 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ThreeDWorld Transport Challenge: A Visually Guided Task-and-Motion Planning Benchmark for Physically Realistic Embodied AI
Mar 25, 2021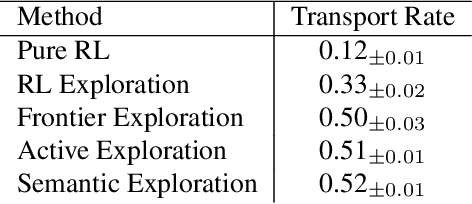

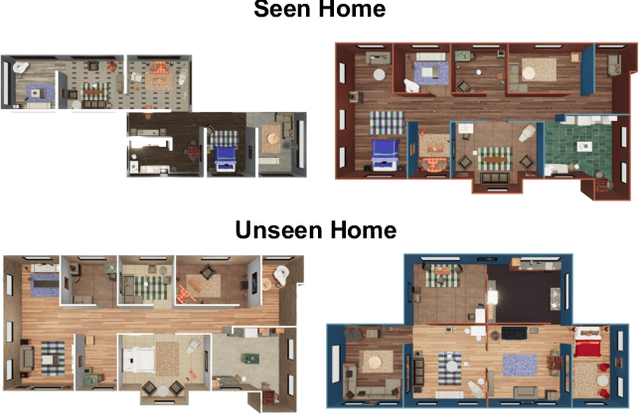
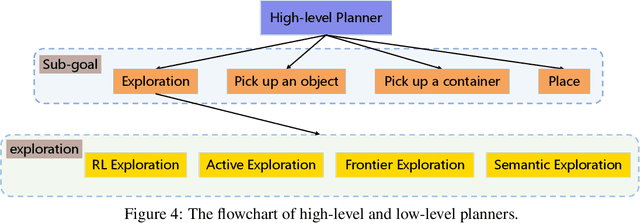
We introduce a visually-guided and physics-driven task-and-motion planning benchmark, which we call the ThreeDWorld Transport Challenge. In this challenge, an embodied agent equipped with two 9-DOF articulated arms is spawned randomly in a simulated physical home environment. The agent is required to find a small set of objects scattered around the house, pick them up, and transport them to a desired final location. We also position containers around the house that can be used as tools to assist with transporting objects efficiently. To complete the task, an embodied agent must plan a sequence of actions to change the state of a large number of objects in the face of realistic physical constraints. We build this benchmark challenge using the ThreeDWorld simulation: a virtual 3D environment where all objects respond to physics, and where can be controlled using fully physics-driven navigation and interaction API. We evaluate several existing agents on this benchmark. Experimental results suggest that: 1) a pure RL model struggles on this challenge; 2) hierarchical planning-based agents can transport some objects but still far from solving this task. We anticipate that this benchmark will empower researchers to develop more intelligent physics-driven robots for the physical world.
Paint by Word
Mar 24, 2021
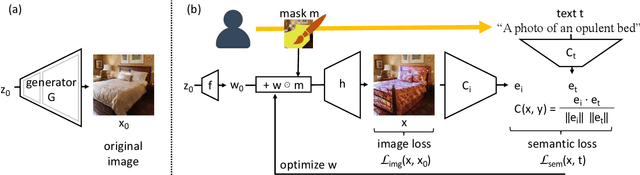

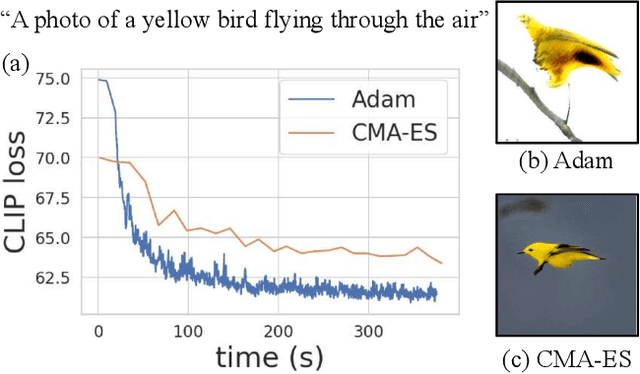
We investigate the problem of zero-shot semantic image painting. Instead of painting modifications into an image using only concrete colors or a finite set of semantic concepts, we ask how to create semantic paint based on open full-text descriptions: our goal is to be able to point to a location in a synthesized image and apply an arbitrary new concept such as "rustic" or "opulent" or "happy dog." To do this, our method combines a state-of-the art generative model of realistic images with a state-of-the-art text-image semantic similarity network. We find that, to make large changes, it is important to use non-gradient methods to explore latent space, and it is important to relax the computations of the GAN to target changes to a specific region. We conduct user studies to compare our methods to several baselines.
Deep Feedback Inverse Problem Solver
Jan 19, 2021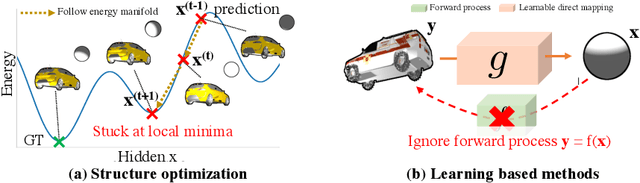
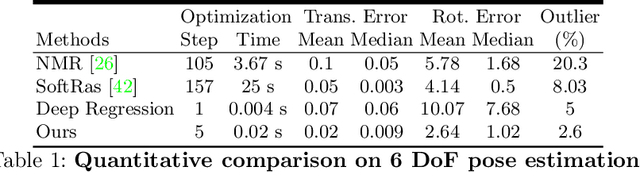
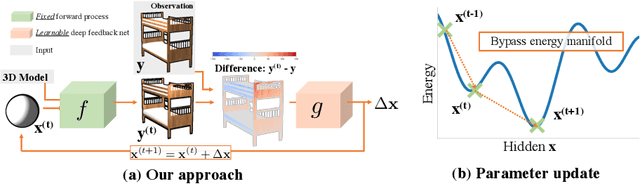
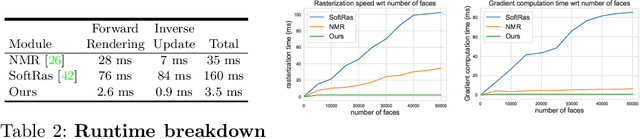
We present an efficient, effective, and generic approach towards solving inverse problems. The key idea is to leverage the feedback signal provided by the forward process and learn an iterative update model. Specifically, at each iteration, the neural network takes the feedback as input and outputs an update on the current estimation. Our approach does not have any restrictions on the forward process; it does not require any prior knowledge either. Through the feedback information, our model not only can produce accurate estimations that are coherent to the input observation but also is capable of recovering from early incorrect predictions. We verify the performance of our approach over a wide range of inverse problems, including 6-DOF pose estimation, illumination estimation, as well as inverse kinematics. Comparing to traditional optimization-based methods, we can achieve comparable or better performance while being two to three orders of magnitude faster. Compared to deep learning-based approaches, our model consistently improves the performance on all metrics. Please refer to the project page for videos, animations, supplementary materials, etc.
Energy-Based Models for Continual Learning
Nov 24, 2020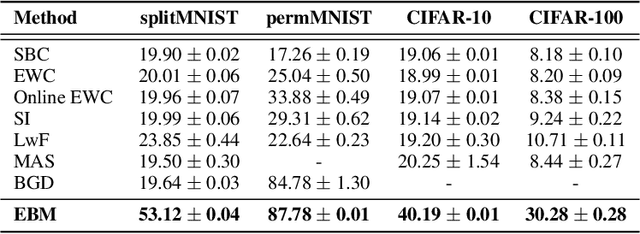
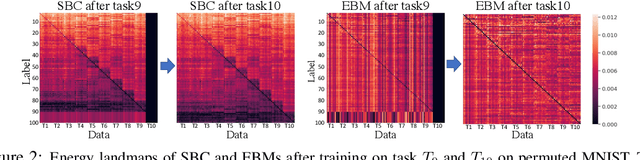

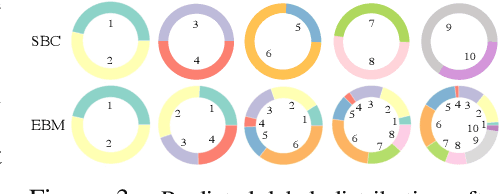
We motivate Energy-Based Models (EBMs) as a promising model class for continual learning problems. Instead of tackling continual learning via the use of external memory, growing models, or regularization, EBMs have a natural way to support a dynamically-growing number of tasks or classes that causes less interference with previously learned information. We find that EBMs outperform the baseline methods by a large margin on several continual learning benchmarks. We also show that EBMs are adaptable to a more general continual learning setting where the data distribution changes without the notion of explicitly delineated tasks. These observations point towards EBMs as a class of models naturally inclined towards the continual learning regime.
Watch-And-Help: A Challenge for Social Perception and Human-AI Collaboration
Oct 19, 2020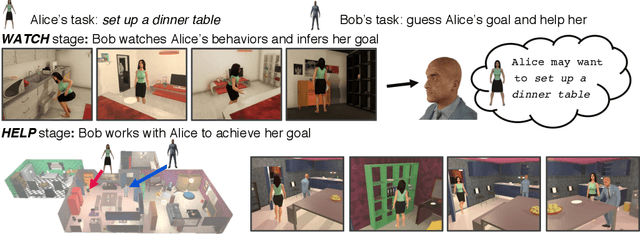

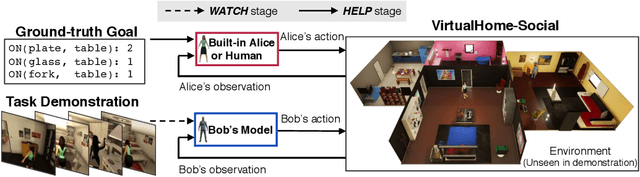
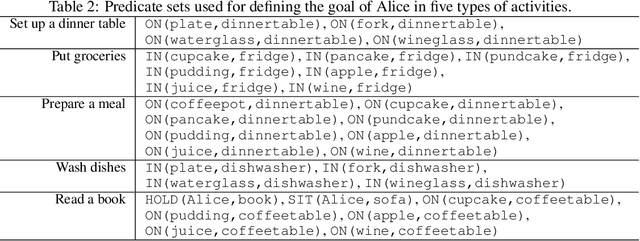
In this paper, we introduce Watch-And-Help (WAH), a challenge for testing social intelligence in agents. In WAH, an AI agent needs to help a human-like agent perform a complex household task efficiently. To succeed, the AI agent needs to i) understand the underlying goal of the task by watching a single demonstration of the human-like agent performing the same task (social perception), and ii) coordinate with the human-like agent to solve the task in an unseen environment as fast as possible (human-AI collaboration). For this challenge, we build VirtualHome-Social, a multi-agent household environment, and provide a benchmark including both planning and learning based baselines. We evaluate the performance of AI agents with the human-like agent as well as with real humans using objective metrics and subjective user ratings. Experimental results demonstrate that the proposed challenge and virtual environment enable a systematic evaluation on the important aspects of machine social intelligence at scale.
Image GANs meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering
Oct 18, 2020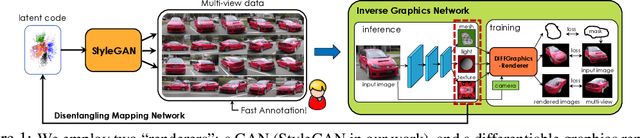



Differentiable rendering has paved the way to training neural networks to perform "inverse graphics" tasks such as predicting 3D geometry from monocular photographs. To train high performing models, most of the current approaches rely on multi-view imagery which are not readily available in practice. Recent Generative Adversarial Networks (GANs) that synthesize images, in contrast, seem to acquire 3D knowledge implicitly during training: object viewpoints can be manipulated by simply manipulating the latent codes. However, these latent codes often lack further physical interpretation and thus GANs cannot easily be inverted to perform explicit 3D reasoning. In this paper, we aim to extract and disentangle 3D knowledge learned by generative models by utilizing differentiable renderers. Key to our approach is to exploit GANs as a multi-view data generator to train an inverse graphics network using an off-the-shelf differentiable renderer, and the trained inverse graphics network as a teacher to disentangle the GAN's latent code into interpretable 3D properties. The entire architecture is trained iteratively using cycle consistency losses. We show that our approach significantly outperforms state-of-the-art inverse graphics networks trained on existing datasets, both quantitatively and via user studies. We further showcase the disentangled GAN as a controllable 3D "neural renderer", complementing traditional graphics renderers.
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020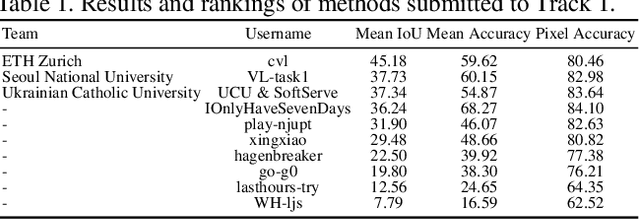
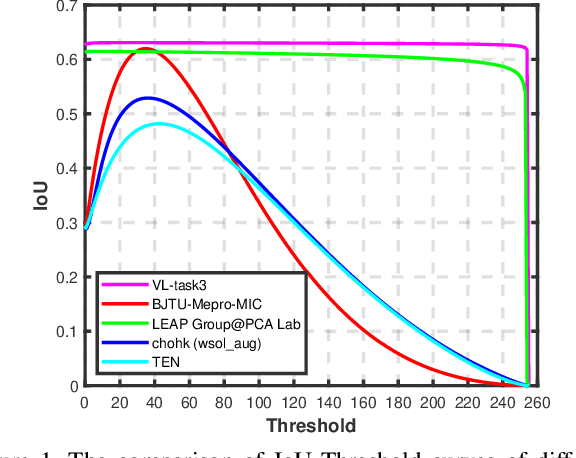

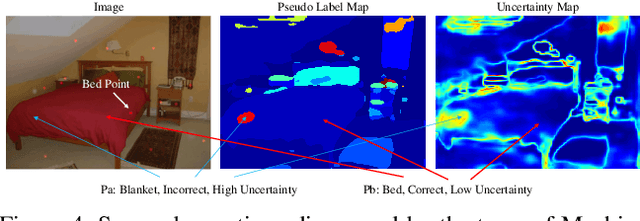
Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io
Improving Inversion and Generation Diversity in StyleGAN using a Gaussianized Latent Space
Sep 14, 2020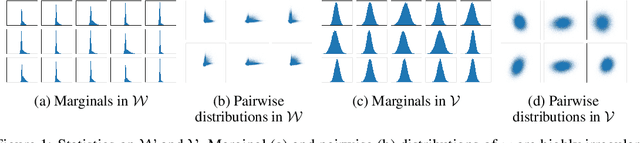
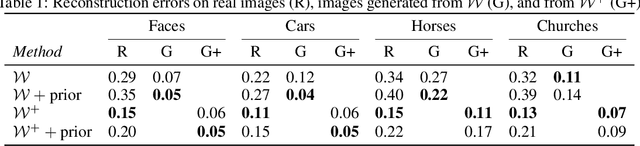
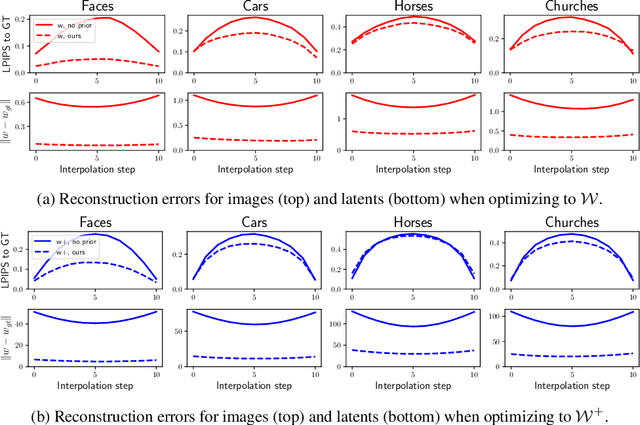

Modern Generative Adversarial Networks are capable of creating artificial, photorealistic images from latent vectors living in a low-dimensional learned latent space. It has been shown that a wide range of images can be projected into this space, including images outside of the domain that the generator was trained on. However, while in this case the generator reproduces the pixels and textures of the images, the reconstructed latent vectors are unstable and small perturbations result in significant image distortions. In this work, we propose to explicitly model the data distribution in latent space. We show that, under a simple nonlinear operation, the data distribution can be modeled as Gaussian and therefore expressed using sufficient statistics. This yields a simple Gaussian prior, which we use to regularize the projection of images into the latent space. The resulting projections lie in smoother and better behaved regions of the latent space, as shown using interpolation performance for both real and generated images. Furthermore, the Gaussian model of the distribution in latent space allows us to investigate the origins of artifacts in the generator output, and provides a method for reducing these artifacts while maintaining diversity of the generated images.
Understanding the Role of Individual Units in a Deep Neural Network
Sep 12, 2020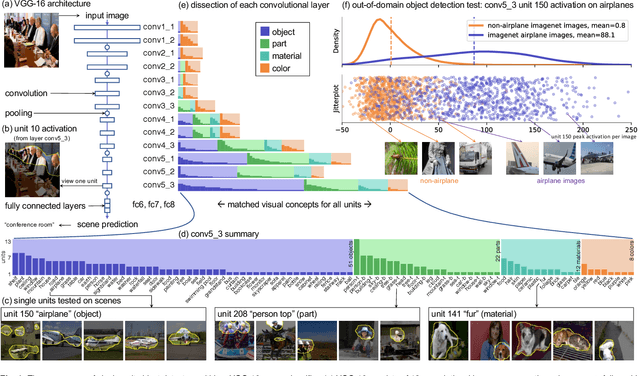
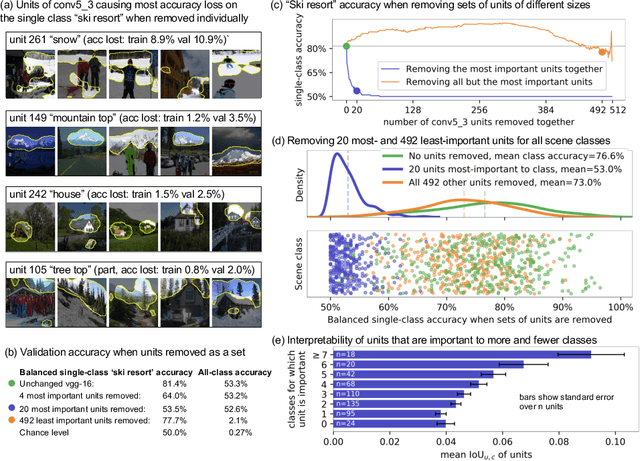
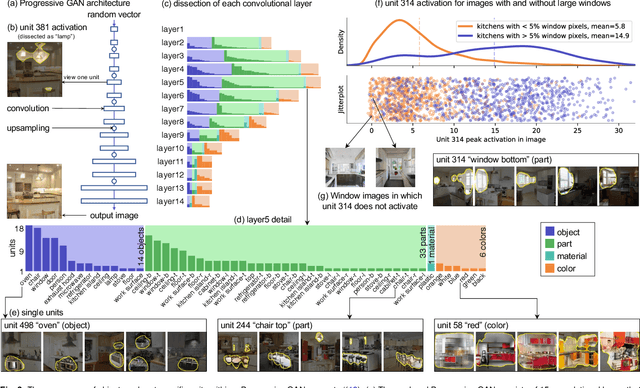
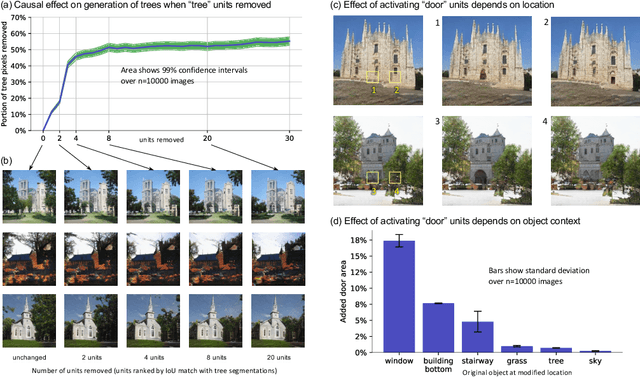
Deep neural networks excel at finding hierarchical representations that solve complex tasks over large data sets. How can we humans understand these learned representations? In this work, we present network dissection, an analytic framework to systematically identify the semantics of individual hidden units within image classification and image generation networks. First, we analyze a convolutional neural network (CNN) trained on scene classification and discover units that match a diverse set of object concepts. We find evidence that the network has learned many object classes that play crucial roles in classifying scene classes. Second, we use a similar analytic method to analyze a generative adversarial network (GAN) model trained to generate scenes. By analyzing changes made when small sets of units are activated or deactivated, we find that objects can be added and removed from the output scenes while adapting to the context. Finally, we apply our analytic framework to understanding adversarial attacks and to semantic image editing.
The Hessian Penalty: A Weak Prior for Unsupervised Disentanglement
Aug 24, 2020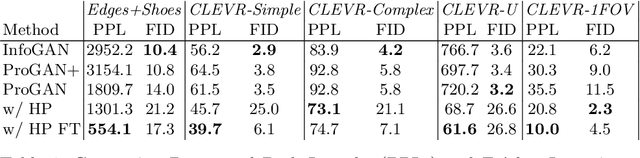

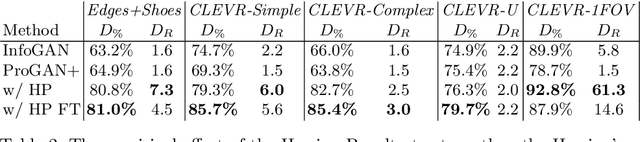
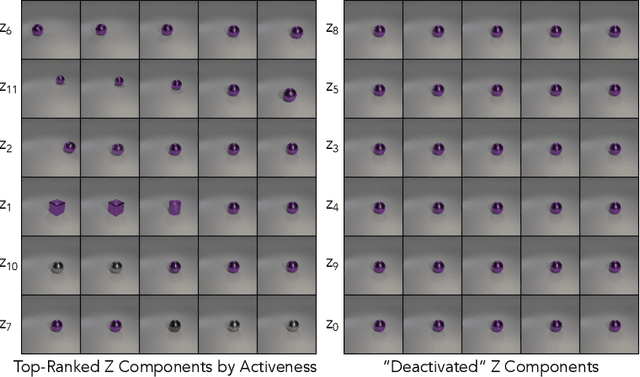
Existing disentanglement methods for deep generative models rely on hand-picked priors and complex encoder-based architectures. In this paper, we propose the Hessian Penalty, a simple regularization term that encourages the Hessian of a generative model with respect to its input to be diagonal. We introduce a model-agnostic, unbiased stochastic approximation of this term based on Hutchinson's estimator to compute it efficiently during training. Our method can be applied to a wide range of deep generators with just a few lines of code. We show that training with the Hessian Penalty often causes axis-aligned disentanglement to emerge in latent space when applied to ProGAN on several datasets. Additionally, we use our regularization term to identify interpretable directions in BigGAN's latent space in an unsupervised fashion. Finally, we provide empirical evidence that the Hessian Penalty encourages substantial shrinkage when applied to over-parameterized latent spaces.