 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Calibration of the endpoint-corrected Hilbert Transform
Jan 20, 2026Accurate, low-latency estimates of the instantaneous phase of oscillations are essential for closed-loop sensing and actuation, including (but not limited to) phase-locked neurostimulation and other real-time applications. The endpoint-corrected Hilbert transform (ecHT) reduces boundary artefacts of the Hilbert transform by applying a causal narrow-band filter to the analytic spectrum. This improves the phase estimate at the most recent sample. Despite its widespread empirical use, the systematic endpoint distortions of ecHT have lacked a principled, closed-form analysis. In this study, we derive the ecHT endpoint operator analytically and demonstrate that its output can be decomposed into a desired positive-frequency term (a deterministic complex gain that induces a calibratable amplitude/phase bias) and a residual leakage term setting an irreducible variance floor. This yields (i) an explicit characterisation and bounds for endpoint phase/amplitude error, (ii) a mean-squared-error-optimal scalar calibration (c-ecHT), and (iii) practical design rules relating window length, bandwidth/order, and centre-frequency mismatch to residual bias via an endpoint group delay. The resulting calibrated ecHT achieves near-zero mean phase error and remains computationally compatible with real-time pipelines. Code and analyses are provided at https://github.com/eosmers/cecHT.
A database to support the evaluation of gender biases in GPT-4o output
Feb 28, 2025


The widespread application of Large Language Models (LLMs) involves ethical risks for users and societies. A prominent ethical risk of LLMs is the generation of unfair language output that reinforces or exacerbates harm for members of disadvantaged social groups through gender biases (Weidinger et al., 2022; Bender et al., 2021; Kotek et al., 2023). Hence, the evaluation of the fairness of LLM outputs with respect to such biases is a topic of rising interest. To advance research in this field, promote discourse on suitable normative bases and evaluation methodologies, and enhance the reproducibility of related studies, we propose a novel approach to database construction. This approach enables the assessment of gender-related biases in LLM-generated language beyond merely evaluating their degree of neutralization.
How desirable is alignment between LLMs and linguistically diverse human users?
Feb 18, 2025We discuss how desirable it is that Large Language Models (LLMs) be able to adapt or align their language behavior with users who may be diverse in their language use. User diversity may come about among others due to i) age differences; ii) gender characteristics, and/or iii) multilingual experience, and associated differences in language processing and use. We consider potential consequences for usability, communication, and LLM development.
Extending Information Bottleneck Attribution to Video Sequences
Jan 28, 2025



We introduce VIBA, a novel approach for explainable video classification by adapting Information Bottlenecks for Attribution (IBA) to video sequences. While most traditional explainability methods are designed for image models, our IBA framework addresses the need for explainability in temporal models used for video analysis. To demonstrate its effectiveness, we apply VIBA to video deepfake detection, testing it on two architectures: the Xception model for spatial features and a VGG11-based model for capturing motion dynamics through optical flow. Using a custom dataset that reflects recent deepfake generation techniques, we adapt IBA to create relevance and optical flow maps, visually highlighting manipulated regions and motion inconsistencies. Our results show that VIBA generates temporally and spatially consistent explanations, which align closely with human annotations, thus providing interpretability for video classification and particularly for deepfake detection.
Single-Model Attribution for Spoofed Speech via Vocoder Fingerprints in an Open-World Setting
Nov 21, 2024



As speech generation technology advances, so do the potential threats of misusing spoofed speech signals. One way to address these threats is by attributing the signals to their source generative model. In this work, we are the first to tackle the single-model attribution task in an open-world setting, that is, we aim at identifying whether spoofed speech signals from unknown sources originate from a specific vocoder. We show that the standardized average residual between audio signals and their low-pass filtered or EnCodec filtered versions can serve as powerful vocoder fingerprints. The approach only requires data from the target vocoder and allows for simple but highly accurate distance-based model attribution. We demonstrate its effectiveness on LJSpeech and JSUT, achieving an average AUROC of over 99% in most settings. The accompanying robustness study shows that it is also resilient to noise levels up to a certain degree.
Leveraging characteristics of the output probability distribution for identifying adversarial audio examples
May 26, 2023



Adversarial attacks represent a security threat to machine learning based automatic speech recognition (ASR) systems. To prevent such attacks we propose an adversarial example detection strategy applicable to any ASR system that predicts a probability distribution over output tokens in each time step. We measure a set of characteristics of this distribution: the median, maximum, and minimum over the output probabilities, the entropy, and the Jensen-Shannon divergence of the distributions of subsequent time steps. Then, we fit a Gaussian distribution to the characteristics observed for benign data. By computing the likelihood of incoming new audio we can distinguish malicious inputs from samples from clean data with an area under the receiving operator characteristic (AUROC) higher than 0.99, which drops to 0.98 for less-quality audio. To assess the robustness of our method we build adaptive attacks. This reduces the AUROC to 0.96 but results in more noisy adversarial clips.
RubCSG at SemEval-2022 Task 5: Ensemble learning for identifying misogynous MEMEs
Apr 08, 2022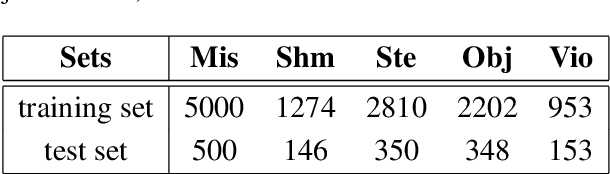
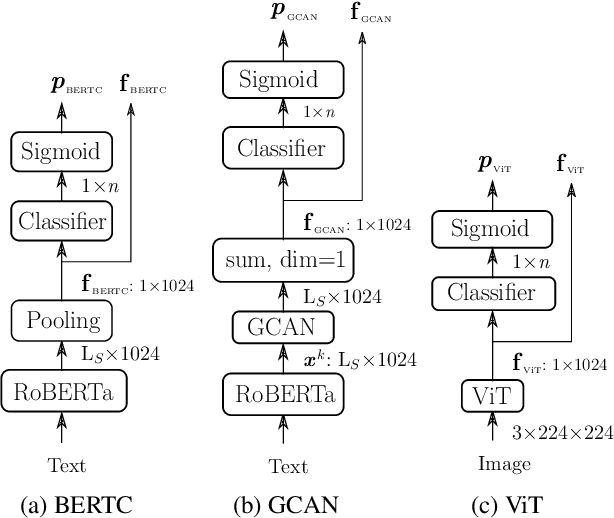
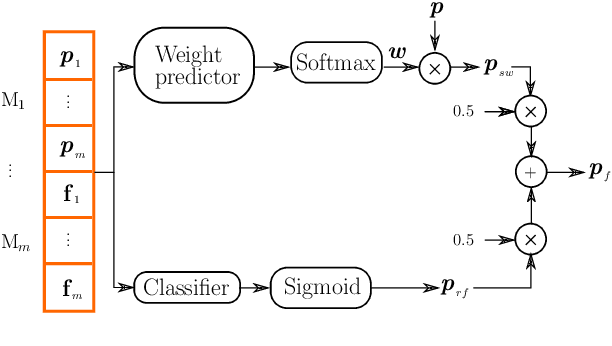
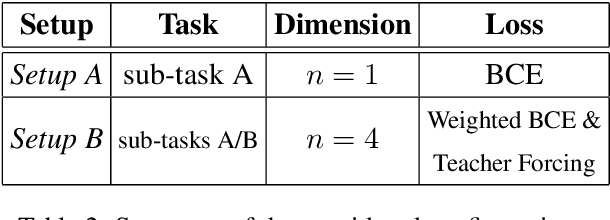
This work presents an ensemble system based on various uni-modal and bi-modal model architectures developed for the SemEval 2022 Task 5: MAMI-Multimedia Automatic Misogyny Identification. The challenge organizers provide an English meme dataset to develop and train systems for identifying and classifying misogynous memes. More precisely, the competition is separated into two sub-tasks: sub-task A asks for a binary decision as to whether a meme expresses misogyny, while sub-task B is to classify misogynous memes into the potentially overlapping sub-categories of stereotype, shaming, objectification, and violence. For our submission, we implement a new model fusion network and employ an ensemble learning approach for better performance. With this structure, we achieve a 0.755 macroaverage F1-score (11th) in sub-task A and a 0.709 weighted-average F1-score (10th) in sub-task B.
Robustifying automatic speech recognition by extracting slowly varying features
Dec 14, 2021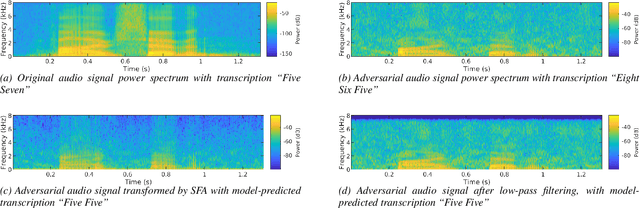
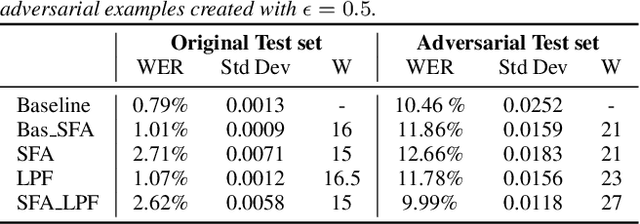
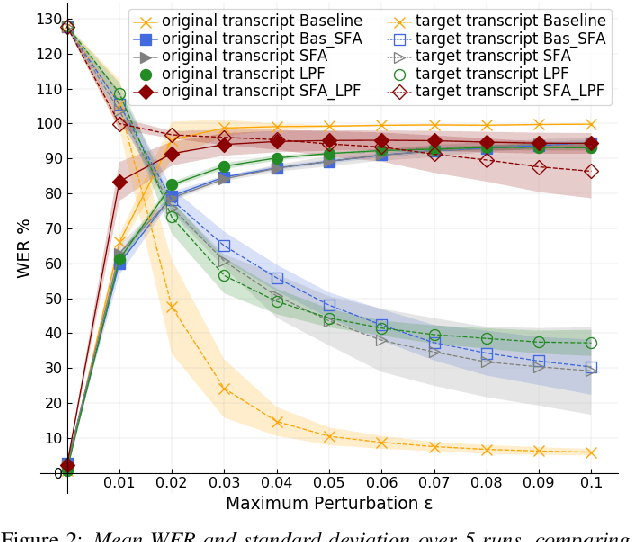
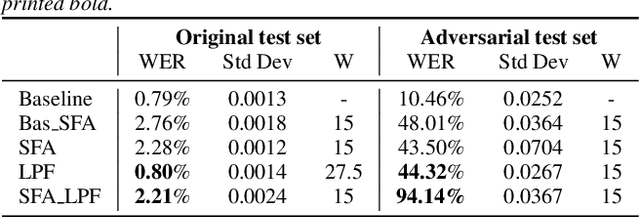
In the past few years, it has been shown that deep learning systems are highly vulnerable under attacks with adversarial examples. Neural-network-based automatic speech recognition (ASR) systems are no exception. Targeted and untargeted attacks can modify an audio input signal in such a way that humans still recognise the same words, while ASR systems are steered to predict a different transcription. In this paper, we propose a defense mechanism against targeted adversarial attacks consisting in removing fast-changing features from the audio signals, either by applying slow feature analysis, a low-pass filter, or both, before feeding the input to the ASR system. We perform an empirical analysis of hybrid ASR models trained on data pre-processed in such a way. While the resulting models perform quite well on benign data, they are significantly more robust against targeted adversarial attacks: Our final, proposed model shows a performance on clean data similar to the baseline model, while being more than four times more robust.
Federated Learning in ASR: Not as Easy as You Think
Sep 30, 2021
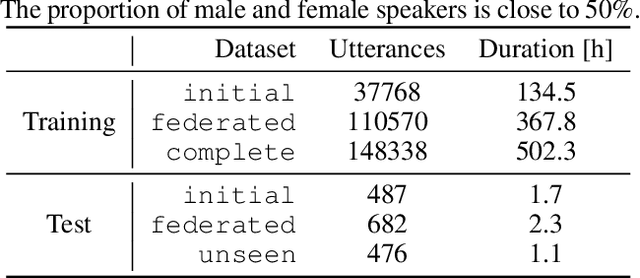
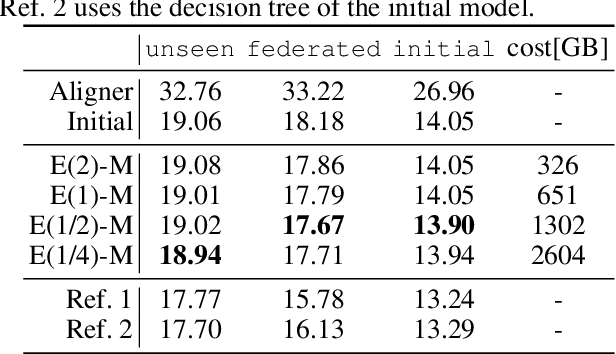
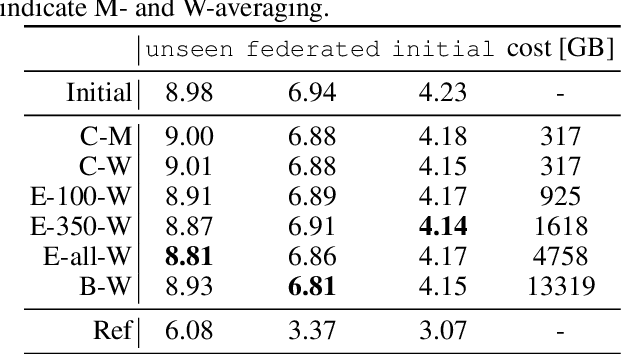
With the growing availability of smart devices and cloud services, personal speech assistance systems are increasingly used on a daily basis. Most devices redirect the voice recordings to a central server, which uses them for upgrading the recognizer model. This leads to major privacy concerns, since private data could be misused by the server or third parties. Federated learning is a decentralized optimization strategy that has been proposed to address such concerns. Utilizing this approach, private data is used for on-device training. Afterwards, updated model parameters are sent to the server to improve the global model, which is redistributed to the clients. In this work, we implement federated learning for speech recognition in a hybrid and an end-to-end model. We discuss the outcomes of these systems, which both show great similarities and only small improvements, pointing to a need for a deeper understanding of federated learning for speech recognition.
Large-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021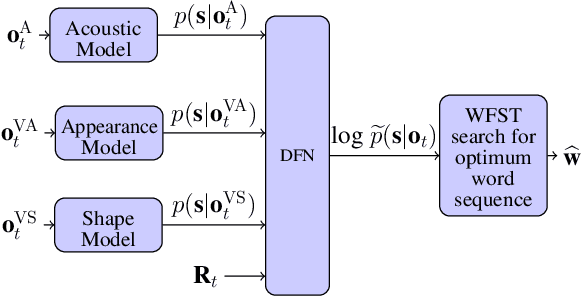
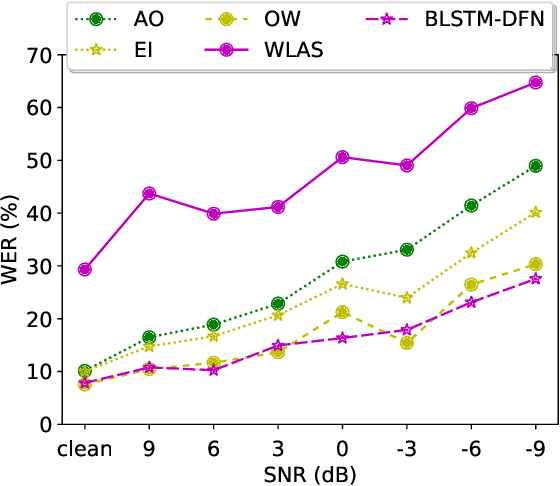

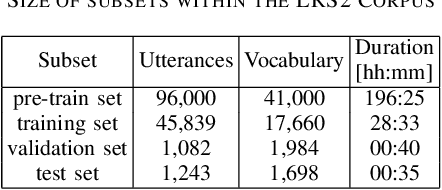
Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.