show that MTP consistently outperforms NTP on both synthetic graph path-finding tasks and more realistic reasoning benchmarks, such as Countdown and boolean satisfiability problems. Theoretically, we analyze a simplified two-layer Transformer on a star graph task. We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward. This behavior arises from a gradient decoupling property of MTP, which provides a cleaner training signal compared to NTP. Ultimately, our results highlight how multi-token objectives inherently bias optimization toward robust and interpretable reasoning circuits.
IGU-LoRA: Adaptive Rank Allocation via Integrated Gradients and Uncertainty-Aware Scoring
Mar 14, 2026As large language models (LLMs) scale to billions of parameters, full-parameter fine-tuning becomes compute- and memory-prohibitive. Parameter-efficient fine-tuning (PEFT) mitigates this issue by updating only a small set of task-specific parameters while keeping the base model frozen. Among PEFT approaches, low-rank adaptation (LoRA) is widely adopted; however, it enforces a uniform rank across layers despite substantial variation in layer importance, motivating {layerwise} rank allocation. Recent adaptive-rank variants (e.g., AdaLoRA) allocate ranks based on importance scores, yet typically rely on instantaneous gradients that capture only local sensitivity, overlooking non-local, pathwise effects within the same layer, which yields unstable and biased scores. To address this limitation, we introduce IGU-LoRA, an adaptive-rank LoRA that (i) computes within-layer Integrated Gradients (IG) sensitivities and aggregates them into a layer-level score for rank allocation, and (ii) applies an uncertainty-aware scheme using exponential moving averages with deviation tracking to suppress noisy updates and calibrate rank selection. Theoretically, we prove an upper bound on the composite trapezoidal rule approximation error for parameter-space IG under a pathwise Hessian-Lipschitz condition, which informs the quadrature budget. Across diverse tasks and architectures, IGU-LoRA consistently outperforms strong PEFT baselines at matched parameter budgets, improving downstream accuracy and robustness. Ablations confirm the contributions of pathwise within-layer sensitivity estimates and uncertainty-aware selection to effective rank allocation. Our code is publicly available at https://github.com/withyou12/igulora.git
On the Learning Dynamics of Two-layer Linear Networks with Label Noise SGD
Mar 11, 2026One crucial factor behind the success of deep learning lies in the implicit bias induced by noise inherent in gradient-based training algorithms. Motivated by empirical observations that training with noisy labels improves model generalization, we delve into the underlying mechanisms behind stochastic gradient descent (SGD) with label noise. Focusing on a two-layer over-parameterized linear network, we analyze the learning dynamics of label noise SGD, unveiling a two-phase learning behavior. In \emph{Phase I}, the magnitudes of model weights progressively diminish, and the model escapes the lazy regime; enters the rich regime. In \emph{Phase II}, the alignment between model weights and the ground-truth interpolator increases, and the model eventually converges. Our analysis highlights the critical role of label noise in driving the transition from the lazy to the rich regime and minimally explains its empirical success. Furthermore, we extend these insights to Sharpness-Aware Minimization (SAM), showing that the principles governing label noise SGD also apply to broader optimization algorithms. Extensive experiments, conducted under both synthetic and real-world setups, strongly support our theory. Our code is released at https://github.com/a-usually/Label-Noise-SGD.
Fast Catch-Up, Late Switching: Optimal Batch Size Scheduling via Functional Scaling Laws
Feb 15, 2026Batch size scheduling (BSS) plays a critical role in large-scale deep learning training, influencing both optimization dynamics and computational efficiency. Yet, its theoretical foundations remain poorly understood. In this work, we show that the functional scaling law (FSL) framework introduced in Li et al. (2025a) provides a principled lens for analyzing BSS. Specifically, we characterize the optimal BSS under a fixed data budget and show that its structure depends sharply on task difficulty. For easy tasks, optimal schedules keep increasing batch size throughout. In contrast, for hard tasks, the optimal schedule maintains small batch sizes for most of training and switches to large batches only in a late stage. To explain the emergence of late switching, we uncover a dynamical mechanism -- the fast catch-up effect -- which also manifests in large language model (LLM) pretraining. After switching from small to large batches, the loss rapidly aligns with the constant large-batch trajectory. Using FSL, we show that this effect stems from rapid forgetting of accumulated gradient noise, with the catch-up speed determined by task difficulty. Crucially, this effect implies that large batches can be safely deferred to late training without sacrificing performance, while substantially reducing data consumption. Finally, extensive LLM pretraining experiments -- covering both Dense and MoE architectures with up to 1.1B parameters and 1T tokens -- validate our theoretical predictions. Across all settings, late-switch schedules consistently outperform constant-batch and early-switch baselines.
A Single Merging Suffices: Recovering Server-based Learning Performance in Decentralized Learning
Jul 09, 2025Decentralized learning provides a scalable alternative to traditional parameter-server-based training, yet its performance is often hindered by limited peer-to-peer communication. In this paper, we study how communication should be scheduled over time, including determining when and how frequently devices synchronize. Our empirical results show that concentrating communication budgets in the later stages of decentralized training markedly improves global generalization. Surprisingly, we uncover that fully connected communication at the final step, implemented by a single global merging, is sufficient to match the performance of server-based training. We further show that low communication in decentralized learning preserves the \textit{mergeability} of local models throughout training. Our theoretical contributions, which explains these phenomena, are first to establish that the globally merged model of decentralized SGD can converge faster than centralized mini-batch SGD. Technically, we novelly reinterpret part of the discrepancy among local models, which were previously considered as detrimental noise, as constructive components that accelerate convergence. This work challenges the common belief that decentralized learning generalizes poorly under data heterogeneity and limited communication, while offering new insights into model merging and neural network loss landscapes.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
On the Role of Label Noise in the Feature Learning Process
May 25, 2025Deep learning with noisy labels presents significant challenges. In this work, we theoretically characterize the role of label noise from a feature learning perspective. Specifically, we consider a signal-noise data distribution, where each sample comprises a label-dependent signal and label-independent noise, and rigorously analyze the training dynamics of a two-layer convolutional neural network under this data setup, along with the presence of label noise. Our analysis identifies two key stages. In Stage I, the model perfectly fits all the clean samples (i.e., samples without label noise) while ignoring the noisy ones (i.e., samples with noisy labels). During this stage, the model learns the signal from the clean samples, which generalizes well on unseen data. In Stage II, as the training loss converges, the gradient in the direction of noise surpasses that of the signal, leading to overfitting on noisy samples. Eventually, the model memorizes the noise present in the noisy samples and degrades its generalization ability. Furthermore, our analysis provides a theoretical basis for two widely used techniques for tackling label noise: early stopping and sample selection. Experiments on both synthetic and real-world setups validate our theory.
New Evidence of the Two-Phase Learning Dynamics of Neural Networks
May 20, 2025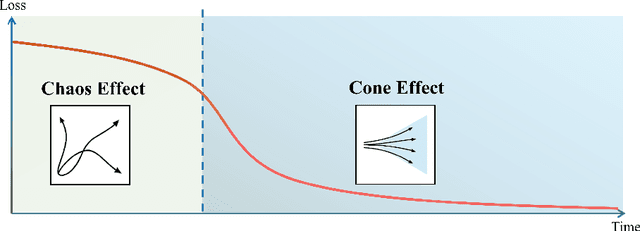
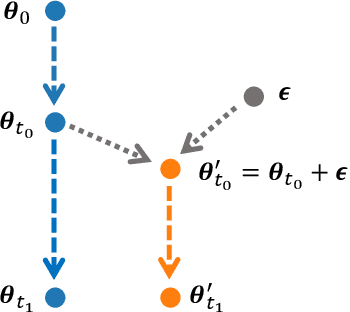
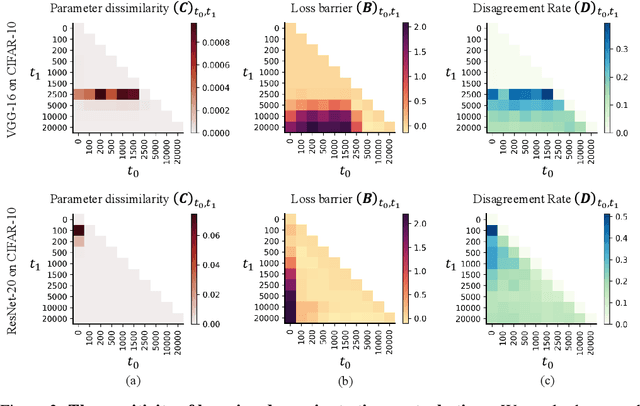
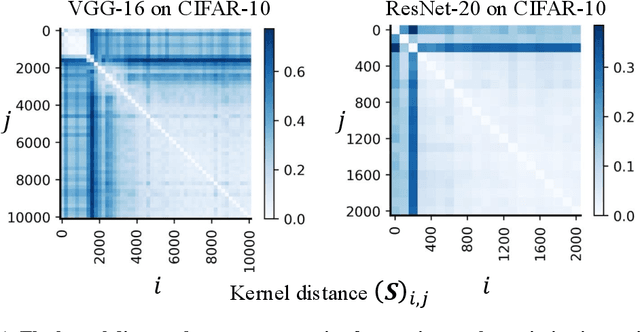
Understanding how deep neural networks learn remains a fundamental challenge in modern machine learning. A growing body of evidence suggests that training dynamics undergo a distinct phase transition, yet our understanding of this transition is still incomplete. In this paper, we introduce an interval-wise perspective that compares network states across a time window, revealing two new phenomena that illuminate the two-phase nature of deep learning. i) \textbf{The Chaos Effect.} By injecting an imperceptibly small parameter perturbation at various stages, we show that the response of the network to the perturbation exhibits a transition from chaotic to stable, suggesting there is an early critical period where the network is highly sensitive to initial conditions; ii) \textbf{The Cone Effect.} Tracking the evolution of the empirical Neural Tangent Kernel (eNTK), we find that after this transition point the model's functional trajectory is confined to a narrow cone-shaped subset: while the kernel continues to change, it gets trapped into a tight angular region. Together, these effects provide a structural, dynamical view of how deep networks transition from sensitive exploration to stable refinement during training.
On the Cone Effect in the Learning Dynamics
Mar 20, 2025Understanding the learning dynamics of neural networks is a central topic in the deep learning community. In this paper, we take an empirical perspective to study the learning dynamics of neural networks in real-world settings. Specifically, we investigate the evolution process of the empirical Neural Tangent Kernel (eNTK) during training. Our key findings reveal a two-phase learning process: i) in Phase I, the eNTK evolves significantly, signaling the rich regime, and ii) in Phase II, the eNTK keeps evolving but is constrained in a narrow space, a phenomenon we term the cone effect. This two-phase framework builds on the hypothesis proposed by Fort et al. (2020), but we uniquely identify the cone effect in Phase II, demonstrating its significant performance advantages over fully linearized training.
The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
Feb 26, 2025Transformers consist of diverse building blocks, such as embedding layers, normalization layers, self-attention mechanisms, and point-wise feedforward networks. Thus, understanding the differences and interactions among these blocks is important. In this paper, we uncover a clear Sharpness Disparity across these blocks, which emerges early in training and intriguingly persists throughout the training process. Motivated by this finding, we propose Blockwise Learning Rate (LR), a strategy that tailors the LR to each block's sharpness, accelerating large language model (LLM) pre-training. By integrating Blockwise LR into AdamW, we consistently achieve lower terminal loss and nearly $2\times$ speedup compared to vanilla AdamW. We demonstrate this acceleration across GPT-2 and LLaMA, with model sizes ranging from 0.12B to 1.1B and datasets of OpenWebText and MiniPile. Finally, we incorporate Blockwise LR into Adam-mini (Zhang et al., 2024), a recently proposed memory-efficient variant of Adam, achieving a combined $2\times$ speedup and $2\times$ memory saving. These results underscore the potential of exploiting the sharpness disparity to improve LLM training.