 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
RecD: Deduplication for End-to-End Deep Learning Recommendation Model Training Infrastructure
Nov 14, 2022



We present RecD (Recommendation Deduplication), a suite of end-to-end infrastructure optimizations across the Deep Learning Recommendation Model (DLRM) training pipeline. RecD addresses immense storage, preprocessing, and training overheads caused by feature duplication inherent in industry-scale DLRM training datasets. Feature duplication arises because DLRM datasets are generated from interactions. While each user session can generate multiple training samples, many features' values do not change across these samples. We demonstrate how RecD exploits this property, end-to-end, across a deployed training pipeline. RecD optimizes data generation pipelines to decrease dataset storage and preprocessing resource demands and to maximize duplication within a training batch. RecD introduces a new tensor format, InverseKeyedJaggedTensors (IKJTs), to deduplicate feature values in each batch. We show how DLRM model architectures can leverage IKJTs to drastically increase training throughput. RecD improves the training and preprocessing throughput and storage efficiency by up to 2.49x, 1.79x, and 3.71x, respectively, in an industry-scale DLRM training system.
Understanding and Co-designing the Data Ingestion Pipeline for Industry-Scale RecSys Training
Aug 20, 2021
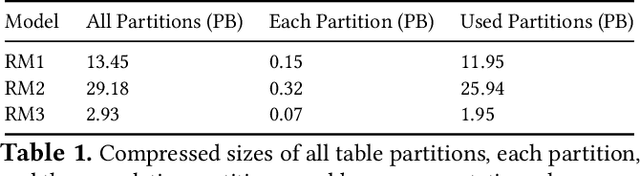
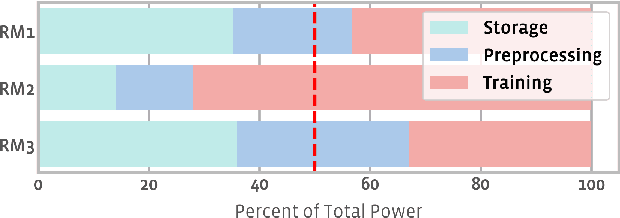

The data ingestion pipeline, responsible for storing and preprocessing training data, is an important component of any machine learning training job. At Facebook, we use recommendation models extensively across our services. The data ingestion requirements to train these models are substantial. In this paper, we present an extensive characterization of the data ingestion challenges for industry-scale recommendation model training. First, dataset storage requirements are massive and variable; exceeding local storage capacities. Secondly, reading and preprocessing data is computationally expensive, requiring substantially more compute, memory, and network resources than are available on trainers themselves. These demands result in drastically reduced training throughput, and thus wasted GPU resources, when current on-trainer preprocessing solutions are used. To address these challenges, we present a disaggregated data ingestion pipeline. It includes a central data warehouse built on distributed storage nodes. We introduce Data PreProcessing Service (DPP), a fully disaggregated preprocessing service that scales to hundreds of nodes, eliminating data stalls that can reduce training throughput by 56%. We implement important optimizations across storage and DPP, increasing storage and preprocessing throughput by 1.9x and 2.3x, respectively, addressing the substantial power requirements of data ingestion. We close with lessons learned and cover the important remaining challenges and opportunities surrounding data ingestion at scale.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021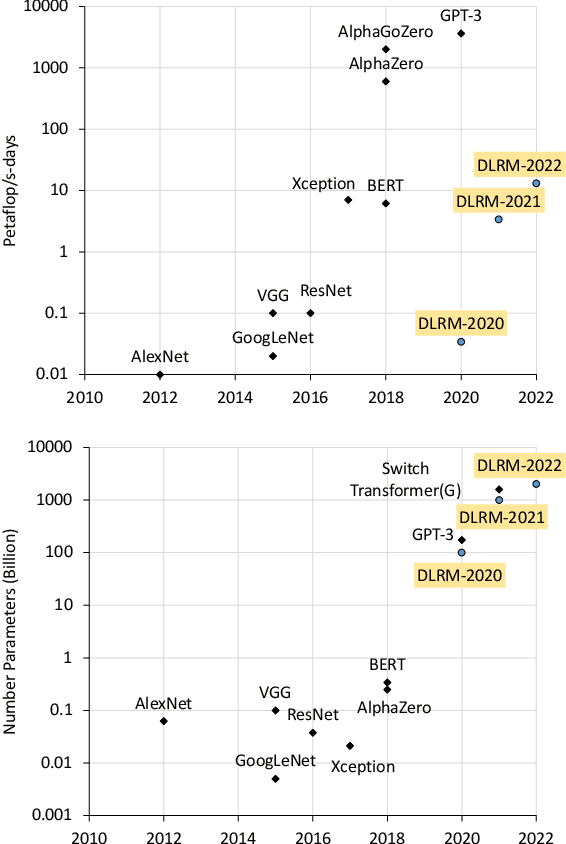

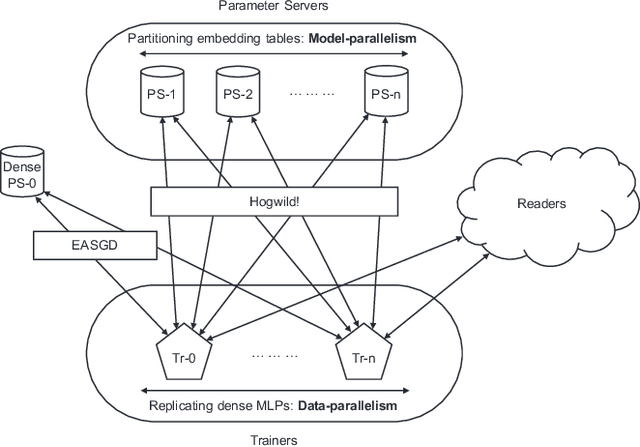
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.