 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Questions to Clinical Recommendations: Large Language Models Driving Evidence-Based Clinical Decision Making
May 15, 2025



Clinical evidence, derived from rigorous research and data analysis, provides healthcare professionals with reliable scientific foundations for informed decision-making. Integrating clinical evidence into real-time practice is challenging due to the enormous workload, complex professional processes, and time constraints. This highlights the need for tools that automate evidence synthesis to support more efficient and accurate decision making in clinical settings. This study introduces Quicker, an evidence-based clinical decision support system powered by large language models (LLMs), designed to automate evidence synthesis and generate clinical recommendations modeled after standard clinical guideline development processes. Quicker implements a fully automated chain that covers all phases, from questions to clinical recommendations, and further enables customized decision-making through integrated tools and interactive user interfaces. To evaluate Quicker's capabilities, we developed the Q2CRBench-3 benchmark dataset, based on clinical guideline development records for three different diseases. Experimental results highlighted Quicker's strong performance, with fine-grained question decomposition tailored to user preferences, retrieval sensitivities comparable to human experts, and literature screening performance approaching comprehensive inclusion of relevant studies. In addition, Quicker-assisted evidence assessment effectively supported human reviewers, while Quicker's recommendations were more comprehensive and logically coherent than those of clinicians. In system-level testing, collaboration between a single reviewer and Quicker reduced the time required for recommendation development to 20-40 minutes. In general, our findings affirm the potential of Quicker to help physicians make quicker and more reliable evidence-based clinical decisions.
PHE-SICH-CT-IDS: A Benchmark CT Image Dataset for Evaluation Semantic Segmentation, Object Detection and Radiomic Feature Extraction of Perihematomal Edema in Spontaneous Intracerebral Hemorrhage
Aug 21, 2023Intracerebral hemorrhage is one of the diseases with the highest mortality and poorest prognosis worldwide. Spontaneous intracerebral hemorrhage (SICH) typically presents acutely, prompt and expedited radiological examination is crucial for diagnosis, localization, and quantification of the hemorrhage. Early detection and accurate segmentation of perihematomal edema (PHE) play a critical role in guiding appropriate clinical intervention and enhancing patient prognosis. However, the progress and assessment of computer-aided diagnostic methods for PHE segmentation and detection face challenges due to the scarcity of publicly accessible brain CT image datasets. This study establishes a publicly available CT dataset named PHE-SICH-CT-IDS for perihematomal edema in spontaneous intracerebral hemorrhage. The dataset comprises 120 brain CT scans and 7,022 CT images, along with corresponding medical information of the patients. To demonstrate its effectiveness, classical algorithms for semantic segmentation, object detection, and radiomic feature extraction are evaluated. The experimental results confirm the suitability of PHE-SICH-CT-IDS for assessing the performance of segmentation, detection and radiomic feature extraction methods. To the best of our knowledge, this is the first publicly available dataset for PHE in SICH, comprising various data formats suitable for applications across diverse medical scenarios. We believe that PHE-SICH-CT-IDS will allure researchers to explore novel algorithms, providing valuable support for clinicians and patients in the clinical setting. PHE-SICH-CT-IDS is freely published for non-commercial purpose at: https://figshare.com/articles/dataset/PHE-SICH-CT-IDS/23957937.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021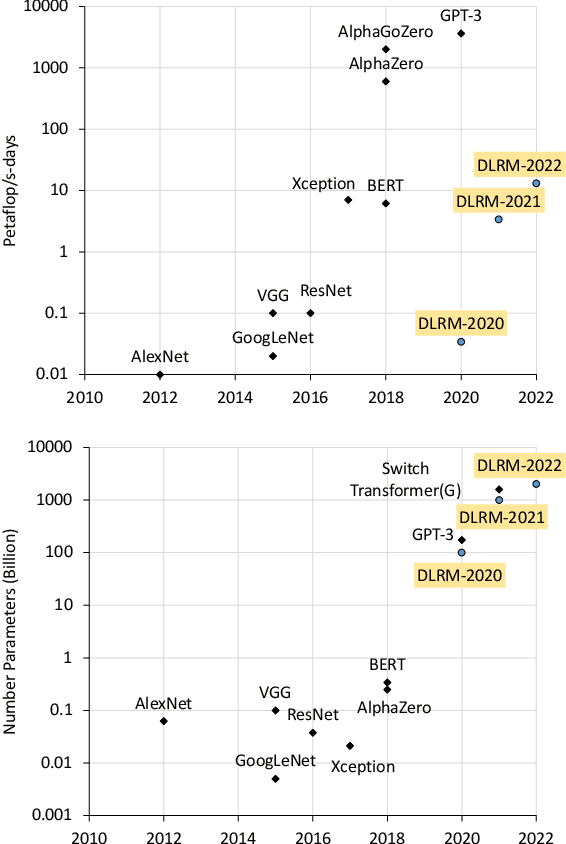

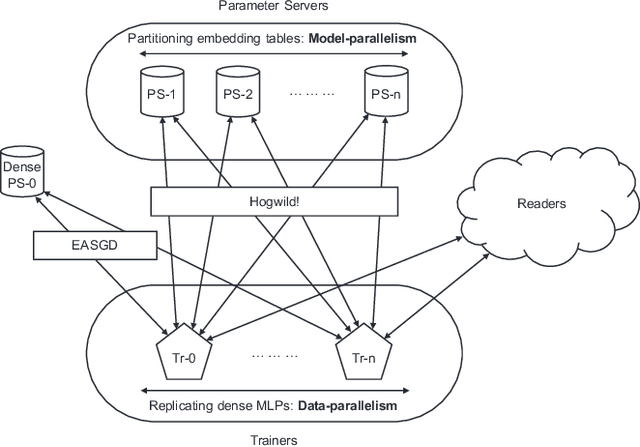
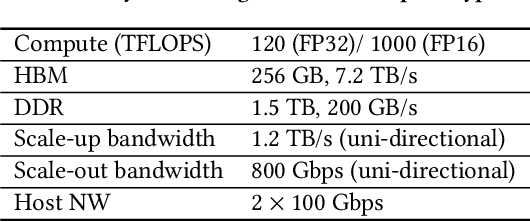
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
A Sentiment-Controllable Topic-to-Essay Generator with Topic Knowledge Graph
Oct 12, 2020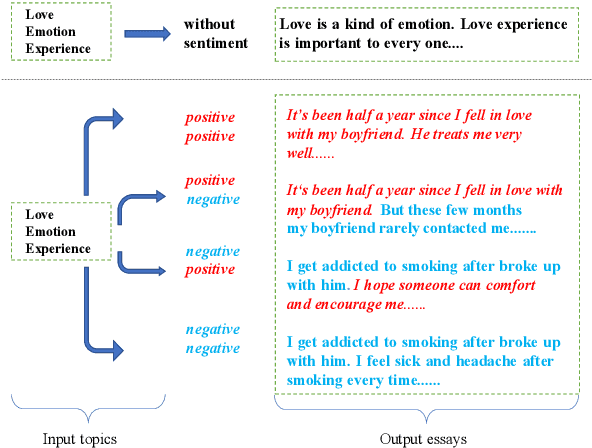
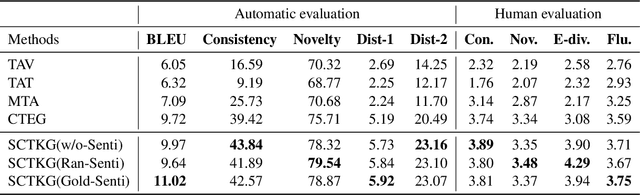
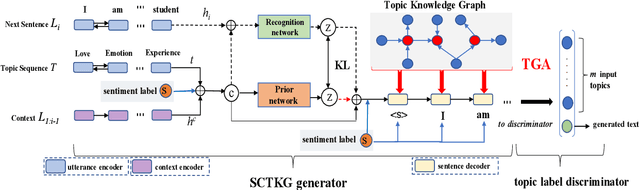
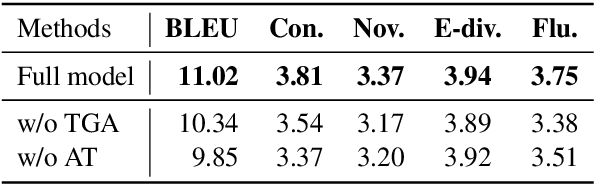
Generating a vivid, novel, and diverse essay with only several given topic words is a challenging task of natural language generation. In previous work, there are two problems left unsolved: neglect of sentiment beneath the text and insufficient utilization of topic-related knowledge. Therefore, we propose a novel Sentiment-Controllable topic-to-essay generator with a Topic Knowledge Graph enhanced decoder, named SCTKG, which is based on the conditional variational autoencoder (CVAE) framework. We firstly inject the sentiment information into the generator for controlling sentiment for each sentence, which leads to various generated essays. Then we design a Topic Knowledge Graph enhanced decoder. Unlike existing models that use knowledge entities separately, our model treats the knowledge graph as a whole and encodes more structured, connected semantic information in the graph to generate a more relevant essay. Experimental results show that our SCTKG can generate sentiment controllable essays and outperform the state-of-the-art approach in terms of topic relevance, fluency, and diversity on both automatic and human evaluation.
Hybrid Composition with IdleBlock: More Efficient Networks for Image Recognition
Nov 19, 2019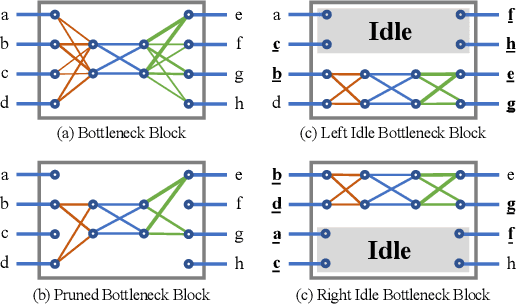
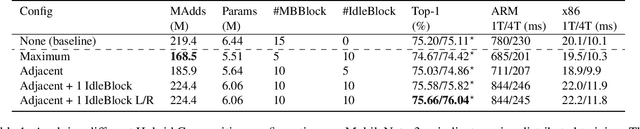
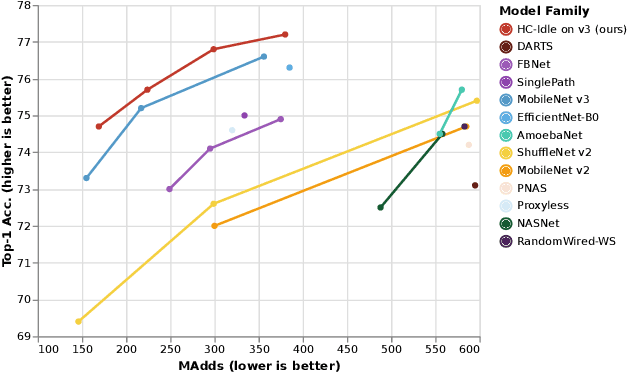
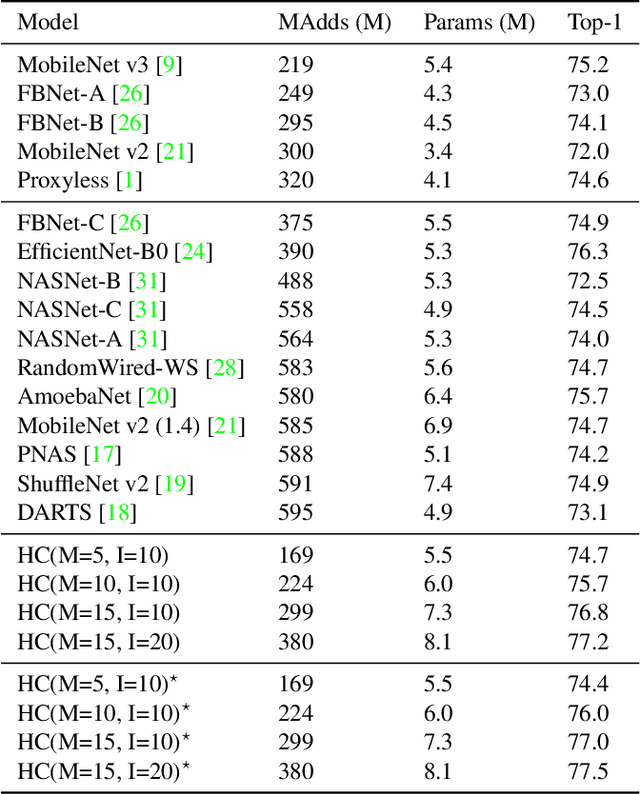
We propose a new building block, IdleBlock, which naturally prunes connections within the block. To fully utilize the IdleBlock we break the tradition of monotonic design in state-of-the-art networks, and introducing hybrid composition with IdleBlock. We study hybrid composition on MobileNet v3 and EfficientNet-B0, two of the most efficient networks. Without any neural architecture search, the deeper "MobileNet v3" with hybrid composition design surpasses possibly all state-of-the-art image recognition network designed by human experts or neural architecture search algorithms. Similarly, the hybridized EfficientNet-B0 networks are more efficient than previous state-of-the-art networks with similar computation budgets. These results suggest a new simpler and more efficient direction for network design and neural architecture search.
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018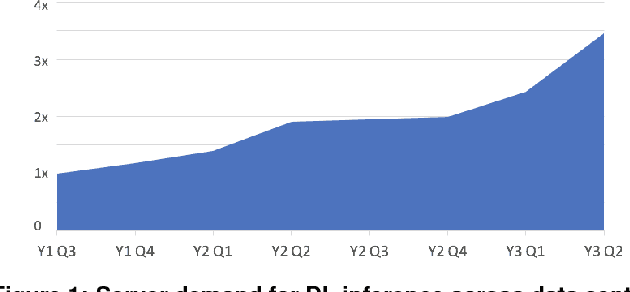
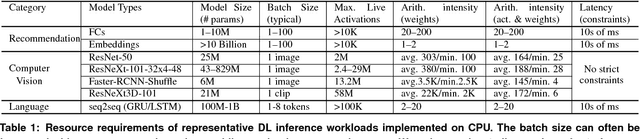
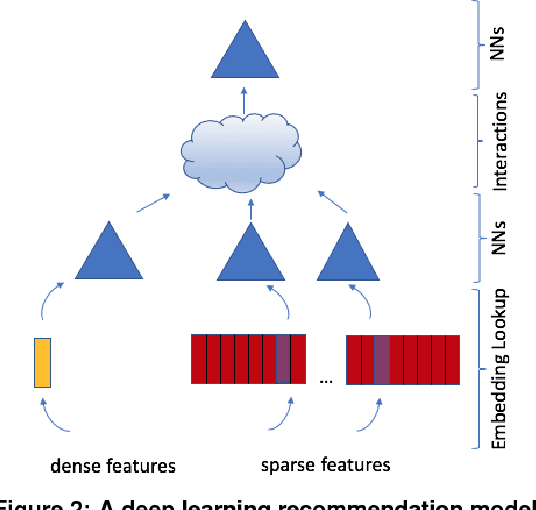
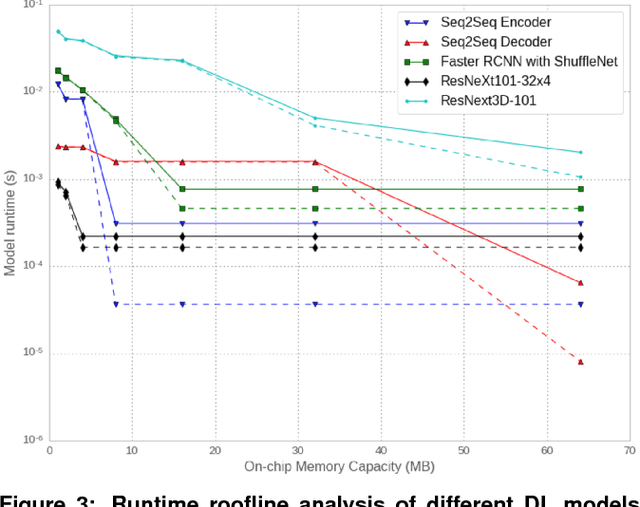
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.