 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021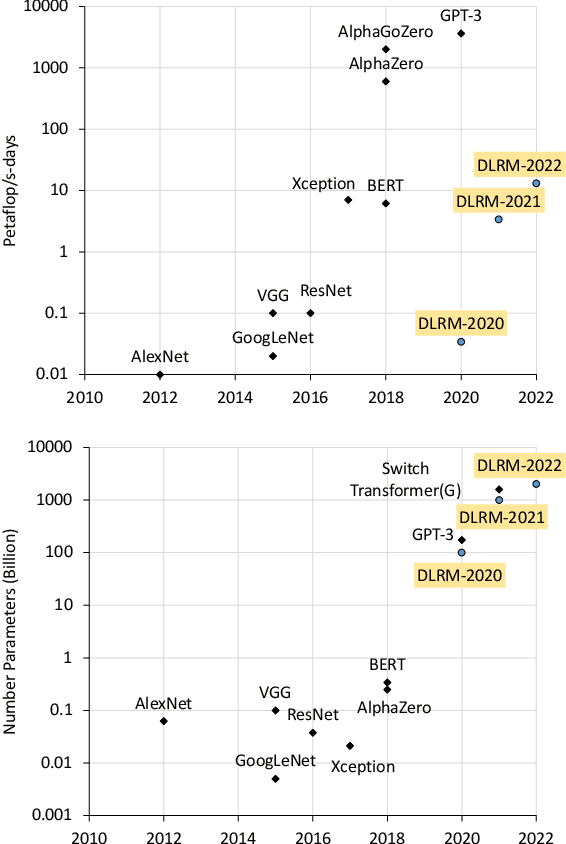

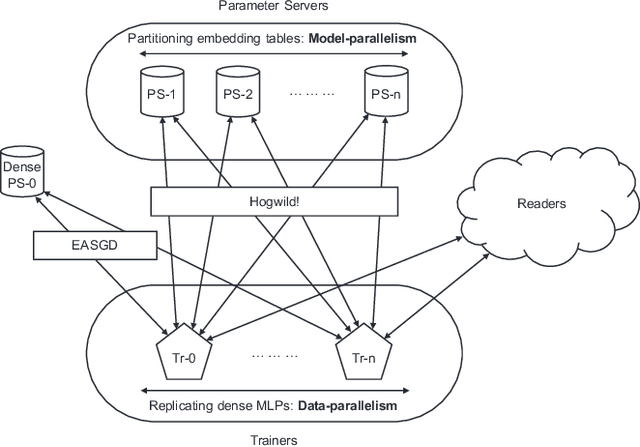
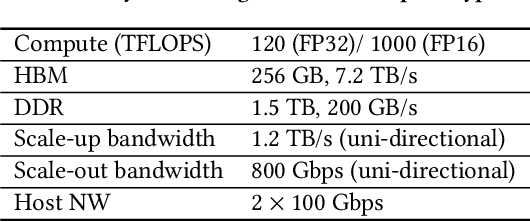
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Check-N-Run: A Checkpointing System for Training Recommendation Models
Oct 17, 2020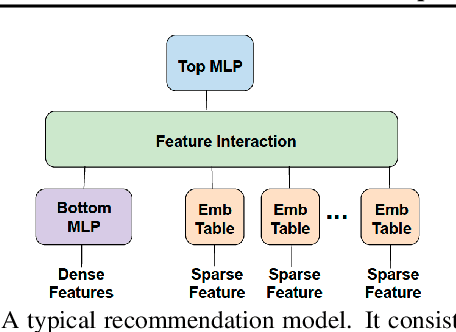
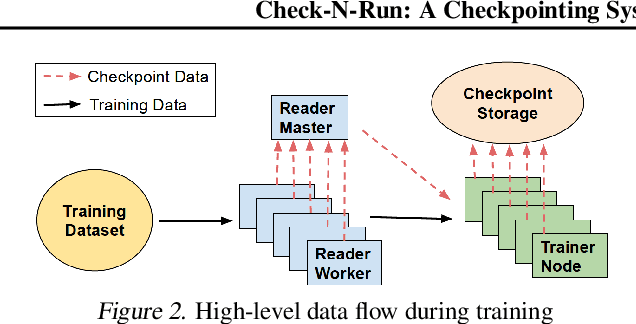
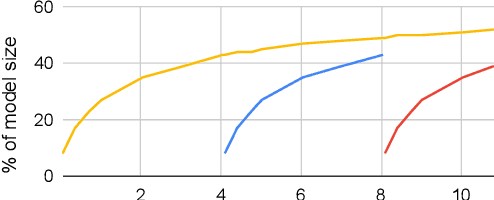
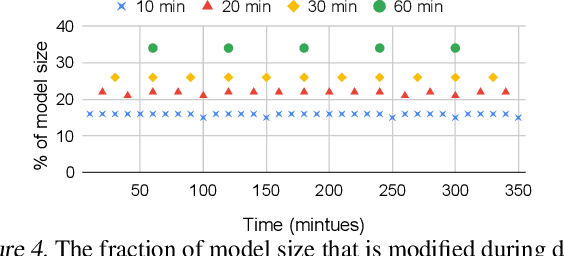
Checkpoints play an important role in training recommendation systems at scale. They are important for many use cases, including failure recovery to ensure rapid training progress, and online training to improve inference prediction accuracy. Checkpoints are typically written to remote, persistent storage. Given the typically large and ever-increasing recommendation model sizes, the checkpoint frequency and effectiveness is often bottlenecked by the storage write bandwidth and capacity, as well as the network bandwidth. We present Check-N-Run, a scalable checkpointing system for training large recommendation models. Check-N-Run uses two primary approaches to address these challenges. First, it applies incremental checkpointing, which tracks and checkpoints the modified part of the model. On top of that, it leverages quantization techniques to significantly reduce the checkpoint size, without degrading training accuracy. These techniques allow Check-N-Run to reduce the required write bandwidth by 6-17x and the required capacity by 2.5-8x on real-world models at Facebook, and thereby significantly improve checkpoint capabilities while reducing the total cost of ownership.