 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Data-driven Human Responsibility Management System
Dec 06, 2020
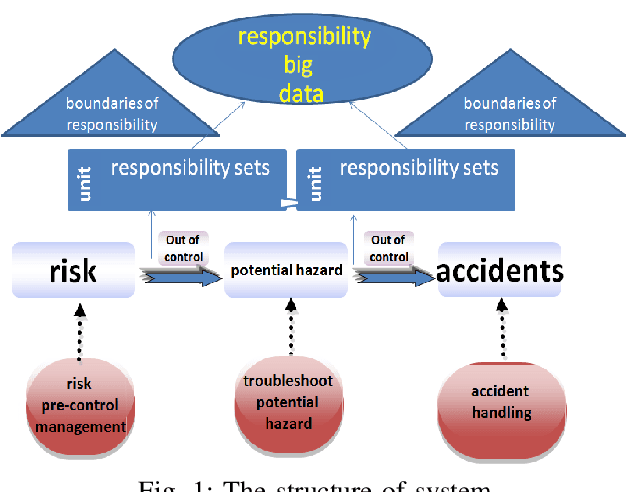
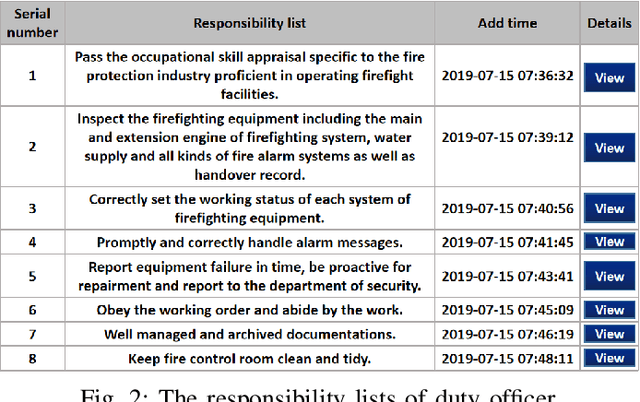

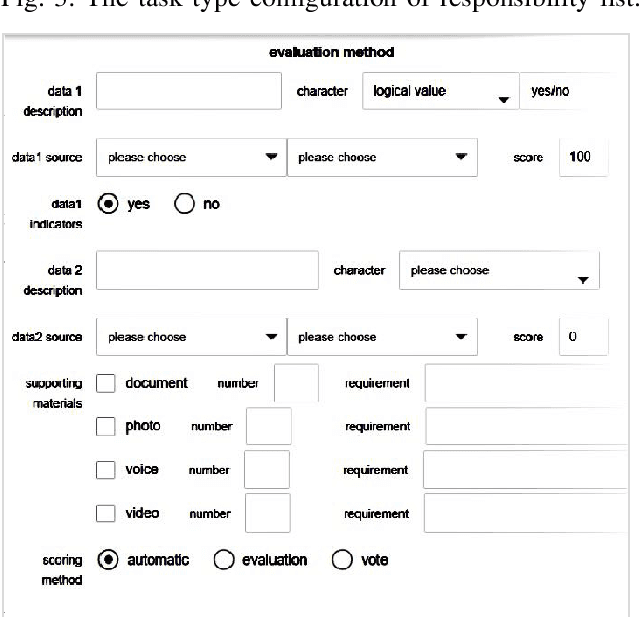
An ideal safe workplace is described as a place where staffs fulfill responsibilities in a well-organized order, potential hazardous events are being monitored in real-time, as well as the number of accidents and relevant damages are minimized. However, occupational-related death and injury are still increasing and have been highly attended in the last decades due to the lack of comprehensive safety management. A smart safety management system is therefore urgently needed, in which the staffs are instructed to fulfill responsibilities as well as automating risk evaluations and alerting staffs and departments when needed. In this paper, a smart system for safety management in the workplace based on responsibility big data analysis and the internet of things (IoT) are proposed. The real world implementation and assessment demonstrate that the proposed systems have superior accountability performance and improve the responsibility fulfillment through real-time supervision and self-reminder.
Symmetry-Aware Reservoir Computing
Jan 30, 2021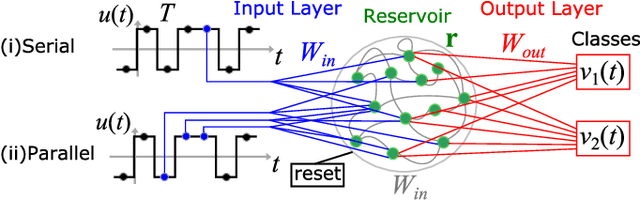
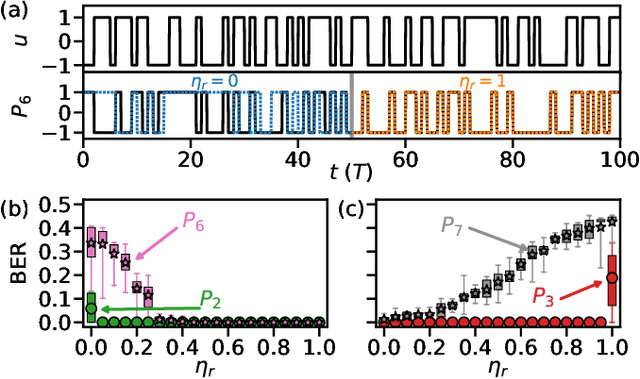
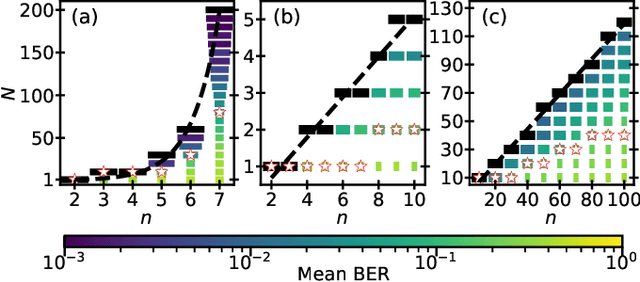
We demonstrate that matching the symmetry properties of a reservoir computer (RC) to the data being processed can dramatically increase its processing power. We apply our method to the parity task, a challenging benchmark problem, which highlights the benefits of symmetry matching. Our method outperforms all other approaches on this task, even artificial neural networks (ANN) hand crafted for this problem. The symmetry-aware RC can obtain zero error using an exponentially reduced number of artificial neurons and training data, greatly speeding up the time-to-result. We anticipate that generalizations of our procedure will have widespread applicability in information processing with ANNs.
Sliding Mode Learning Control of Uncertain Nonlinear Systems with Lyapunov Stability Analysis
Mar 21, 2021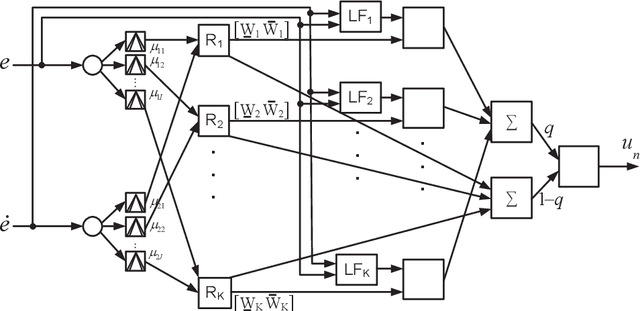
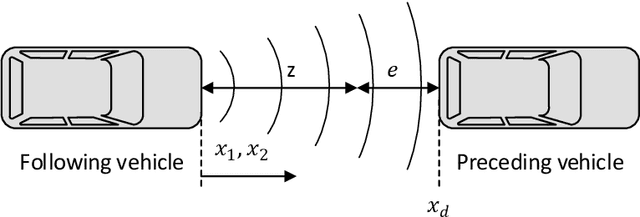
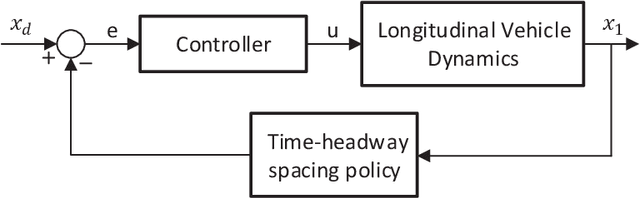
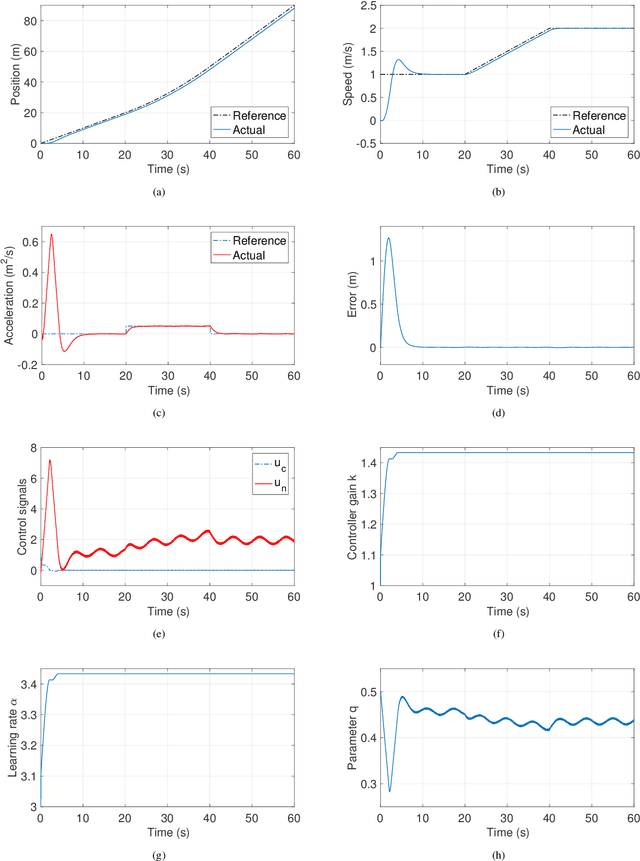
This paper addresses to Sliding Mode Learning Control (SMLC) of uncertain nonlinear systems with Lyapunov stability analysis. In the control scheme, a conventional control term is used to provide the system stability in compact space while a Type-2 Neuro-Fuzzy Controller (T2NFC) learns system behavior so that the T2NFC takes the overall control of the system completely in a very short time period. The stability of the sliding mode learning algorithm was proven in literature; however, it is so restrictive for systems without the overall system stability. To address this shortcoming, a novel control structure with a novel sliding surface is proposed in this paper and the stability of the overall system is proven for nth-order uncertain nonlinear systems. To investigate the capability and effectiveness of the proposed learning and control algorithms, the simulation studies have been achieved under noisy conditions. The simulation results confirm that the developed SMLC algorithm can learn the system behavior in the absence of any mathematical model knowledge and exhibit robust control performance against external disturbances.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 13, 2021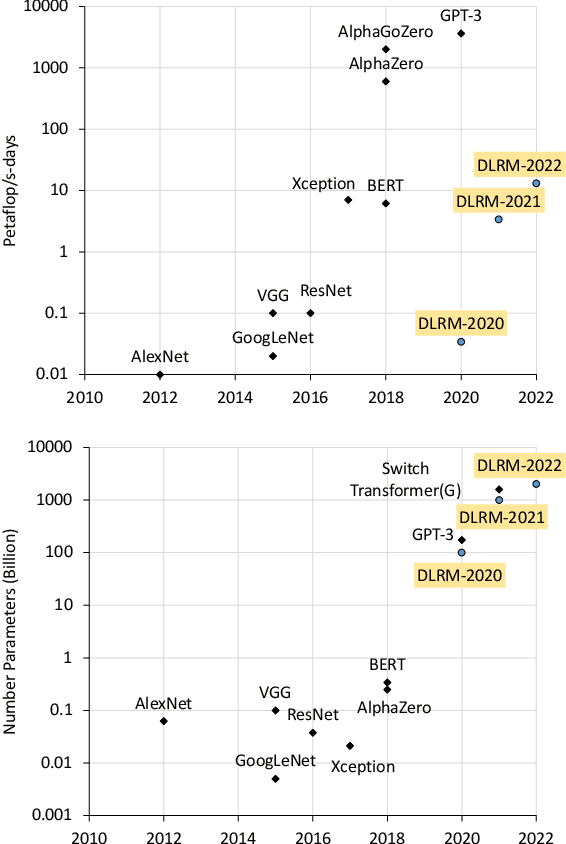

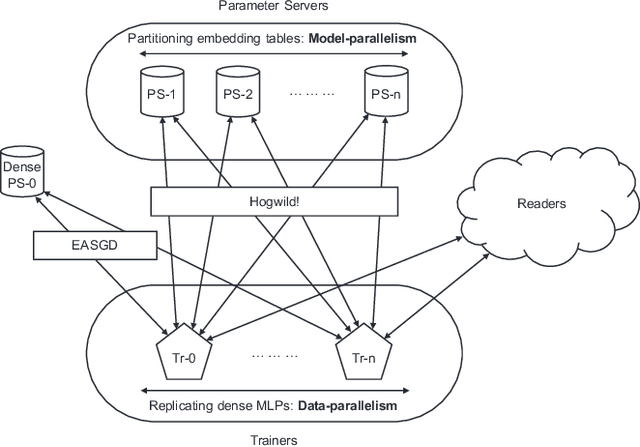
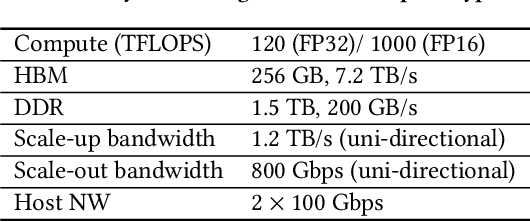
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
MIDeepSeg: Minimally Interactive Segmentation of Unseen Objects from Medical Images Using Deep Learning
Apr 25, 2021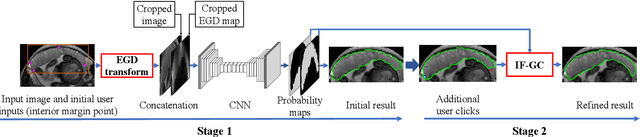
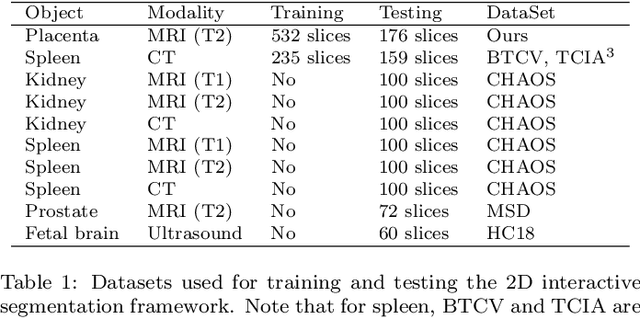
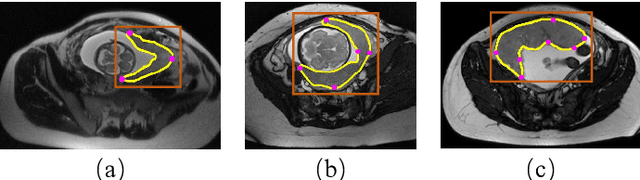
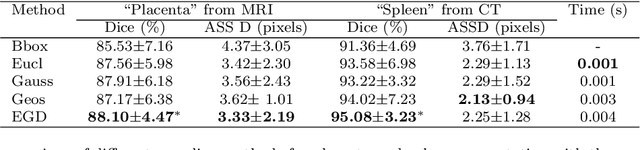
Segmentation of organs or lesions from medical images plays an essential role in many clinical applications such as diagnosis and treatment planning. Though Convolutional Neural Networks (CNN) have achieved the state-of-the-art performance for automatic segmentation, they are often limited by the lack of clinically acceptable accuracy and robustness in complex cases. Therefore, interactive segmentation is a practical alternative to these methods. However, traditional interactive segmentation methods require a large amount of user interactions, and recently proposed CNN-based interactive segmentation methods are limited by poor performance on previously unseen objects. To solve these problems, we propose a novel deep learning-based interactive segmentation method that not only has high efficiency due to only requiring clicks as user inputs but also generalizes well to a range of previously unseen objects. Specifically, we first encode user-provided interior margin points via our proposed exponentialized geodesic distance that enables a CNN to achieve a good initial segmentation result of both previously seen and unseen objects, then we use a novel information fusion method that combines the initial segmentation with only few additional user clicks to efficiently obtain a refined segmentation. We validated our proposed framework through extensive experiments on 2D and 3D medical image segmentation tasks with a wide range of previous unseen objects that were not present in the training set. Experimental results showed that our proposed framework 1) achieves accurate results with fewer user interactions and less time compared with state-of-the-art interactive frameworks and 2) generalizes well to previously unseen objects.
Unsupervised Classification of Voiced Speech and Pitch Tracking Using Forward-Backward Kalman Filtering
Mar 01, 2021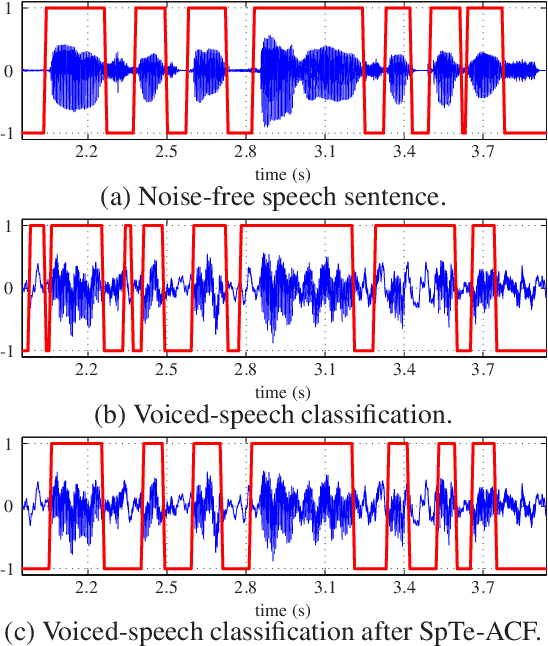
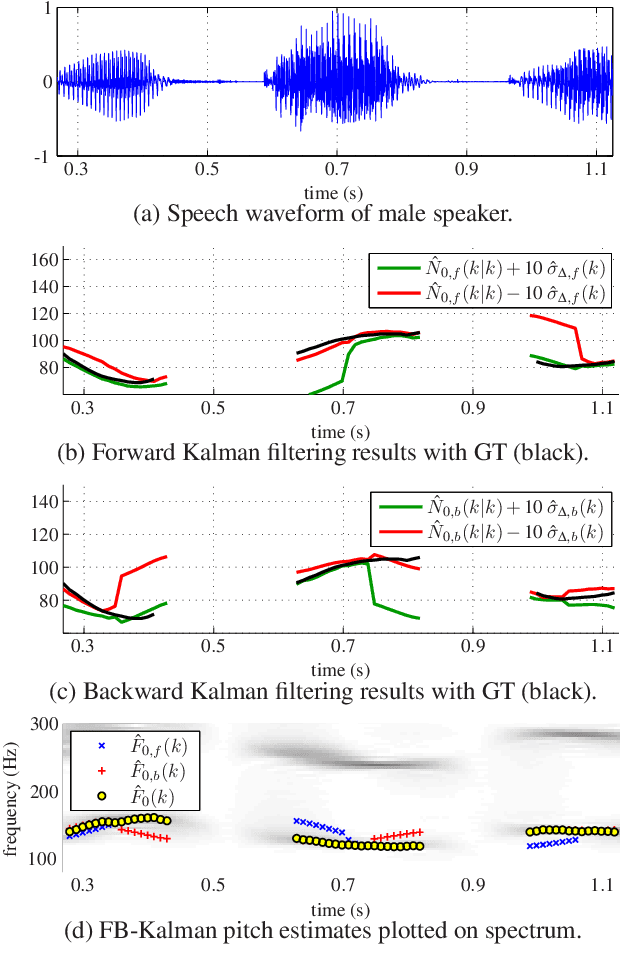
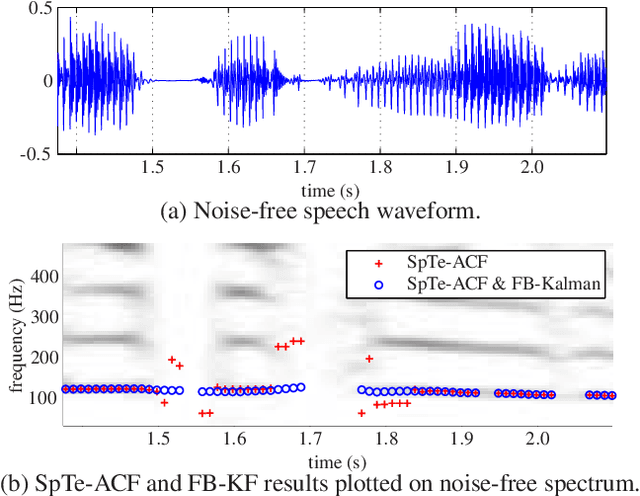
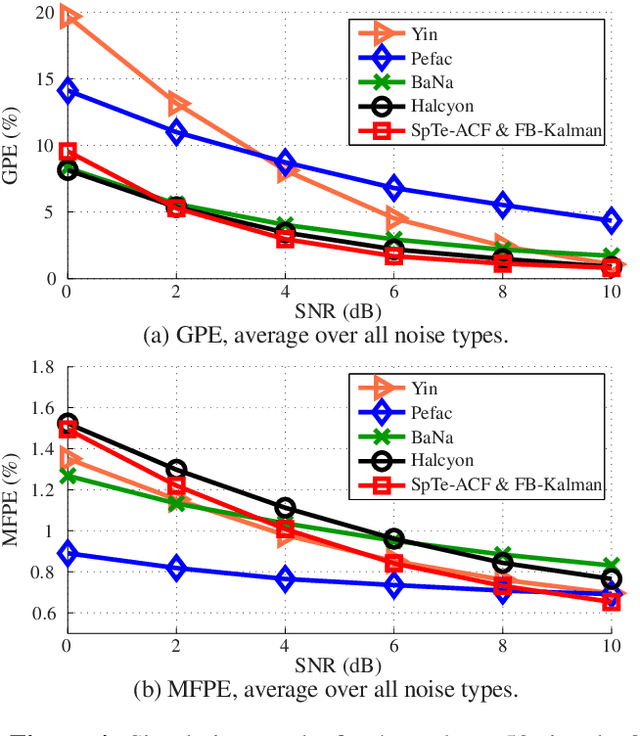
The detection of voiced speech, the estimation of the fundamental frequency, and the tracking of pitch values over time are crucial subtasks for a variety of speech processing techniques. Many different algorithms have been developed for each of the three subtasks. We present a new algorithm that integrates the three subtasks into a single procedure. The algorithm can be applied to pre-recorded speech utterances in the presence of considerable amounts of background noise. We combine a collection of standard metrics, such as the zero-crossing rate, for example, to formulate an unsupervised voicing classifier. The estimation of pitch values is accomplished with a hybrid autocorrelation-based technique. We propose a forward-backward Kalman filter to smooth the estimated pitch contour. In experiments, we are able to show that the proposed method compares favorably with current, state-of-the-art pitch detection algorithms.
Diverse Semantic Image Synthesis via Probability Distribution Modeling
Mar 11, 2021
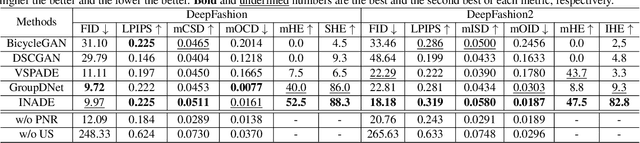
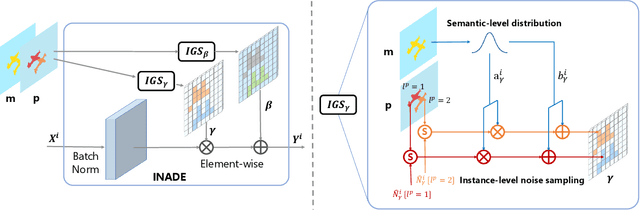
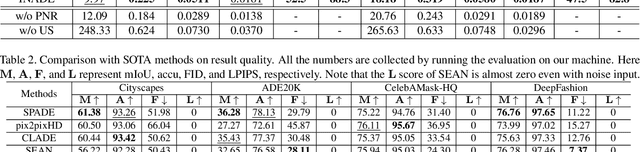
Semantic image synthesis, translating semantic layouts to photo-realistic images, is a one-to-many mapping problem. Though impressive progress has been recently made, diverse semantic synthesis that can efficiently produce semantic-level multimodal results, still remains a challenge. In this paper, we propose a novel diverse semantic image synthesis framework from the perspective of semantic class distributions, which naturally supports diverse generation at semantic or even instance level. We achieve this by modeling class-level conditional modulation parameters as continuous probability distributions instead of discrete values, and sampling per-instance modulation parameters through instance-adaptive stochastic sampling that is consistent across the network. Moreover, we propose prior noise remapping, through linear perturbation parameters encoded from paired references, to facilitate supervised training and exemplar-based instance style control at test time. Extensive experiments on multiple datasets show that our method can achieve superior diversity and comparable quality compared to state-of-the-art methods. Code will be available at \url{https://github.com/tzt101/INADE.git}
Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates
Feb 18, 2021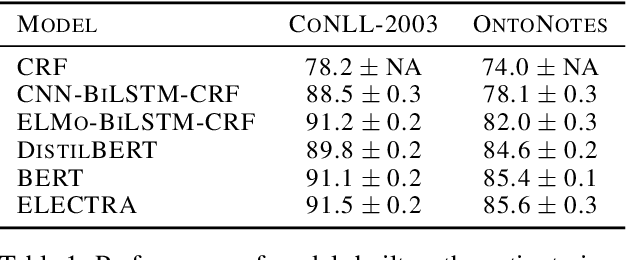
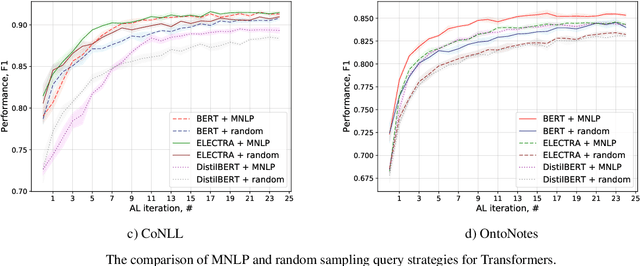
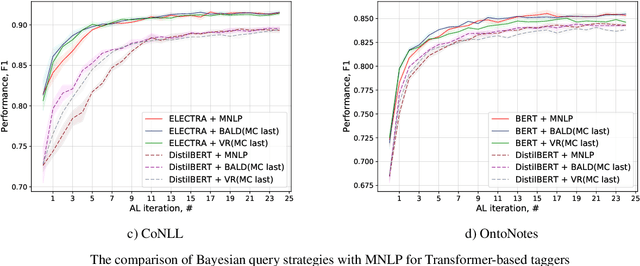
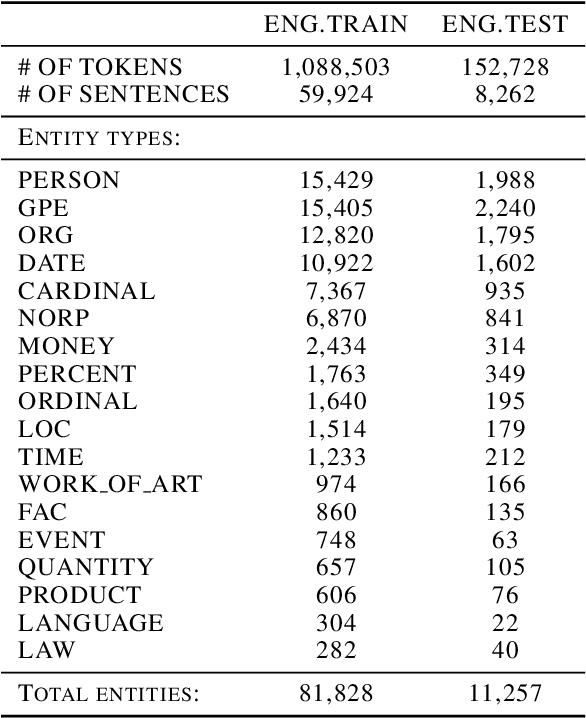
Annotating training data for sequence tagging of texts is usually very time-consuming. Recent advances in transfer learning for natural language processing in conjunction with active learning open the possibility to significantly reduce the necessary annotation budget. We are the first to thoroughly investigate this powerful combination for the sequence tagging task. We conduct an extensive empirical study of various Bayesian uncertainty estimation methods and Monte Carlo dropout options for deep pre-trained models in the active learning framework and find the best combinations for different types of models. Besides, we also demonstrate that to acquire instances during active learning, a full-size Transformer can be substituted with a distilled version, which yields better computational performance and reduces obstacles for applying deep active learning in practice.
Sill-Net: Feature Augmentation with Separated Illumination Representation
Feb 06, 2021

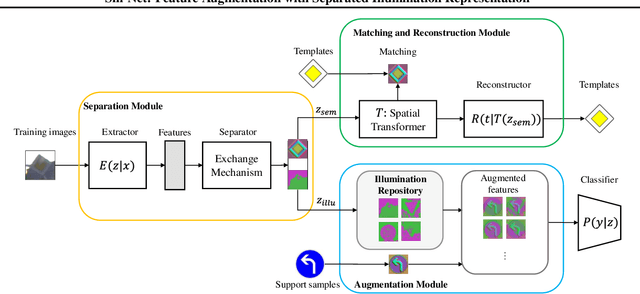

For visual object recognition tasks, the illumination variations can cause distinct changes in object appearance and thus confuse the deep neural network based recognition models. Especially for some rare illumination conditions, collecting sufficient training samples could be time-consuming and expensive. To solve this problem, in this paper we propose a novel neural network architecture called Separating-Illumination Network (Sill-Net). Sill-Net learns to separate illumination features from images, and then during training we augment training samples with these separated illumination features in the feature space. Experimental results demonstrate that our approach outperforms current state-of-the-art methods in several object classification benchmarks.
FIXAR: A Fixed-Point Deep Reinforcement Learning Platform with Quantization-Aware Training and Adaptive Parallelism
Feb 24, 2021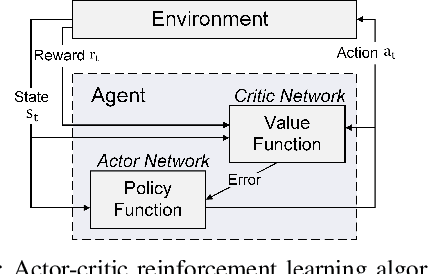
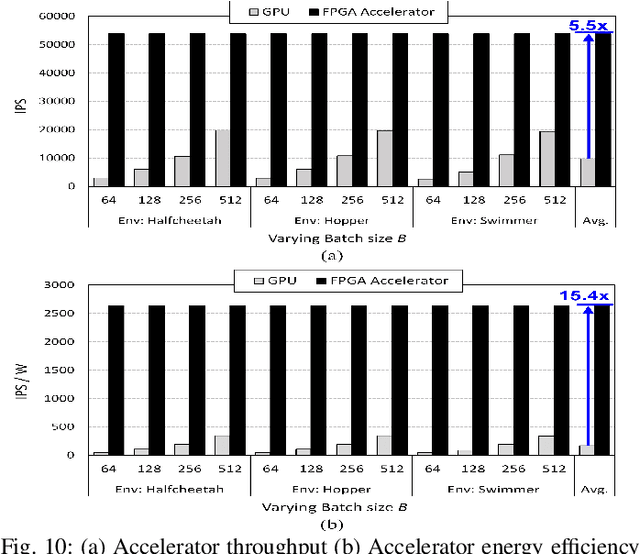
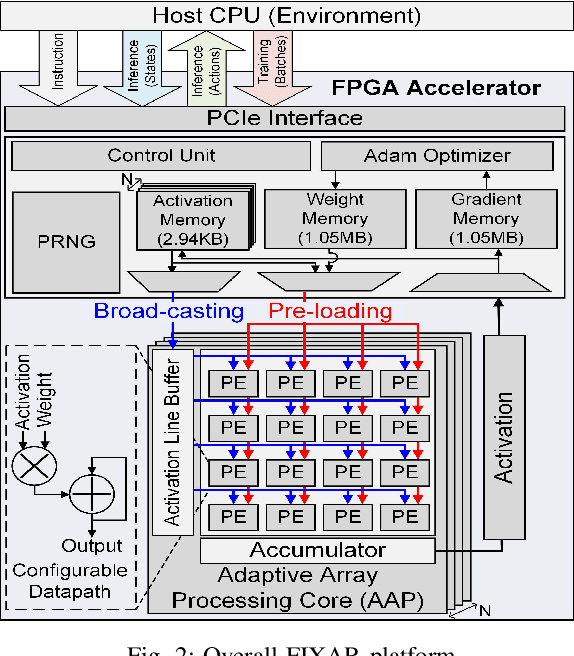
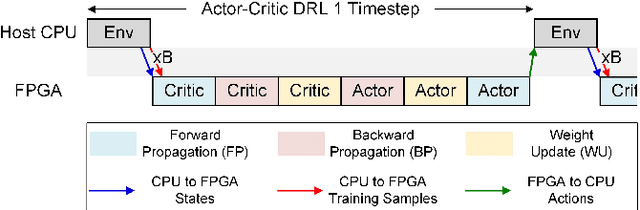
In this paper, we present a deep reinforcement learning platform named FIXAR which employs fixed-point data types and arithmetic units for the first time using a SW/HW co-design approach. Starting from 32-bit fixed-point data, Quantization-Aware Training (QAT) reduces its data precision based on the range of activations and performs retraining to minimize the reward degradation. FIXAR proposes the adaptive array processing core composed of configurable processing elements to support both intra-layer parallelism and intra-batch parallelism for high-throughput inference and training. Finally, FIXAR was implemented on Xilinx U50 and achieves 25293.3 inferences per second (IPS) training throughput and 2638.0 IPS/W accelerator efficiency, which is 2.7 times faster and 15.4 times more energy efficient than those of the CPU-GPU platform without any accuracy degradation.