 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MTrainS: Improving DLRM training efficiency using heterogeneous memories
Apr 19, 2023



Recommendation models are very large, requiring terabytes (TB) of memory during training. In pursuit of better quality, the model size and complexity grow over time, which requires additional training data to avoid overfitting. This model growth demands a large number of resources in data centers. Hence, training efficiency is becoming considerably more important to keep the data center power demand manageable. In Deep Learning Recommendation Models (DLRM), sparse features capturing categorical inputs through embedding tables are the major contributors to model size and require high memory bandwidth. In this paper, we study the bandwidth requirement and locality of embedding tables in real-world deployed models. We observe that the bandwidth requirement is not uniform across different tables and that embedding tables show high temporal locality. We then design MTrainS, which leverages heterogeneous memory, including byte and block addressable Storage Class Memory for DLRM hierarchically. MTrainS allows for higher memory capacity per node and increases training efficiency by lowering the need to scale out to multiple hosts in memory capacity bound use cases. By optimizing the platform memory hierarchy, we reduce the number of nodes for training by 4-8X, saving power and cost of training while meeting our target training performance.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021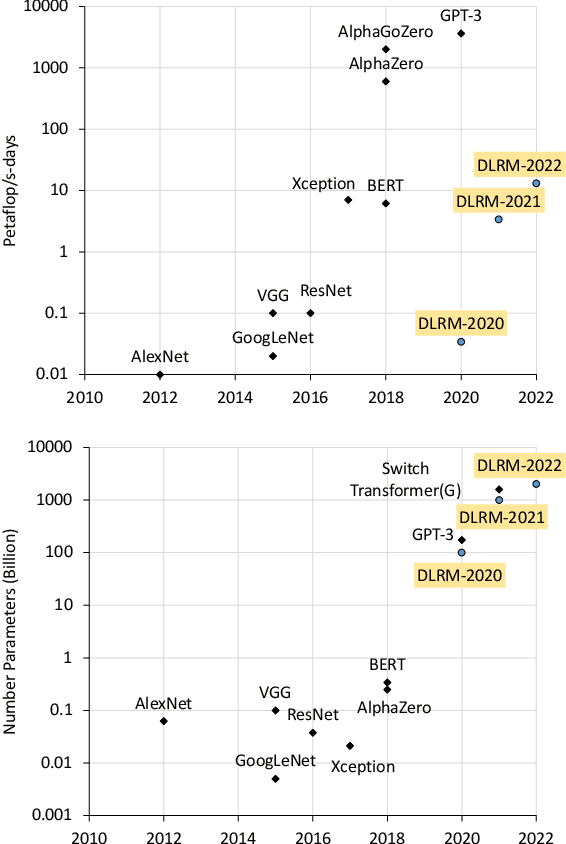

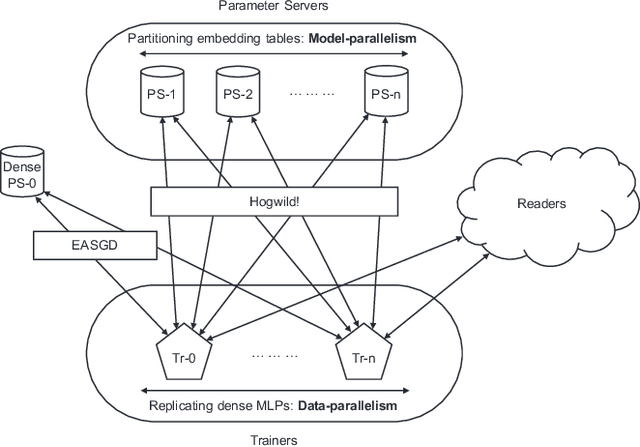
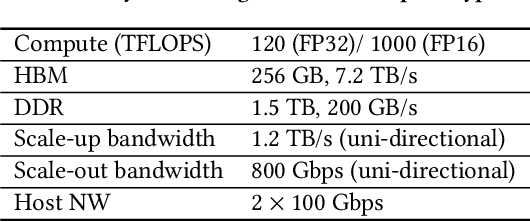
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Mixed-Precision Embedding Using a Cache
Oct 23, 2020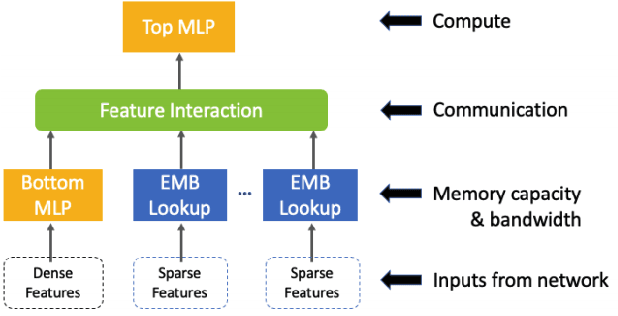

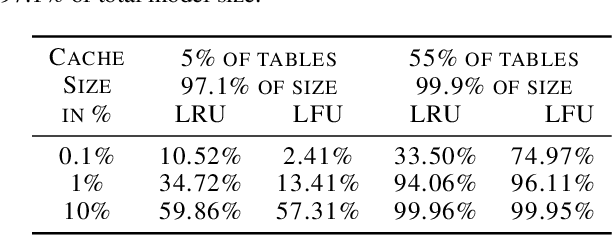
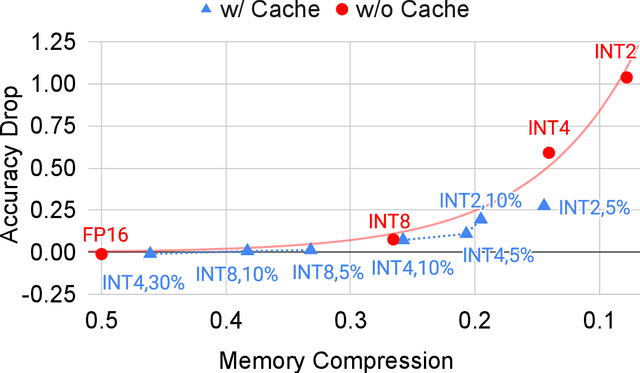
In recommendation systems, practitioners observed that increase in the number of embedding tables and their sizes often leads to significant improvement in model performances. Given this and the business importance of these models to major internet companies, embedding tables for personalization tasks have grown to terabyte scale and continue to grow at a significant rate. Meanwhile, these large-scale models are often trained with GPUs where high-performance memory is a scarce resource, thus motivating numerous work on embedding table compression during training. We propose a novel change to embedding tables using a cache memory architecture, where the majority of rows in an embedding is trained in low precision, and the most frequently or recently accessed rows cached and trained in full precision. The proposed architectural change works in conjunction with standard precision reduction and computer arithmetic techniques such as quantization and stochastic rounding. For an open source deep learning recommendation model (DLRM) running with Criteo-Kaggle dataset, we achieve 3x memory reduction with INT8 precision embedding tables and full-precision cache whose size are 5% of the embedding tables, while maintaining accuracy. For an industrial scale model and dataset, we achieve even higher >7x memory reduction with INT4 precision and cache size 1% of embedding tables, while maintaining accuracy, and 16% end-to-end training speedup by reducing GPU-to-host data transfers.
Hybrid Composition with IdleBlock: More Efficient Networks for Image Recognition
Nov 19, 2019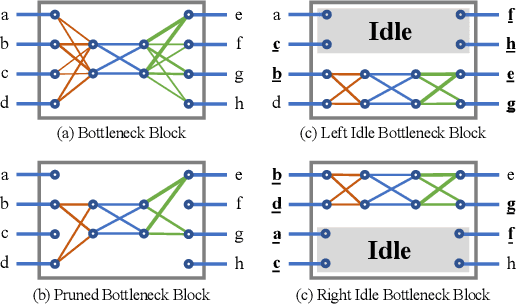
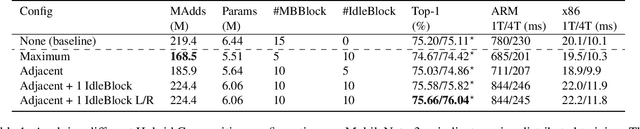
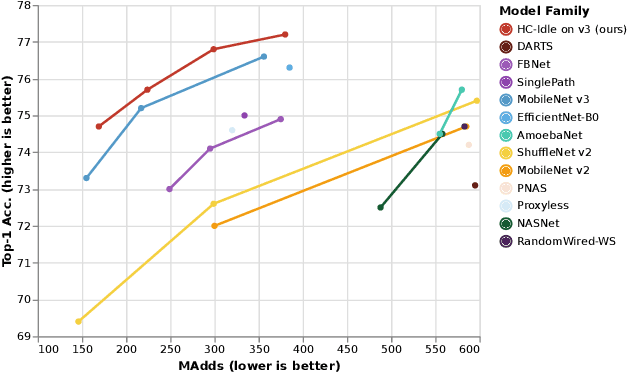
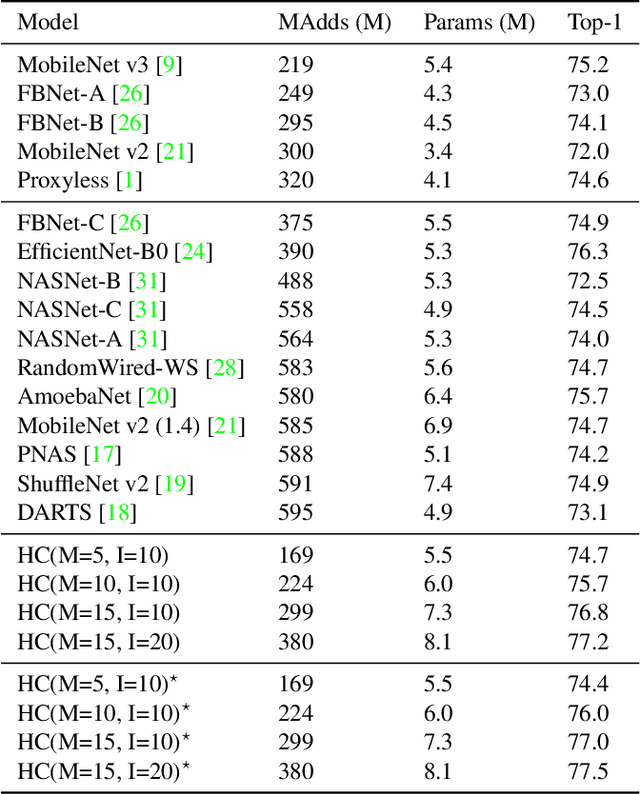
We propose a new building block, IdleBlock, which naturally prunes connections within the block. To fully utilize the IdleBlock we break the tradition of monotonic design in state-of-the-art networks, and introducing hybrid composition with IdleBlock. We study hybrid composition on MobileNet v3 and EfficientNet-B0, two of the most efficient networks. Without any neural architecture search, the deeper "MobileNet v3" with hybrid composition design surpasses possibly all state-of-the-art image recognition network designed by human experts or neural architecture search algorithms. Similarly, the hybridized EfficientNet-B0 networks are more efficient than previous state-of-the-art networks with similar computation budgets. These results suggest a new simpler and more efficient direction for network design and neural architecture search.
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018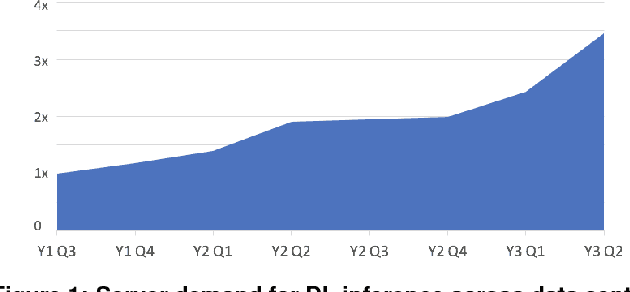
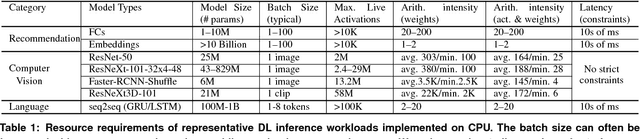
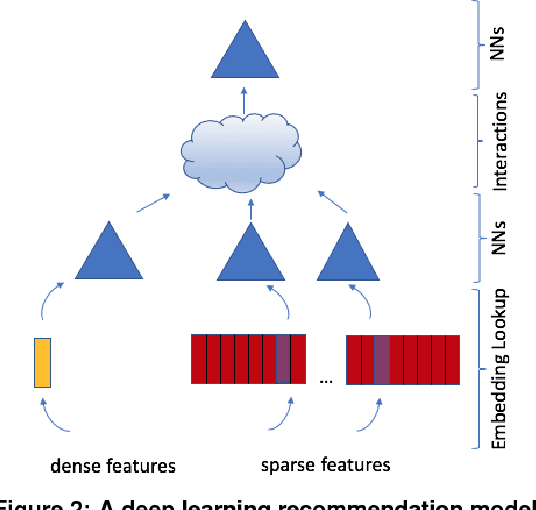
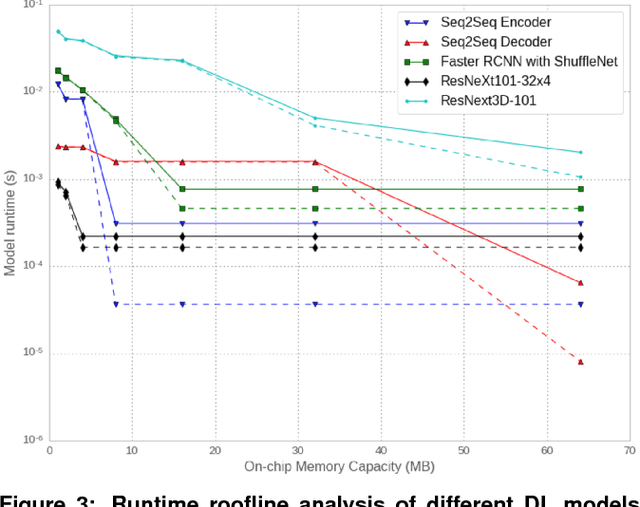
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.
On Periodic Functions as Regularizers for Quantization of Neural Networks
Nov 24, 2018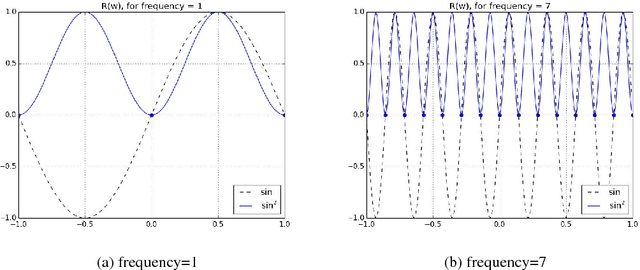
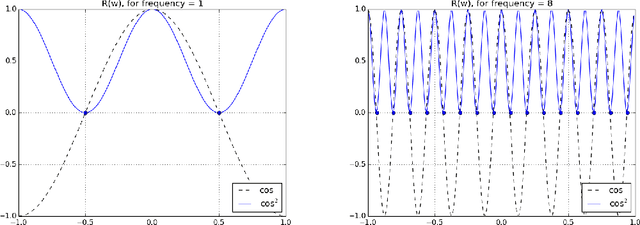
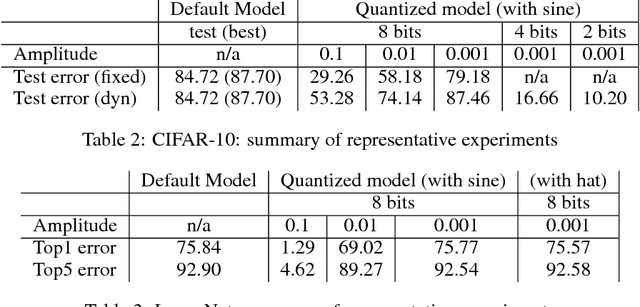
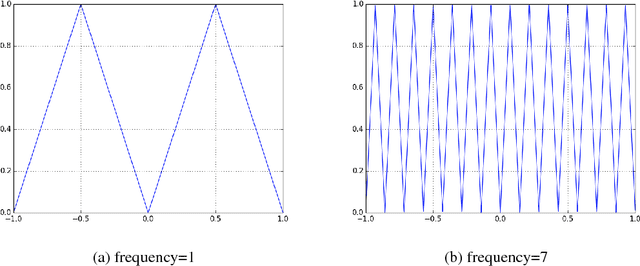
Deep learning models have been successfully used in computer vision and many other fields. We propose an unorthodox algorithm for performing quantization of the model parameters. In contrast with popular quantization schemes based on thresholds, we use a novel technique based on periodic functions, such as continuous trigonometric sine or cosine as well as non-continuous hat functions. We apply these functions component-wise and add the sum over the model parameters as a regularizer to the model loss during training. The frequency and amplitude hyper-parameters of these functions can be adjusted during training. The regularization pushes the weights into discrete points that can be encoded as integers. We show that using this technique the resulting quantized models exhibit the same accuracy as the original ones on CIFAR-10 and ImageNet datasets.
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Apr 30, 2018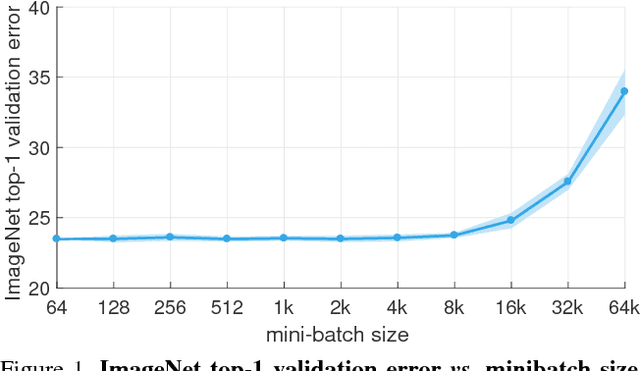
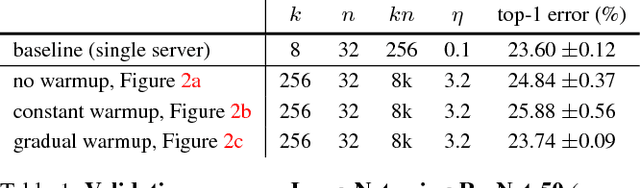
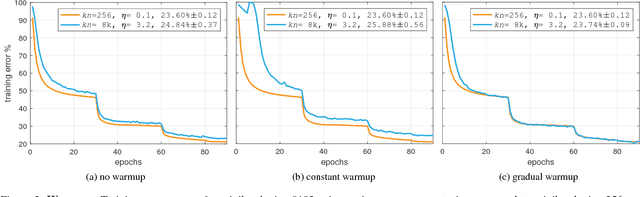

Deep learning thrives with large neural networks and large datasets. However, larger networks and larger datasets result in longer training times that impede research and development progress. Distributed synchronous SGD offers a potential solution to this problem by dividing SGD minibatches over a pool of parallel workers. Yet to make this scheme efficient, the per-worker workload must be large, which implies nontrivial growth in the SGD minibatch size. In this paper, we empirically show that on the ImageNet dataset large minibatches cause optimization difficulties, but when these are addressed the trained networks exhibit good generalization. Specifically, we show no loss of accuracy when training with large minibatch sizes up to 8192 images. To achieve this result, we adopt a hyper-parameter-free linear scaling rule for adjusting learning rates as a function of minibatch size and develop a new warmup scheme that overcomes optimization challenges early in training. With these simple techniques, our Caffe2-based system trains ResNet-50 with a minibatch size of 8192 on 256 GPUs in one hour, while matching small minibatch accuracy. Using commodity hardware, our implementation achieves ~90% scaling efficiency when moving from 8 to 256 GPUs. Our findings enable training visual recognition models on internet-scale data with high efficiency.
High performance ultra-low-precision convolutions on mobile devices
Dec 06, 2017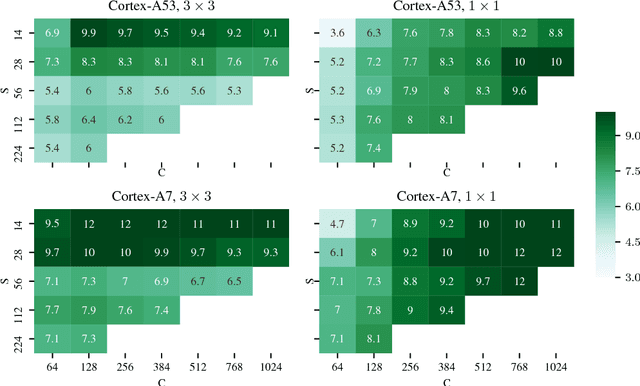
Many applications of mobile deep learning, especially real-time computer vision workloads, are constrained by computation power. This is particularly true for workloads running on older consumer phones, where a typical device might be powered by a single- or dual-core ARMv7 CPU. We provide an open-source implementation and a comprehensive analysis of (to our knowledge) the state of the art ultra-low-precision (<4 bit precision) implementation of the core primitives required for modern deep learning workloads on ARMv7 devices, and demonstrate speedups of 4x-20x over our additional state-of-the-art float32 and int8 baselines.