 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree ways to improve feature alignment for open vocabulary detection
Mar 23, 2023
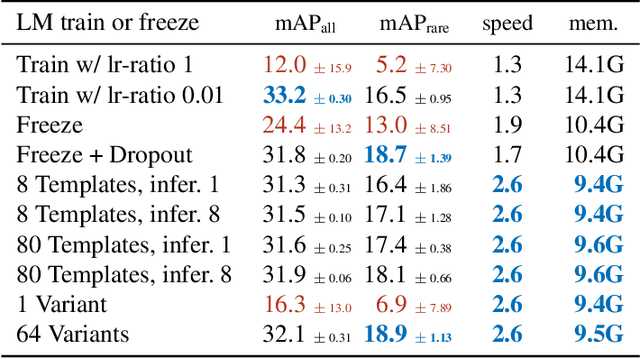
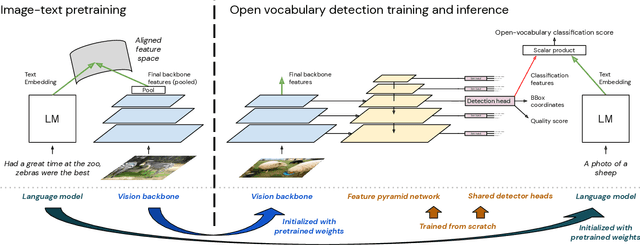
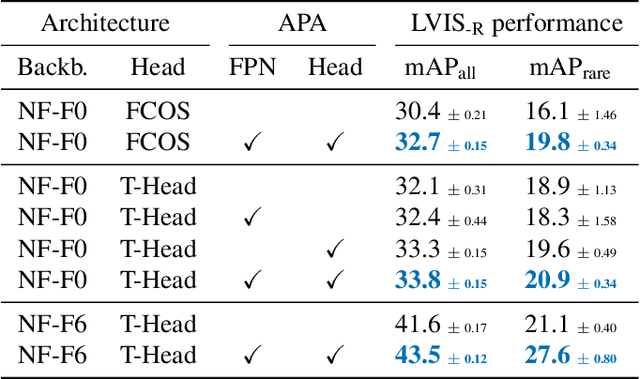
The core problem in zero-shot open vocabulary detection is how to align visual and text features, so that the detector performs well on unseen classes. Previous approaches train the feature pyramid and detection head from scratch, which breaks the vision-text feature alignment established during pretraining, and struggles to prevent the language model from forgetting unseen classes. We propose three methods to alleviate these issues. Firstly, a simple scheme is used to augment the text embeddings which prevents overfitting to a small number of classes seen during training, while simultaneously saving memory and computation. Secondly, the feature pyramid network and the detection head are modified to include trainable gated shortcuts, which encourages vision-text feature alignment and guarantees it at the start of detection training. Finally, a self-training approach is used to leverage a larger corpus of image-text pairs thus improving detection performance on classes with no human annotated bounding boxes. Our three methods are evaluated on the zero-shot version of the LVIS benchmark, each of them showing clear and significant benefits. Our final network achieves the new stateof-the-art on the mAP-all metric and demonstrates competitive performance for mAP-rare, as well as superior transfer to COCO and Objects365.
Mass-Editing Memory in a Transformer
Oct 13, 2022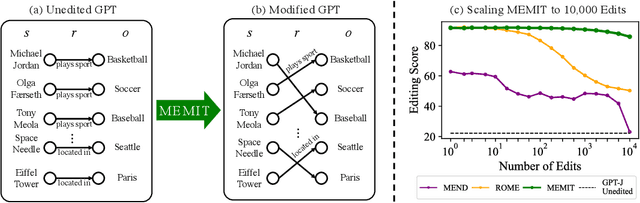
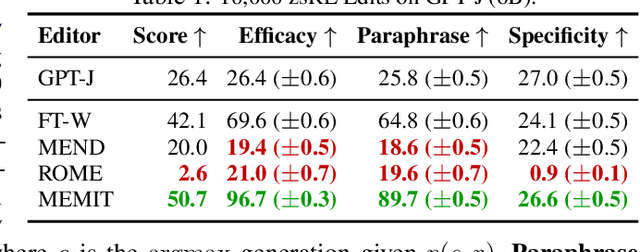
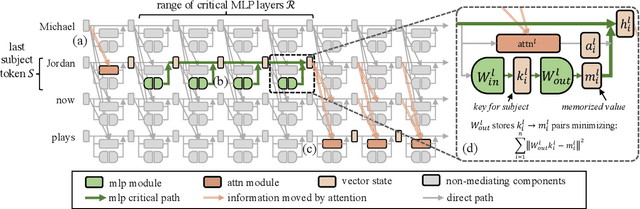
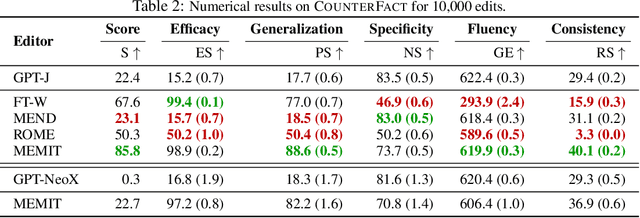
Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limited to updating single associations. We develop MEMIT, a method for directly updating a language model with many memories, demonstrating experimentally that it can scale up to thousands of associations for GPT-J (6B) and GPT-NeoX (20B), exceeding prior work by orders of magnitude. Our code and data are at https://memit.baulab.info.
Deepfake Caricatures: Amplifying attention to artifacts increases deepfake detection by humans and machines
Jun 02, 2022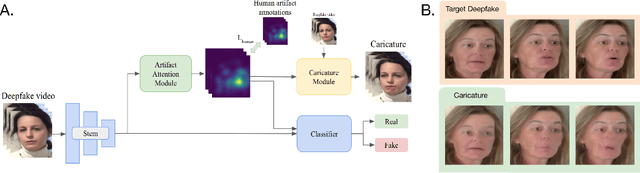
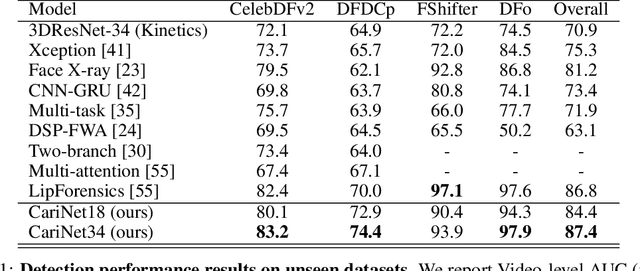

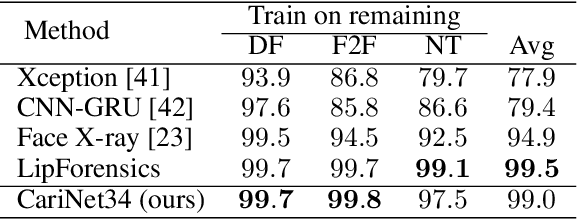
Deepfakes pose a serious threat to our digital society by fueling the spread of misinformation. It is essential to develop techniques that both detect them, and effectively alert the human user to their presence. Here, we introduce a novel deepfake detection framework that meets both of these needs. Our approach learns to generate attention maps of video artifacts, semi-supervised on human annotations. These maps make two contributions. First, they improve the accuracy and generalizability of a deepfake classifier, demonstrated across several deepfake detection datasets. Second, they allow us to generate an intuitive signal for the human user, in the form of "Deepfake Caricatures": transformations of the original deepfake video where attended artifacts are exacerbated to improve human recognition. Our approach, based on a mixture of human and artificial supervision, aims to further the development of countermeasures against fake visual content, and grants humans the ability to make their own judgment when presented with dubious visual media.
Robust Cross-Modal Representation Learning with Progressive Self-Distillation
Apr 10, 2022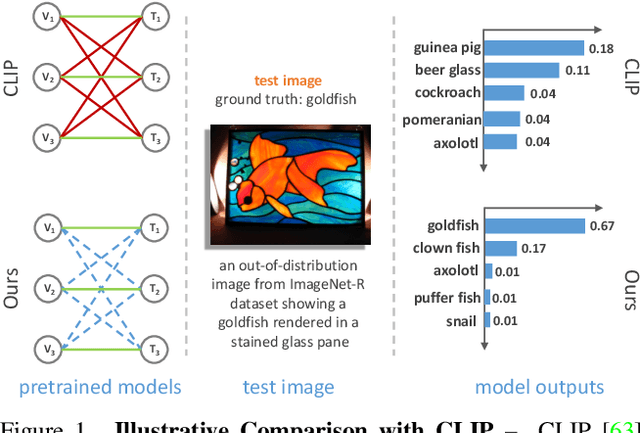

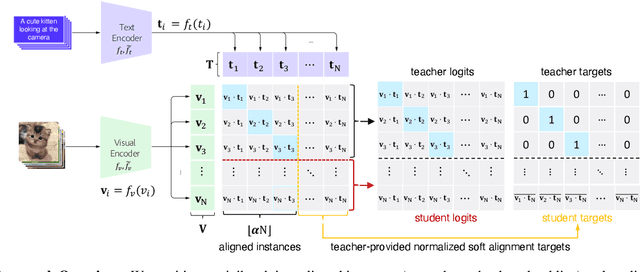
The learning objective of vision-language approach of CLIP does not effectively account for the noisy many-to-many correspondences found in web-harvested image captioning datasets, which contributes to its compute and data inefficiency. To address this challenge, we introduce a novel training framework based on cross-modal contrastive learning that uses progressive self-distillation and soft image-text alignments to more efficiently learn robust representations from noisy data. Our model distills its own knowledge to dynamically generate soft-alignment targets for a subset of images and captions in every minibatch, which are then used to update its parameters. Extensive evaluation across 14 benchmark datasets shows that our method consistently outperforms its CLIP counterpart in multiple settings, including: (a) zero-shot classification, (b) linear probe transfer, and (c) image-text retrieval, without incurring added computational cost. Analysis using an ImageNet-based robustness test-bed reveals that our method offers better effective robustness to natural distribution shifts compared to both ImageNet-trained models and CLIP itself. Lastly, pretraining with datasets spanning two orders of magnitude in size shows that our improvements over CLIP tend to scale with number of training examples.
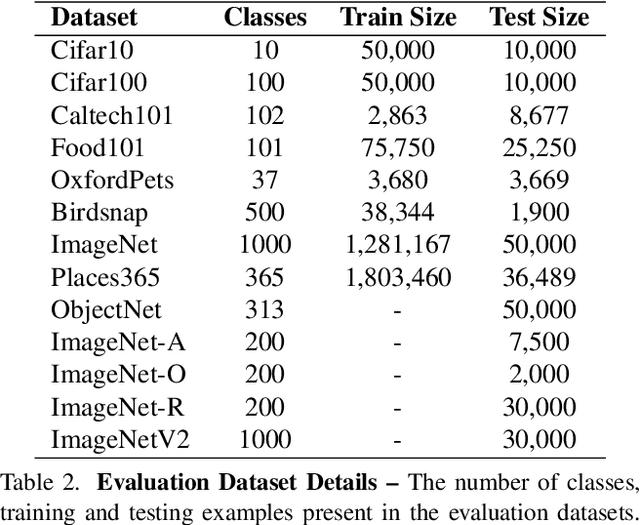
Locating and Editing Factual Knowledge in GPT
Feb 10, 2022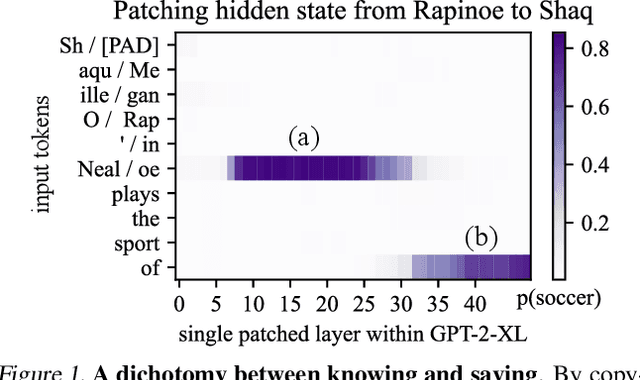
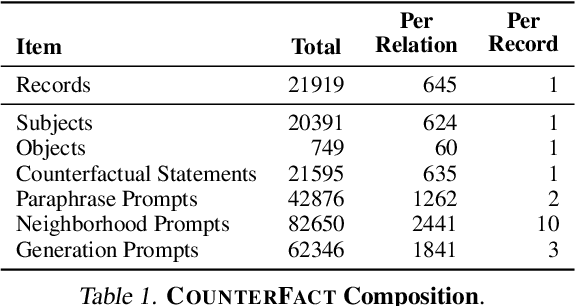

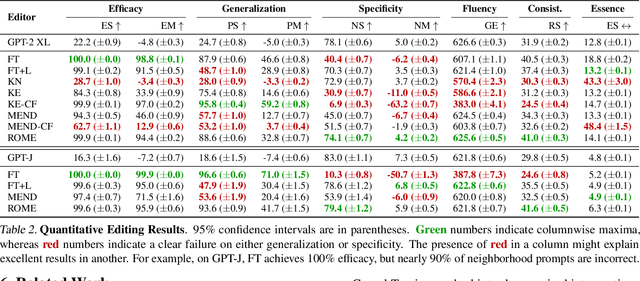
We investigate the mechanisms underlying factual knowledge recall in autoregressive transformer language models. First, we develop a causal intervention for identifying neuron activations capable of altering a model's factual predictions. Within large GPT-style models, this reveals two distinct sets of neurons that we hypothesize correspond to knowing an abstract fact and saying a concrete word, respectively. This insight inspires the development of ROME, a novel method for editing facts stored in model weights. For evaluation, we assemble CounterFact, a dataset of over twenty thousand counterfactuals and tools to facilitate sensitive measurements of knowledge editing. Using CounterFact, we confirm the distinction between saying and knowing neurons, and we find that ROME achieves state-of-the-art performance in knowledge editing compared to other methods. An interactive demo notebook, full code implementation, and the dataset are available at https://rome.baulab.info/.
Contrastive Feature Loss for Image Prediction
Nov 12, 2021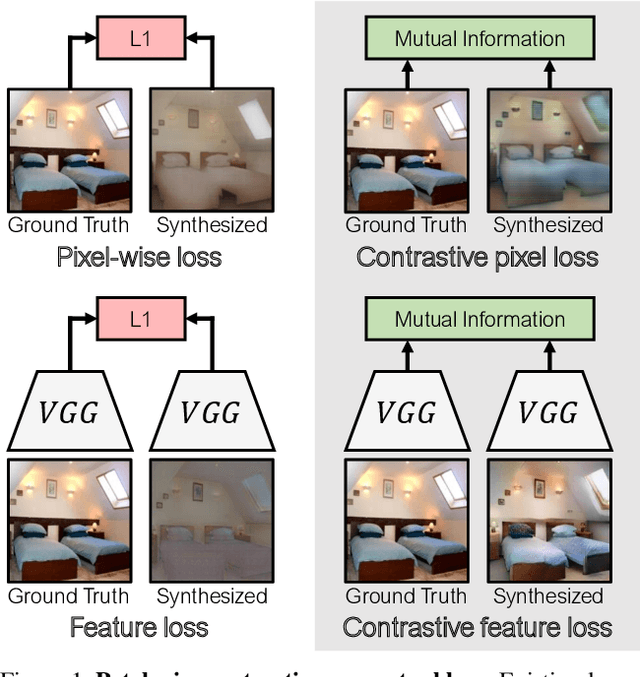
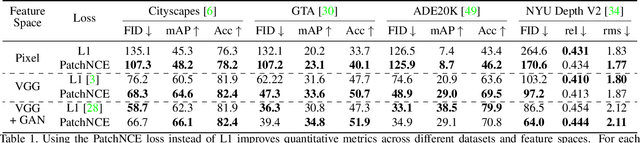
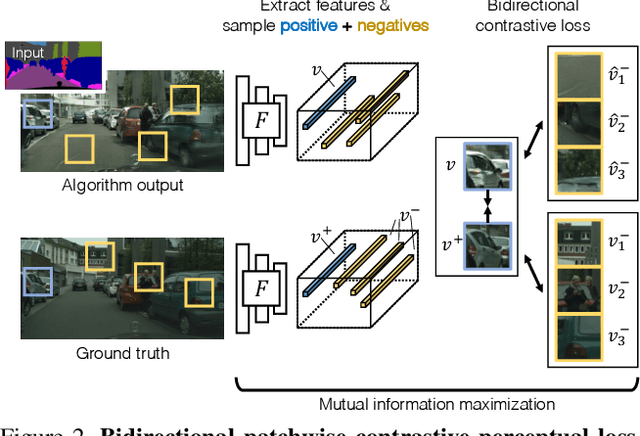
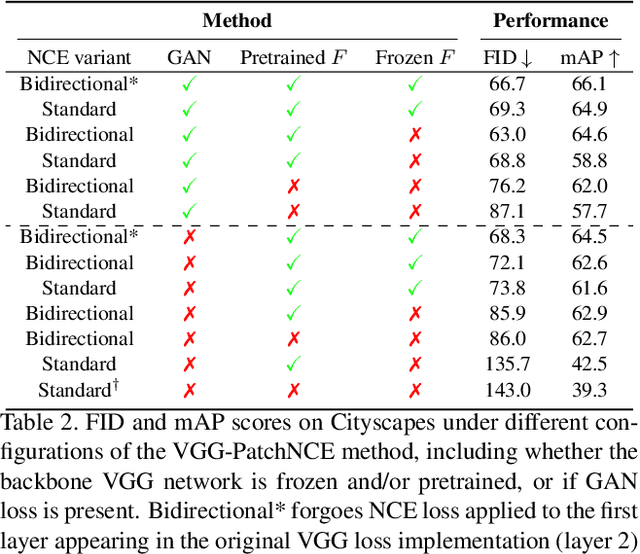
Training supervised image synthesis models requires a critic to compare two images: the ground truth to the result. Yet, this basic functionality remains an open problem. A popular line of approaches uses the L1 (mean absolute error) loss, either in the pixel or the feature space of pretrained deep networks. However, we observe that these losses tend to produce overly blurry and grey images, and other techniques such as GANs need to be employed to fight these artifacts. In this work, we introduce an information theory based approach to measuring similarity between two images. We argue that a good reconstruction should have high mutual information with the ground truth. This view enables learning a lightweight critic to "calibrate" a feature space in a contrastive manner, such that reconstructions of corresponding spatial patches are brought together, while other patches are repulsed. We show that our formulation immediately boosts the perceptual realism of output images when used as a drop-in replacement for the L1 loss, with or without an additional GAN loss.
Paint by Word
Mar 24, 2021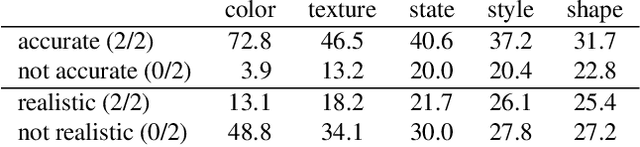
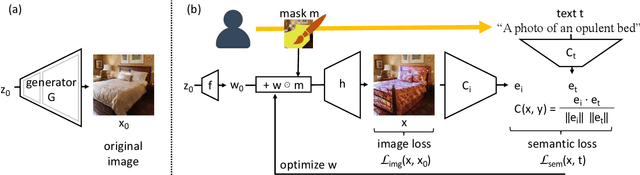

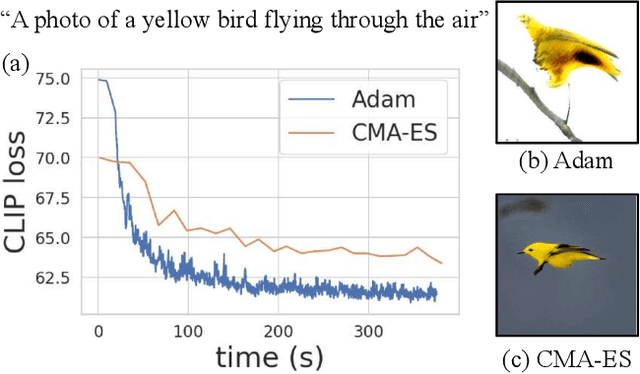
We investigate the problem of zero-shot semantic image painting. Instead of painting modifications into an image using only concrete colors or a finite set of semantic concepts, we ask how to create semantic paint based on open full-text descriptions: our goal is to be able to point to a location in a synthesized image and apply an arbitrary new concept such as "rustic" or "opulent" or "happy dog." To do this, our method combines a state-of-the art generative model of realistic images with a state-of-the-art text-image semantic similarity network. We find that, to make large changes, it is important to use non-gradient methods to explore latent space, and it is important to relax the computations of the GAN to target changes to a specific region. We conduct user studies to compare our methods to several baselines.
VA-RED$^2$: Video Adaptive Redundancy Reduction
Feb 15, 2021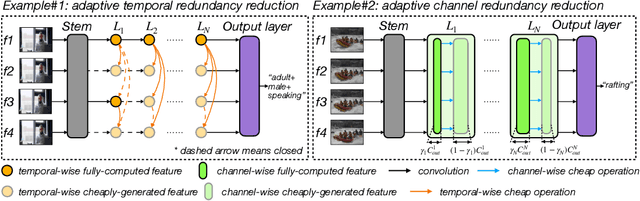
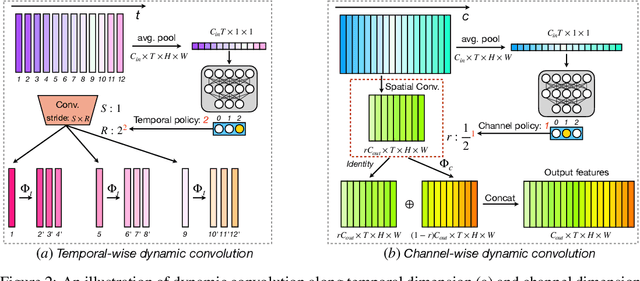
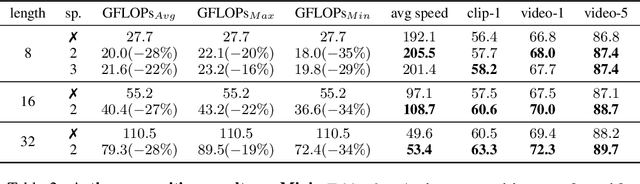
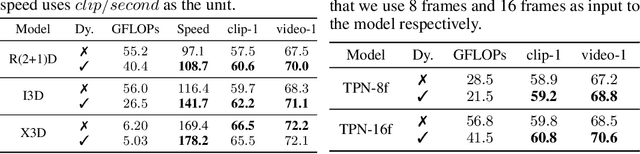
Performing inference on deep learning models for videos remains a challenge due to the large amount of computational resources required to achieve robust recognition. An inherent property of real-world videos is the high correlation of information across frames which can translate into redundancy in either temporal or spatial feature maps of the models, or both. The type of redundant features depends on the dynamics and type of events in the video: static videos have more temporal redundancy while videos focusing on objects tend to have more channel redundancy. Here we present a redundancy reduction framework, termed VA-RED$^2$, which is input-dependent. Specifically, our VA-RED$^2$ framework uses an input-dependent policy to decide how many features need to be computed for temporal and channel dimensions. To keep the capacity of the original model, after fully computing the necessary features, we reconstruct the remaining redundant features from those using cheap linear operations. We learn the adaptive policy jointly with the network weights in a differentiable way with a shared-weight mechanism, making it highly efficient. Extensive experiments on multiple video datasets and different visual tasks show that our framework achieves $20\% - 40\%$ reduction in computation (FLOPs) when compared to state-of-the-art methods without any performance loss. Project page: http://people.csail.mit.edu/bpan/va-red/.
We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos
Aug 12, 2020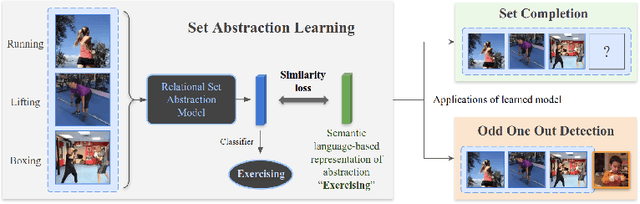
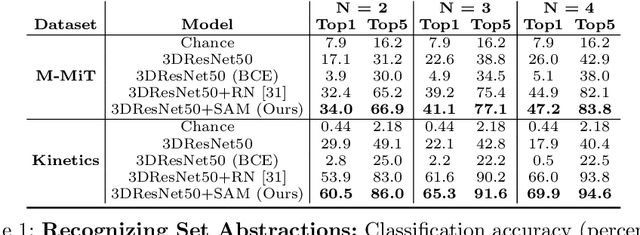

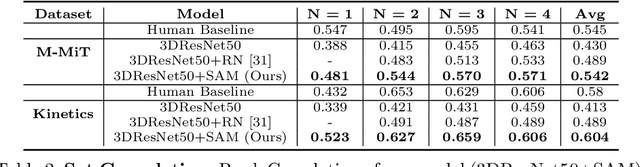
Identifying common patterns among events is a key ability in human and machine perception, as it underlies intelligent decision making. We propose an approach for learning semantic relational set abstractions on videos, inspired by human learning. We combine visual features with natural language supervision to generate high-level representations of similarities across a set of videos. This allows our model to perform cognitive tasks such as set abstraction (which general concept is in common among a set of videos?), set completion (which new video goes well with the set?), and odd one out detection (which video does not belong to the set?). Experiments on two video benchmarks, Kinetics and Multi-Moments in Time, show that robust and versatile representations emerge when learning to recognize commonalities among sets. We compare our model to several baseline algorithms and show that significant improvements result from explicitly learning relational abstractions with semantic supervision.
Multi-Moments in Time: Learning and Interpreting Models for Multi-Action Video Understanding
Nov 04, 2019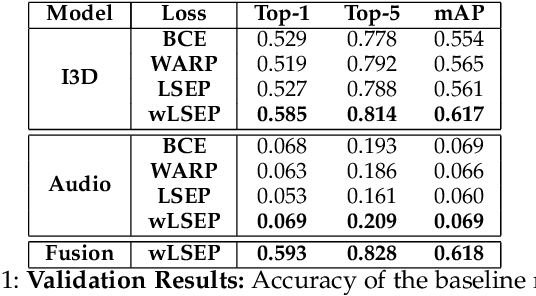
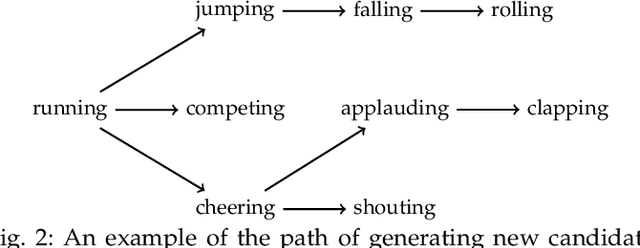


An event happening in the world is often made of different activities and actions that can unfold simultaneously or sequentially within a few seconds. However, most large-scale datasets built to train models for action recognition provide a single label per video clip. Consequently, models can be incorrectly penalized for classifying actions that exist in the videos but are not explicitly labeled and do not learn the full spectrum of information that would be mandatory to more completely comprehend different events and eventually learn causality between them. Towards this goal, we augmented the existing video dataset, Moments in Time (MiT), to include over two million action labels for over one million three second videos. This multi-label dataset introduces novel challenges on how to train and analyze models for multi-action detection. Here, we present baseline results for multi-action recognition using loss functions adapted for long tail multi-label learning and provide improved methods for visualizing and interpreting models trained for multi-label action detection.