 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIFS-Rec: Process-In-Fabric-Switch for Large-Scale Recommendation System Inferences
Sep 25, 2024



Deep Learning Recommendation Models (DLRMs) have become increasingly popular and prevalent in today's datacenters, consuming most of the AI inference cycles. The performance of DLRMs is heavily influenced by available bandwidth due to their large vector sizes in embedding tables and concurrent accesses. To achieve substantial improvements over existing solutions, novel approaches towards DLRM optimization are needed, especially, in the context of emerging interconnect technologies like CXL. This study delves into exploring CXL-enabled systems, implementing a process-in-fabric-switch (PIFS) solution to accelerate DLRMs while optimizing their memory and bandwidth scalability. We present an in-depth characterization of industry-scale DLRM workloads running on CXL-ready systems, identifying the predominant bottlenecks in existing CXL systems. We, therefore, propose PIFS-Rec, a PIFS-based scheme that implements near-data processing through downstream ports of the fabric switch. PIFS-Rec achieves a latency that is 3.89x lower than Pond, an industry-standard CXL-based system, and also outperforms BEACON, a state-of-the-art scheme, by 2.03x.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022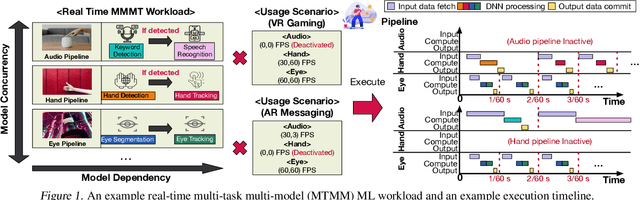
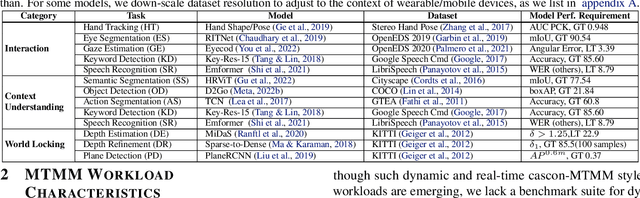

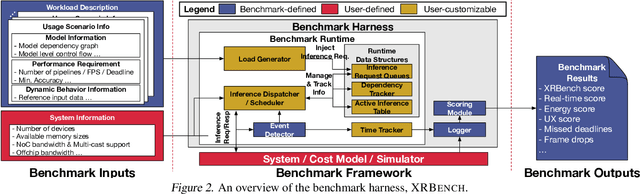
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.
Learning to Collide: Recommendation System Model Compression with Learned Hash Functions
Mar 28, 2022

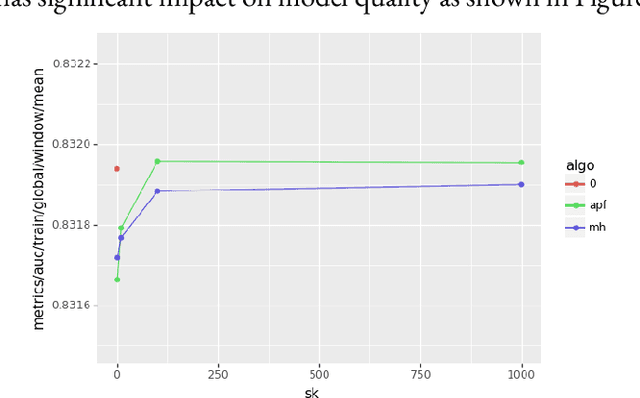
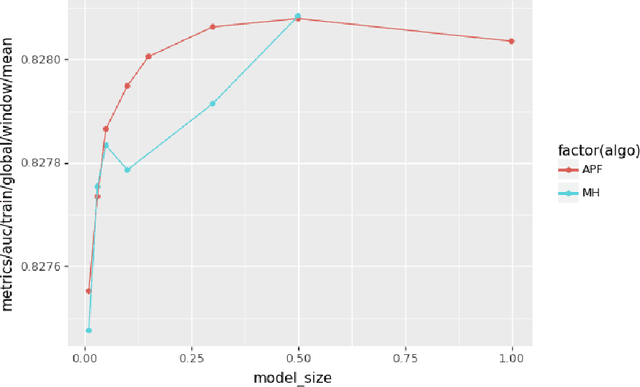
A key characteristic of deep recommendation models is the immense memory requirements of their embedding tables. These embedding tables can often reach hundreds of gigabytes which increases hardware requirements and training cost. A common technique to reduce model size is to hash all of the categorical variable identifiers (ids) into a smaller space. This hashing reduces the number of unique representations that must be stored in the embedding table; thus decreasing its size. However, this approach introduces collisions between semantically dissimilar ids that degrade model quality. We introduce an alternative approach, Learned Hash Functions, which instead learns a new mapping function that encourages collisions between semantically similar ids. We derive this learned mapping from historical data and embedding access patterns. We experiment with this technique on a production model and find that a mapping informed by the combination of access frequency and a learned low dimension embedding is the most effective. We demonstrate a small improvement relative to the hashing trick and other collision related compression techniques. This is ongoing work that explores the impact of categorical id collisions on recommendation model quality and how those collisions may be controlled to improve model performance.
Supporting Massive DLRM Inference Through Software Defined Memory
Nov 08, 2021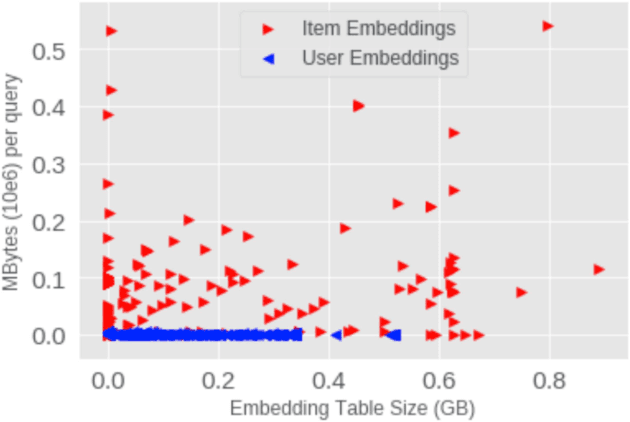

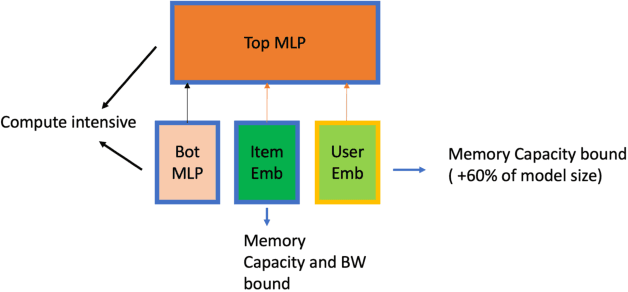

Deep Learning Recommendation Models (DLRM) are widespread, account for a considerable data center footprint, and grow by more than 1.5x per year. With model size soon to be in terabytes range, leveraging Storage ClassMemory (SCM) for inference enables lower power consumption and cost. This paper evaluates the major challenges in extending the memory hierarchy to SCM for DLRM, and presents different techniques to improve performance through a Software Defined Memory. We show how underlying technologies such as Nand Flash and 3DXP differentiate, and relate to real world scenarios, enabling from 5% to 29% power savings.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021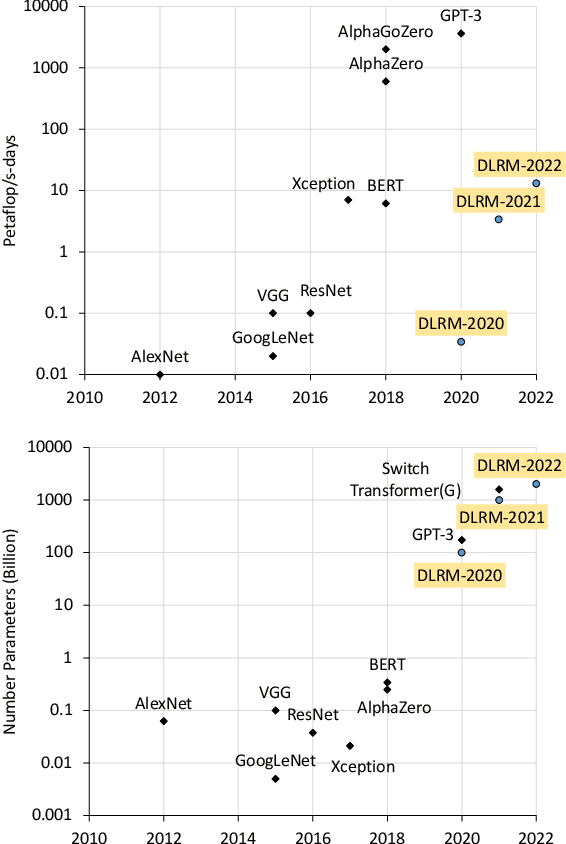

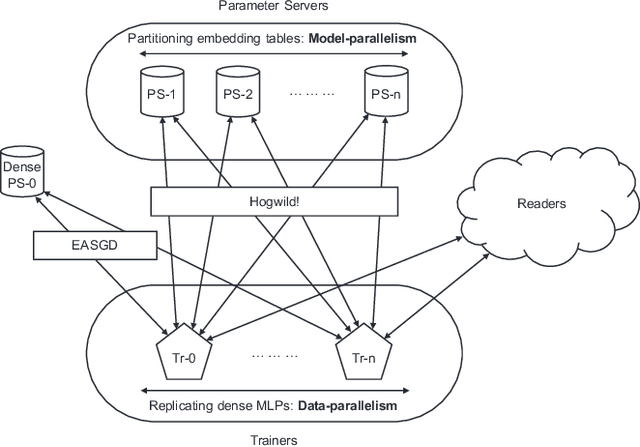
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Check-N-Run: A Checkpointing System for Training Recommendation Models
Oct 17, 2020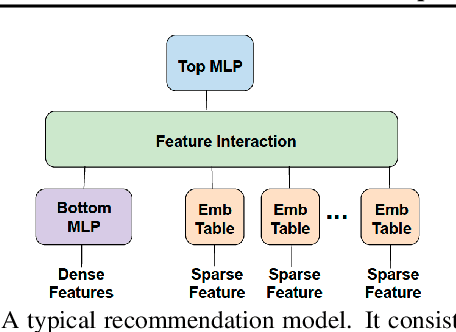
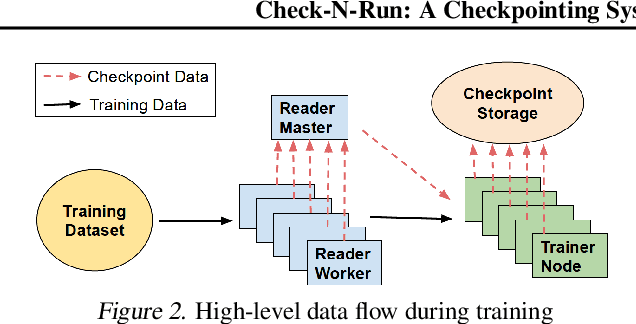
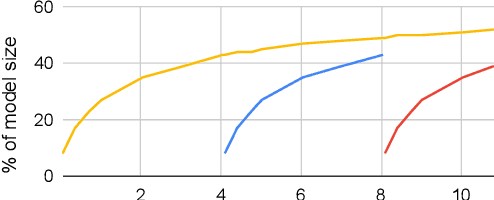
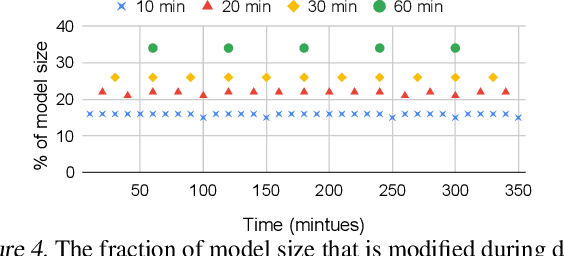
Checkpoints play an important role in training recommendation systems at scale. They are important for many use cases, including failure recovery to ensure rapid training progress, and online training to improve inference prediction accuracy. Checkpoints are typically written to remote, persistent storage. Given the typically large and ever-increasing recommendation model sizes, the checkpoint frequency and effectiveness is often bottlenecked by the storage write bandwidth and capacity, as well as the network bandwidth. We present Check-N-Run, a scalable checkpointing system for training large recommendation models. Check-N-Run uses two primary approaches to address these challenges. First, it applies incremental checkpointing, which tracks and checkpoints the modified part of the model. On top of that, it leverages quantization techniques to significantly reduce the checkpoint size, without degrading training accuracy. These techniques allow Check-N-Run to reduce the required write bandwidth by 6-17x and the required capacity by 2.5-8x on real-world models at Facebook, and thereby significantly improve checkpoint capabilities while reducing the total cost of ownership.