 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Massive DLRM Inference Through Software Defined Memory
Nov 08, 2021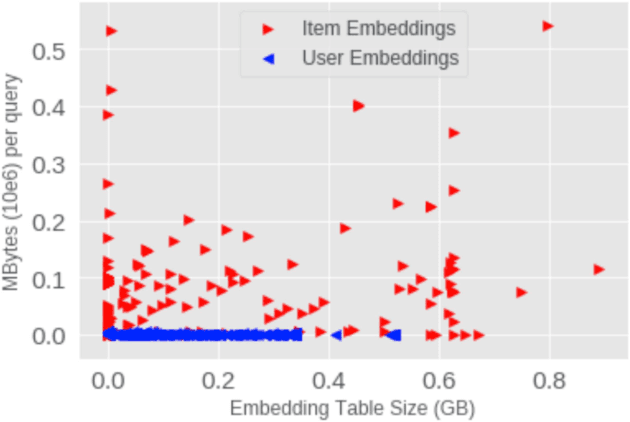

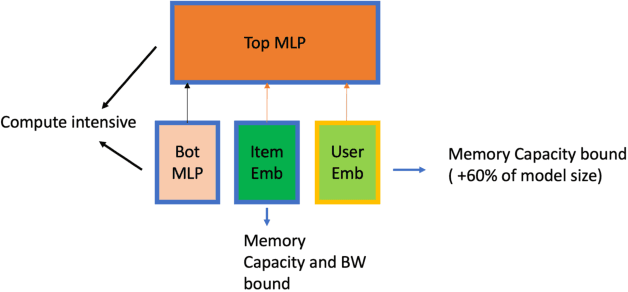

Deep Learning Recommendation Models (DLRM) are widespread, account for a considerable data center footprint, and grow by more than 1.5x per year. With model size soon to be in terabytes range, leveraging Storage ClassMemory (SCM) for inference enables lower power consumption and cost. This paper evaluates the major challenges in extending the memory hierarchy to SCM for DLRM, and presents different techniques to improve performance through a Software Defined Memory. We show how underlying technologies such as Nand Flash and 3DXP differentiate, and relate to real world scenarios, enabling from 5% to 29% power savings.
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021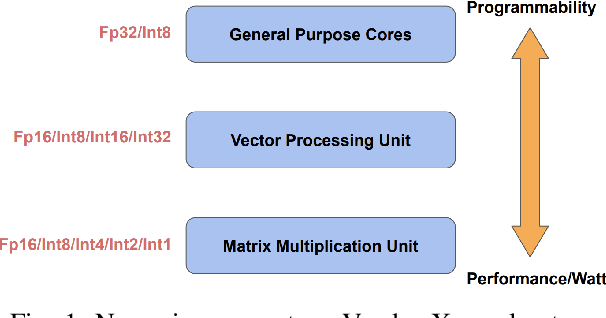
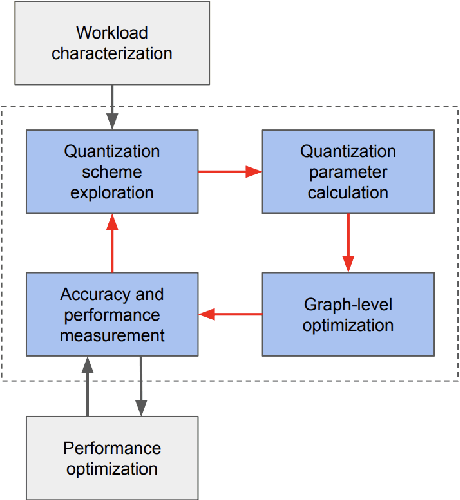
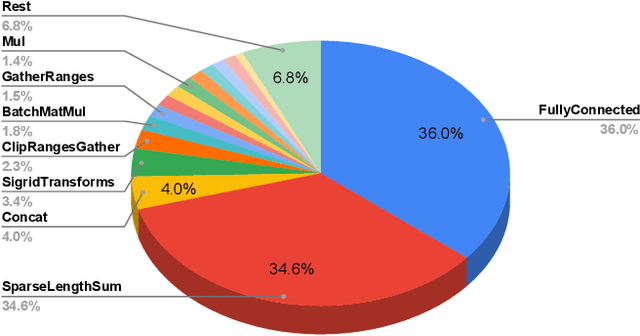
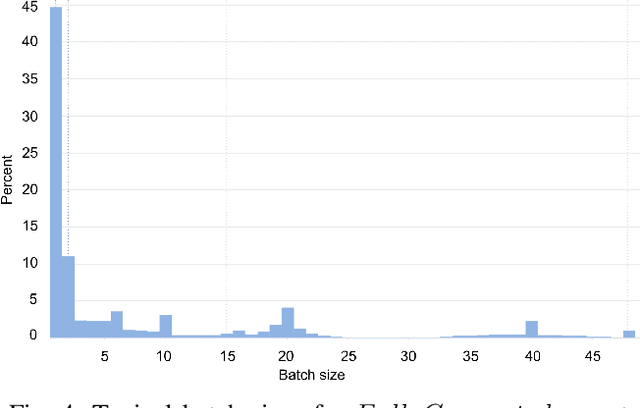
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021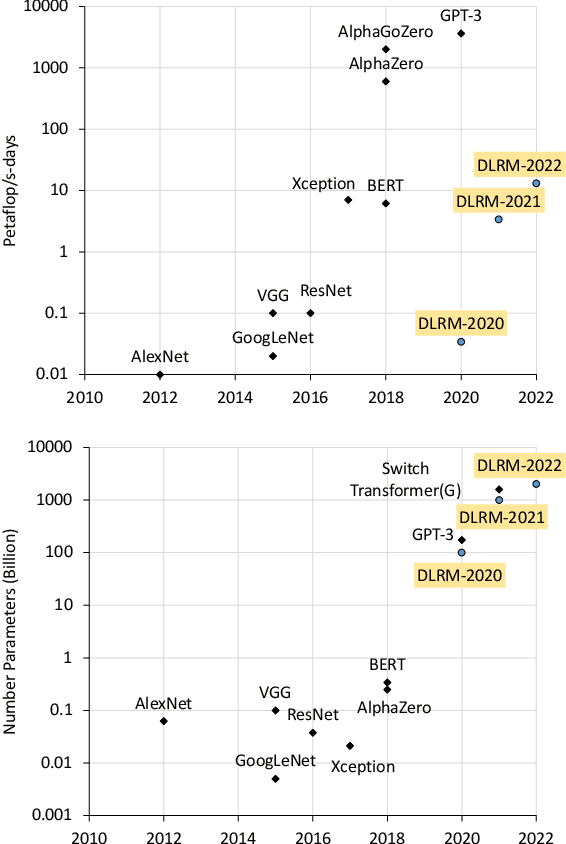

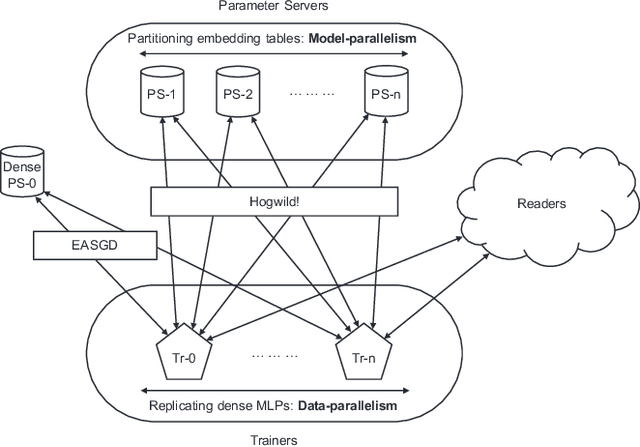
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
FBGEMM: Enabling High-Performance Low-Precision Deep Learning Inference
Jan 13, 2021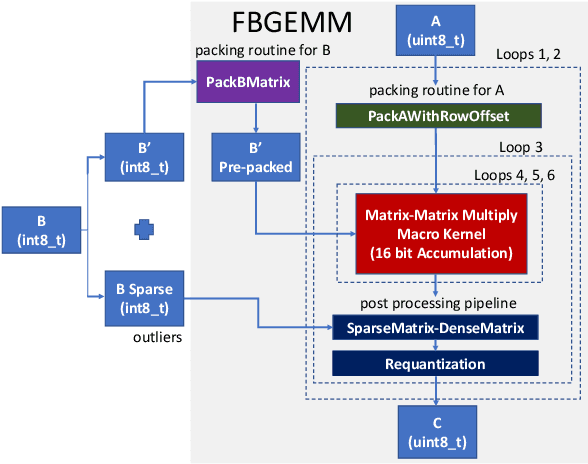
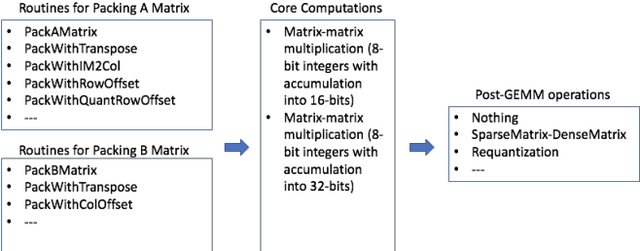
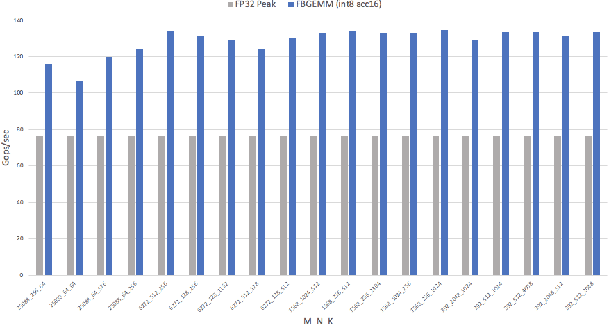
Deep learning models typically use single-precision (FP32) floating point data types for representing activations and weights, but a slew of recent research work has shown that computations with reduced-precision data types (FP16, 16-bit integers, 8-bit integers or even 4- or 2-bit integers) are enough to achieve same accuracy as FP32 and are much more efficient. Therefore, we designed fbgemm, a high-performance kernel library, from ground up to perform high-performance quantized inference on current generation CPUs. fbgemm achieves efficiency by fusing common quantization operations with a high-performance gemm implementation and by shape- and size-specific kernel code generation at runtime. The library has been deployed at Facebook, where it delivers greater than 2x performance gains with respect to our current production baseline.
The Architectural Implications of Facebook's DNN-based Personalized Recommendation
Jun 18, 2019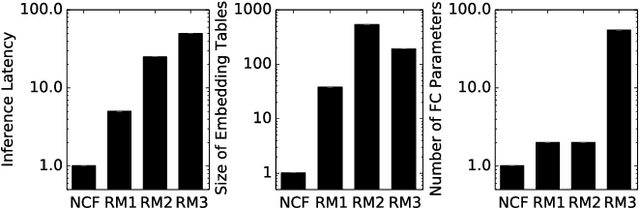
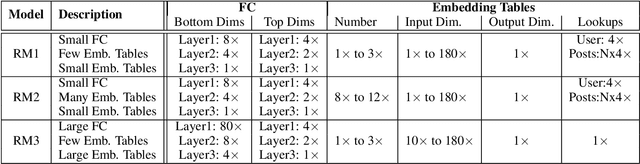
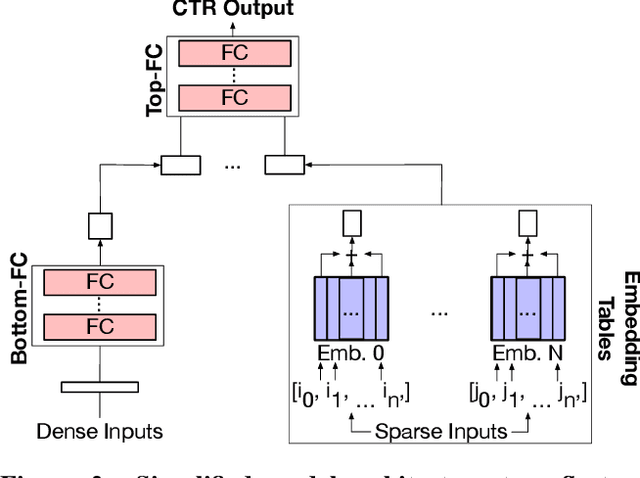
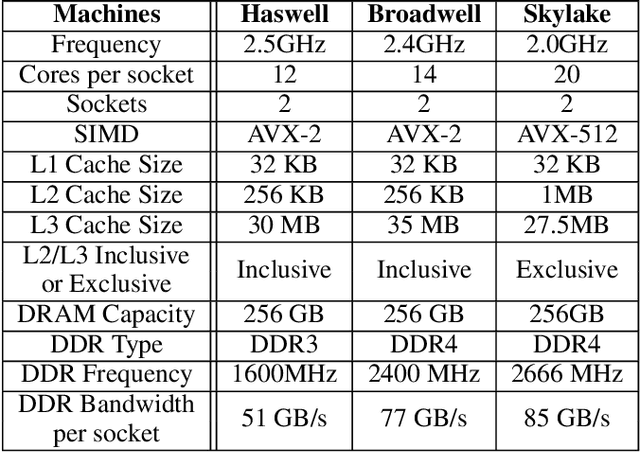
The widespread application of deep learning has changed the landscape of computation in the data center. In particular, personalized recommendation for content ranking is now largely accomplished leveraging deep neural networks. However, despite the importance of these models and the amount of compute cycles they consume, relatively little research attention has been devoted to systems for recommendation. To facilitate research and to advance the understanding of these workloads, this paper presents a set of real-world, production-scale DNNs for personalized recommendation coupled with relevant performance metrics for evaluation. In addition to releasing a set of open-source workloads, we conduct in-depth analysis that underpins future system design and optimization for at-scale recommendation: Inference latency varies by 60% across three Intel server generations, batching and co-location of inferences can drastically improve latency-bounded throughput, and the diverse composition of recommendation models leads to different optimization strategies.
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018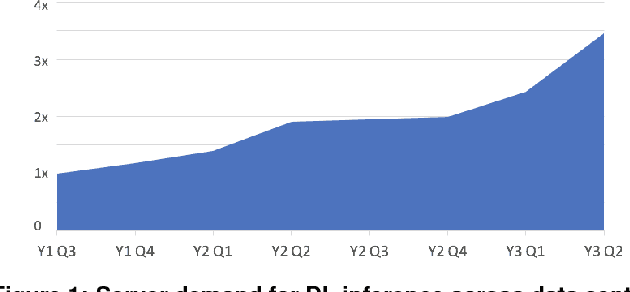
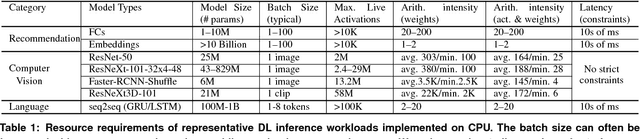
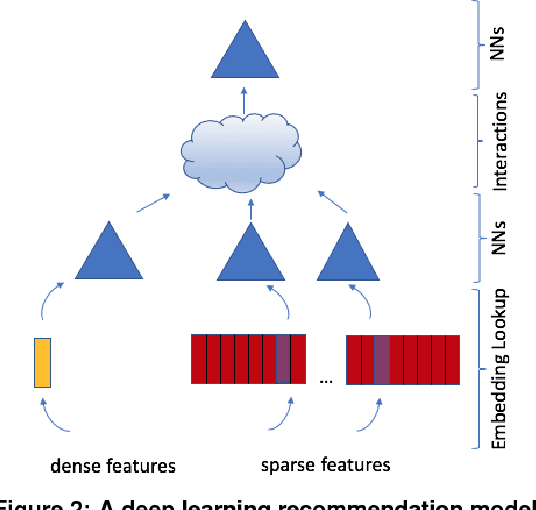
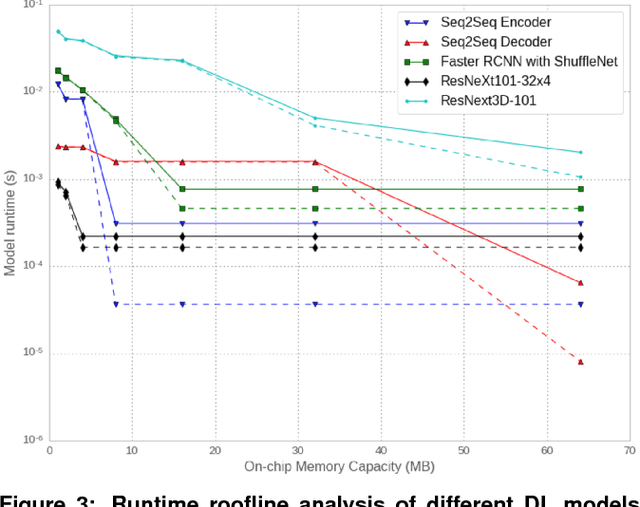
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Feb 09, 2017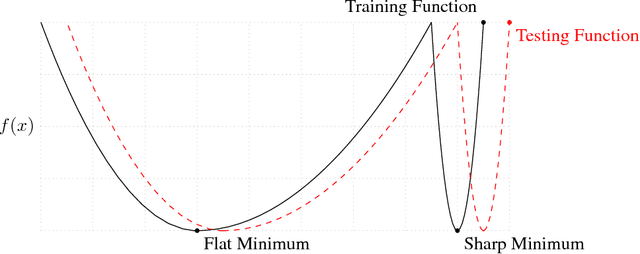
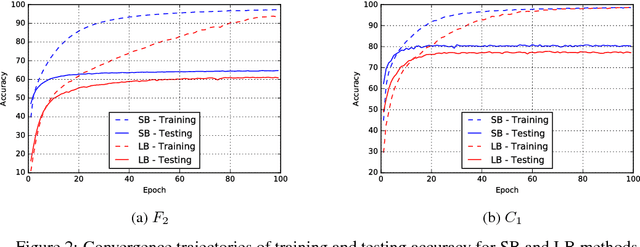
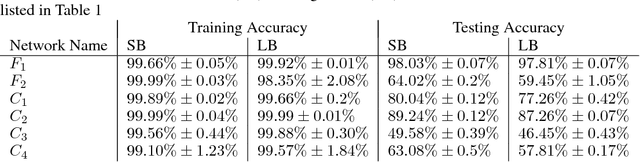
The stochastic gradient descent (SGD) method and its variants are algorithms of choice for many Deep Learning tasks. These methods operate in a small-batch regime wherein a fraction of the training data, say $32$-$512$ data points, is sampled to compute an approximation to the gradient. It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize. We investigate the cause for this generalization drop in the large-batch regime and present numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions - and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation. We discuss several strategies to attempt to help large-batch methods eliminate this generalization gap.
Distributed Hessian-Free Optimization for Deep Neural Network
Jan 15, 2017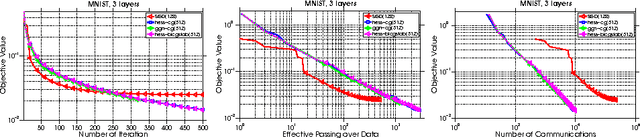
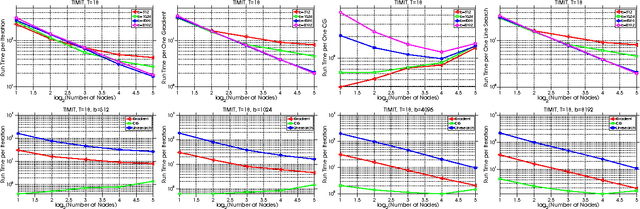
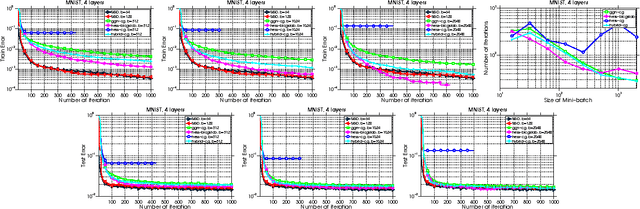
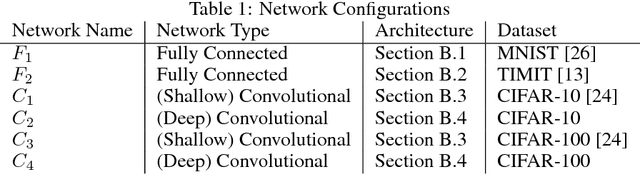
Training deep neural network is a high dimensional and a highly non-convex optimization problem. Stochastic gradient descent (SGD) algorithm and it's variations are the current state-of-the-art solvers for this task. However, due to non-covexity nature of the problem, it was observed that SGD slows down near saddle point. Recent empirical work claim that by detecting and escaping saddle point efficiently, it's more likely to improve training performance. With this objective, we revisit Hessian-free optimization method for deep networks. We also develop its distributed variant and demonstrate superior scaling potential to SGD, which allows more efficiently utilizing larger computing resources thus enabling large models and faster time to obtain desired solution. Furthermore, unlike truncated Newton method (Marten's HF) that ignores negative curvature information by using na\"ive conjugate gradient method and Gauss-Newton Hessian approximation information - we propose a novel algorithm to explore negative curvature direction by solving the sub-problem with stabilized bi-conjugate method involving possible indefinite stochastic Hessian information. We show that these techniques accelerate the training process for both the standard MNIST dataset and also the TIMIT speech recognition problem, demonstrating robust performance with upto an order of magnitude larger batch sizes. This increased scaling potential is illustrated with near linear speed-up on upto 16 CPU nodes for a simple 4-layer network.