 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Evidence Highlighting for Frozen LLMs
Apr 24, 2026Large Language Models (LLMs) can reason well, yet often miss decisive evidence when it is buried in long, noisy contexts. We introduce HiLight, an Evidence Emphasis framework that decouples evidence selection from reasoning for frozen LLM solvers. HiLight avoids compressing or rewriting the input, which can discard or distort evidence, by training a lightweight Emphasis Actor to insert minimal highlight tags around pivotal spans in the unaltered context. A frozen Solver then performs downstream reasoning on the emphasized input. We cast highlighting as a weakly supervised decision-making problem and optimize the Actor with reinforcement learning using only the Solver's task reward, requiring no evidence labels and no access to or modification of the Solver. Across sequential recommendation and long-context question answering, HiLight consistently improves performance over strong prompt-based and automated prompt-optimization baselines. The learned emphasis policy transfers zero-shot to both smaller and larger unseen Solver families, including an API-based Solver, suggesting that the Actor captures genuine, reusable evidence structure rather than overfitting to a single backbone.
Efficient Retrieval Scaling with Hierarchical Indexing for Large Scale Recommendation
Apr 14, 2026The increase in data volume, computational resources, and model parameters during training has led to the development of numerous large-scale industrial retrieval models for recommendation tasks. However, effectively and efficiently deploying these large-scale foundational retrieval models remains a critical challenge that has not been fully addressed. Common quick-win solutions for deploying these massive models include relying on offline computations (such as cached user dictionaries) or distilling large models into smaller ones. Yet, both approaches fall short of fully leveraging the representational and inference capabilities of foundational models. In this paper, we explore whether it is possible to learn a hierarchical organization over the memory of foundational retrieval models. Such a hierarchical structure would enable more efficient search by reducing retrieval costs while preserving exactness. To achieve this, we propose jointly learning a hierarchical index using cross-attention and residual quantization for large-scale retrieval models. We also present its real-world deployment at Meta, supporting daily advertisement recommendations for billions of Facebook and Instagram users. Interestingly, we discovered that the intermediate nodes in the learned index correspond to a small set of high-quality data. Fine-tuning the model on this set further improves inference performance, and concretize the concept of "test-time training" within the recommendation system domain. We demonstrate these findings using both internal and public datasets with strong baseline comparisons and hope they contribute to the community's efforts in developing the next generation of foundational retrieval models.
SOLARIS: Speculative Offloading of Latent-bAsed Representation for Inference Scaling
Apr 13, 2026Recent advances in recommendation scaling laws have led to foundation models of unprecedented complexity. While these models offer superior performance, their computational demands make real-time serving impractical, often forcing practitioners to rely on knowledge distillation-compromising serving quality for efficiency. To address this challenge, we present SOLARIS (Speculative Offloading of Latent-bAsed Representation for Inference Scaling), a novel framework inspired by speculative decoding. SOLARIS proactively precomputes user-item interaction embeddings by predicting which user-item pairs are likely to appear in future requests, and asynchronously generating their foundation model representations ahead of time. This approach decouples the costly foundation model inference from the latency-critical serving path, enabling real-time knowledge transfer from models previously considered too expensive for online use. Deployed across Meta's advertising system serving billions of daily requests, SOLARIS achieves 0.67% revenue-driving top-line metrics gain, demonstrating its effectiveness at scale.
Generative Reasoning Re-ranker
Feb 08, 2026Recent studies increasingly explore Large Language Models (LLMs) as a new paradigm for recommendation systems due to their scalability and world knowledge. However, existing work has three key limitations: (1) most efforts focus on retrieval and ranking, while the reranking phase, critical for refining final recommendations, is largely overlooked; (2) LLMs are typically used in zero-shot or supervised fine-tuning settings, leaving their reasoning abilities, especially those enhanced through reinforcement learning (RL) and high-quality reasoning data, underexploited; (3) items are commonly represented by non-semantic IDs, creating major scalability challenges in industrial systems with billions of identifiers. To address these gaps, we propose the Generative Reasoning Reranker (GR2), an end-to-end framework with a three-stage training pipeline tailored for reranking. First, a pretrained LLM is mid-trained on semantic IDs encoded from non-semantic IDs via a tokenizer achieving $\ge$99% uniqueness. Next, a stronger larger-scale LLM generates high-quality reasoning traces through carefully designed prompting and rejection sampling, which are used for supervised fine-tuning to impart foundational reasoning skills. Finally, we apply Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO), enabling scalable RL supervision with verifiable rewards designed specifically for reranking. Experiments on two real-world datasets demonstrate GR2's effectiveness: it surpasses the state-of-the-art OneRec-Think by 2.4% in Recall@5 and 1.3% in NDCG@5. Ablations confirm that advanced reasoning traces yield substantial gains across metrics. We further find that RL reward design is crucial in reranking: LLMs tend to exploit reward hacking by preserving item order, motivating conditional verifiable rewards to mitigate this behavior and optimize reranking performance.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
Hierarchical Structured Neural Network for Retrieval
Aug 13, 2024



Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021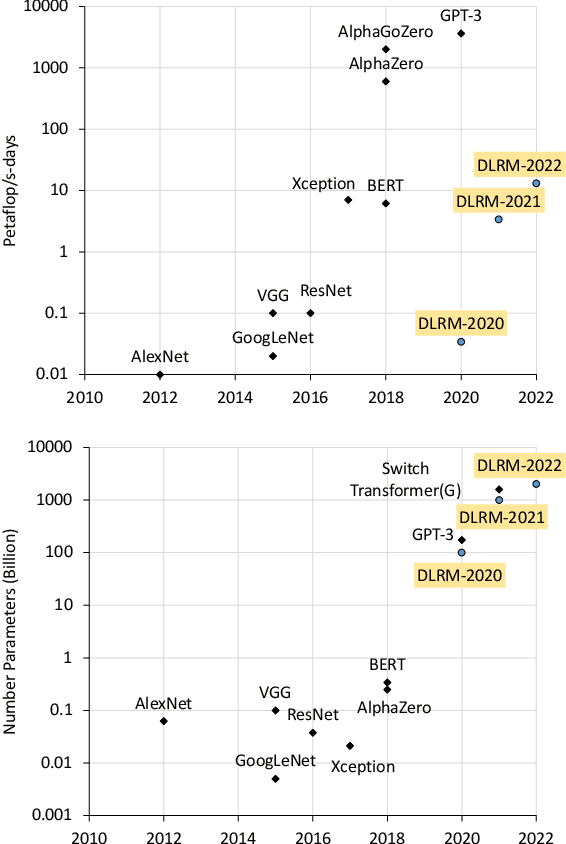

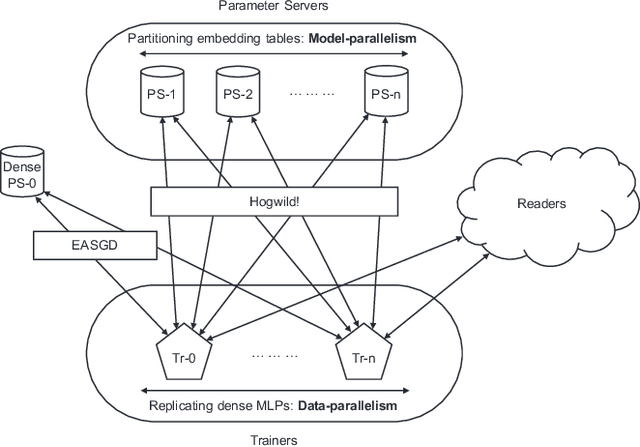
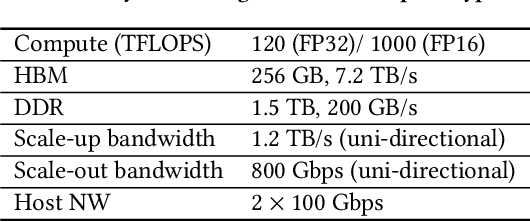
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Time-based Sequence Model for Personalization and Recommendation Systems
Aug 27, 2020

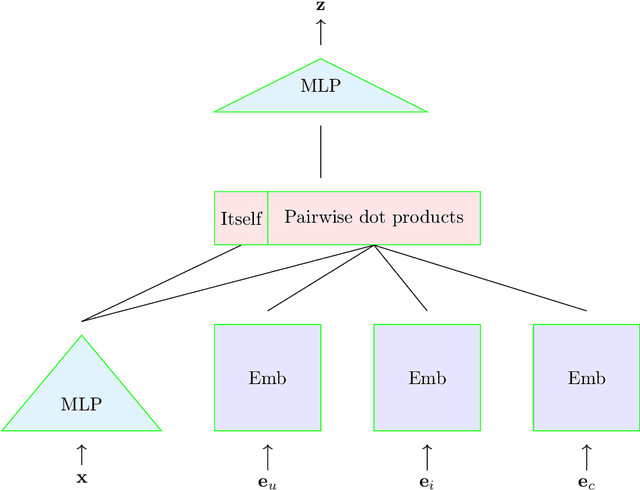
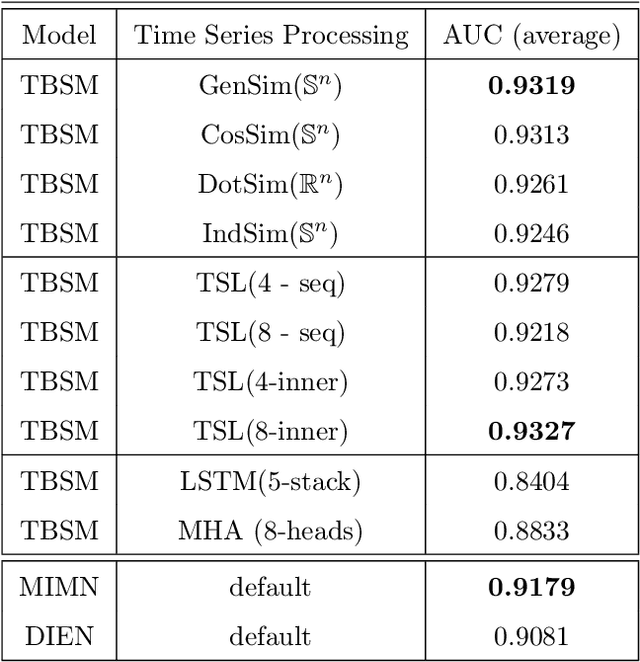
In this paper we develop a novel recommendation model that explicitly incorporates time information. The model relies on an embedding layer and TSL attention-like mechanism with inner products in different vector spaces, that can be thought of as a modification of multi-headed attention. This mechanism allows the model to efficiently treat sequences of user behavior of different length. We study the properties of our state-of-the-art model on statistically designed data set. Also, we show that it outperforms more complex models with longer sequence length on the Taobao User Behavior dataset.
Category Enhanced Word Embedding
Nov 30, 2015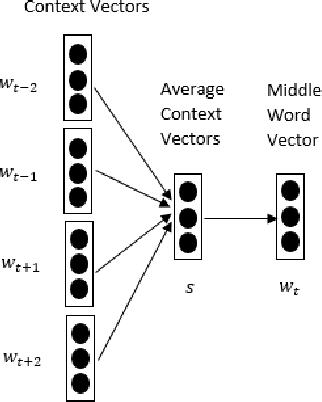
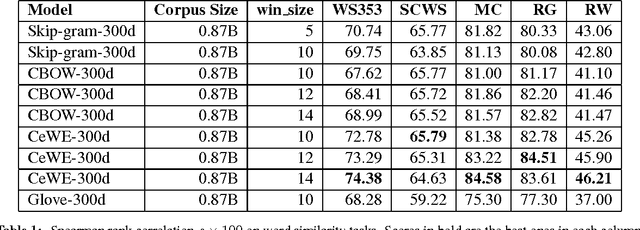
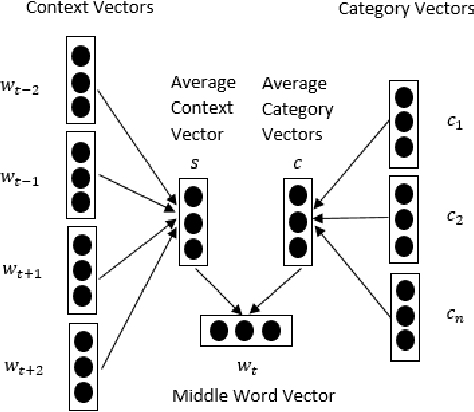
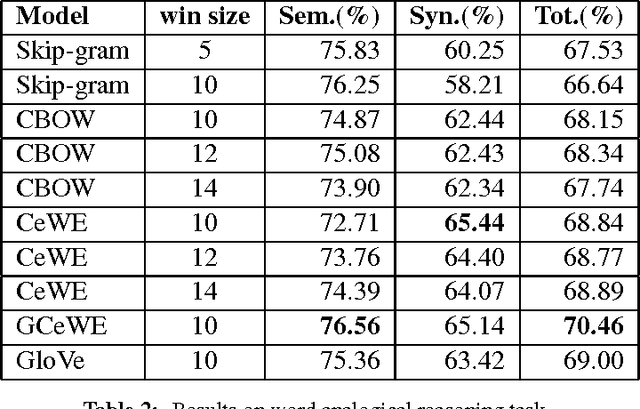
Distributed word representations have been demonstrated to be effective in capturing semantic and syntactic regularities. Unsupervised representation learning from large unlabeled corpora can learn similar representations for those words that present similar co-occurrence statistics. Besides local occurrence statistics, global topical information is also important knowledge that may help discriminate a word from another. In this paper, we incorporate category information of documents in the learning of word representations and to learn the proposed models in a document-wise manner. Our models outperform several state-of-the-art models in word analogy and word similarity tasks. Moreover, we evaluate the learned word vectors on sentiment analysis and text classification tasks, which shows the superiority of our learned word vectors. We also learn high-quality category embeddings that reflect topical meanings.
A C-LSTM Neural Network for Text Classification
Nov 30, 2015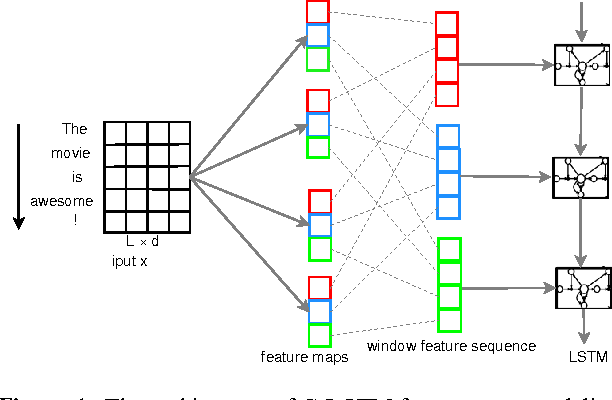
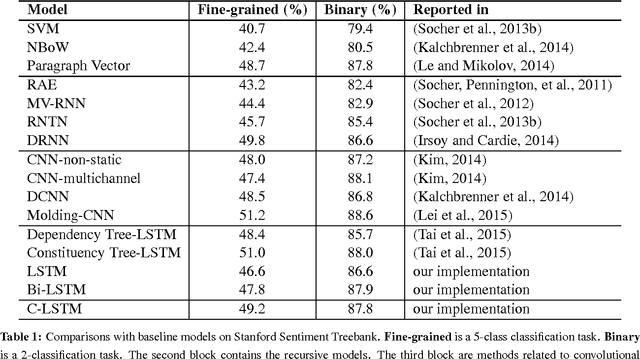
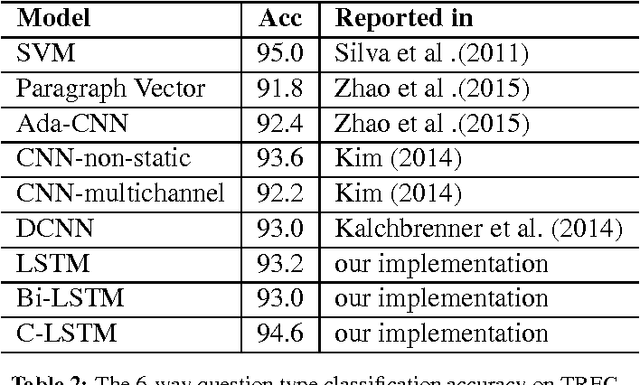
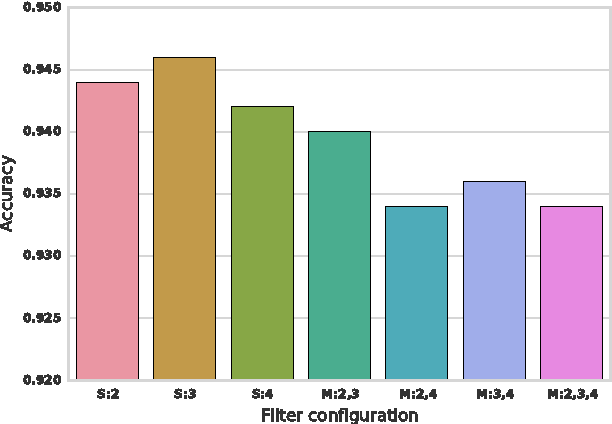
Neural network models have been demonstrated to be capable of achieving remarkable performance in sentence and document modeling. Convolutional neural network (CNN) and recurrent neural network (RNN) are two mainstream architectures for such modeling tasks, which adopt totally different ways of understanding natural languages. In this work, we combine the strengths of both architectures and propose a novel and unified model called C-LSTM for sentence representation and text classification. C-LSTM utilizes CNN to extract a sequence of higher-level phrase representations, and are fed into a long short-term memory recurrent neural network (LSTM) to obtain the sentence representation. C-LSTM is able to capture both local features of phrases as well as global and temporal sentence semantics. We evaluate the proposed architecture on sentiment classification and question classification tasks. The experimental results show that the C-LSTM outperforms both CNN and LSTM and can achieve excellent performance on these tasks.