 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Model Learning and Adaptive Tracking Control of Magnetic Micro-Robots for Non-Contact Manipulation
Mar 21, 2024
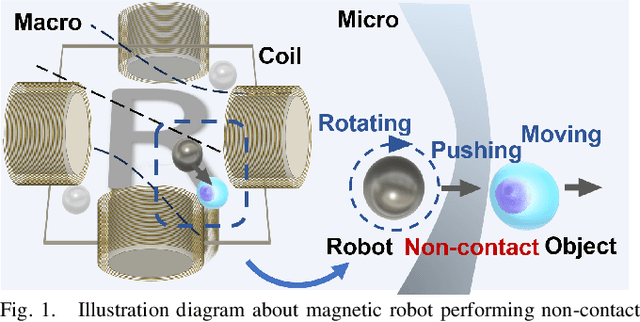
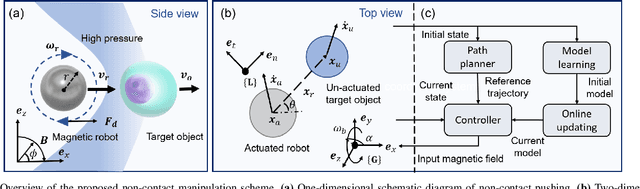
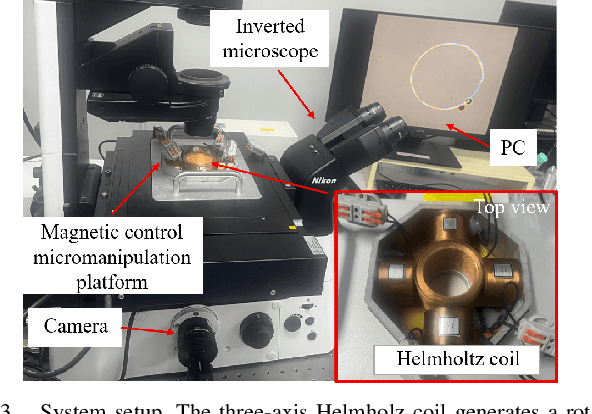
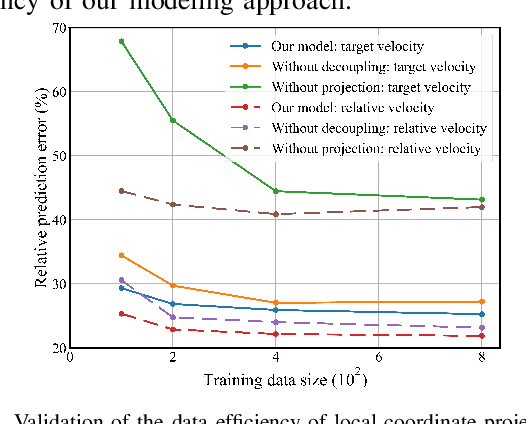
Magnetic microrobots can be navigated by an external magnetic field to autonomously move within living organisms with complex and unstructured environments. Potential applications include drug delivery, diagnostics, and therapeutic interventions. Existing techniques commonly impart magnetic properties to the target object,or drive the robot to contact and then manipulate the object, both probably inducing physical damage. This paper considers a non-contact formulation, where the robot spins to generate a repulsive field to push the object without physical contact. Under such a formulation, the main challenge is that the motion model between the input of the magnetic field and the output velocity of the target object is commonly unknown and difficult to analyze. To deal with it, this paper proposes a data-driven-based solution. A neural network is constructed to efficiently estimate the motion model. Then, an approximate model-based optimal control scheme is developed to push the object to track a time-varying trajectory, maintaining the non-contact with distance constraints. Furthermore, a straightforward planner is introduced to assess the adaptability of non-contact manipulation in a cluttered unstructured environment. Experimental results are presented to show the tracking and navigation performance of the proposed scheme.
Training point-based deep learning networks for forest segmentation with synthetic data
Mar 21, 2024
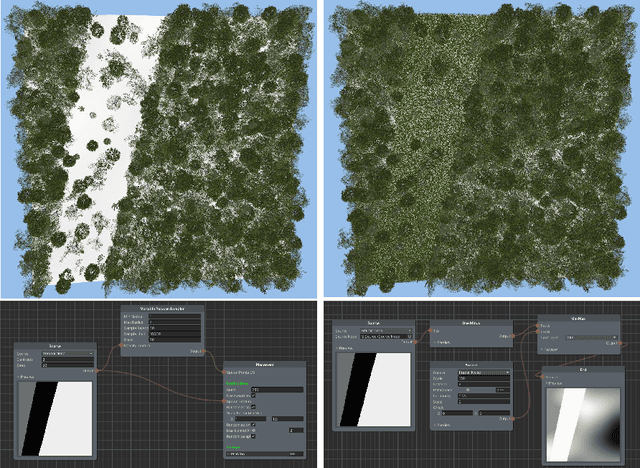


Remote sensing through unmanned aerial systems (UAS) has been increasing in forestry in recent years, along with using machine learning for data processing. Deep learning architectures, extensively applied in natural language and image processing, have recently been extended to the point cloud domain. However, the availability of point cloud datasets for training and testing remains limited. Creating forested environment point cloud datasets is expensive, requires high-precision sensors, and is time-consuming as manual point classification is required. Moreover, forest areas could be inaccessible or dangerous for humans, further complicating data collection. Then, a question arises whether it is possible to use synthetic data to train deep learning networks without the need to rely on large volumes of real forest data. To answer this question, we developed a realistic simulator that procedurally generates synthetic forest scenes. Thanks to this, we have conducted a comparative study of different state-of-the-art point-based deep learning networks for forest segmentation. Using created datasets, we determined the feasibility of using synthetic data to train deep learning networks to classify point clouds from real forest datasets. Both the simulator and the datasets are released as part of this work.
RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
Mar 21, 2024

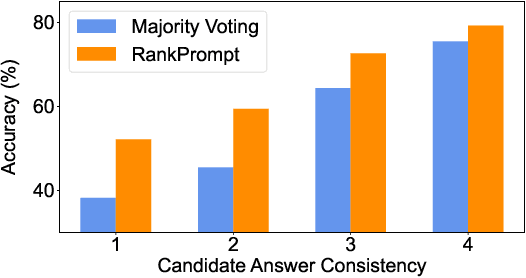
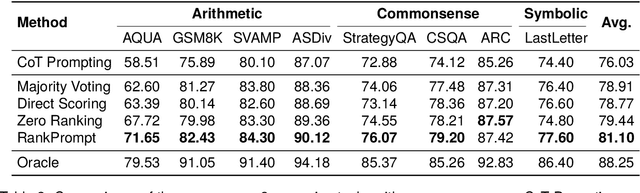
Large Language Models (LLMs) have achieved impressive performance across various reasoning tasks. However, even state-of-the-art LLMs such as ChatGPT are prone to logical errors during their reasoning processes. Traditional approaches to mitigate these errors involve human or tool-based feedback, such as employing task-specific verifiers or aggregating multiple reasoning paths. These methods, however, either depend heavily on human input or struggle with inconsistent responses. To overcome these limitations, we present RankPrompt, an innovative prompting strategy that empowers LLMs to autonomously rank their responses without needing extra resources. RankPrompt simplifies the ranking challenge into comparative evaluations among different responses, leveraging LLMs' innate ability to generate comparative examples within context. Our experiments across 11 arithmetic and commonsense reasoning tasks show that RankPrompt significantly enhances the reasoning performance of ChatGPT and GPT-4, with improvements of up to 13%. Furthermore, RankPrompt shows exceptional performance in LLM-based automatic evaluations for open-ended tasks, matching human judgments 74% of the time in the AlpacaEval dataset. It also proves to be robust against changes in response order and inconsistency. Overall, our findings endorse RankPrompt as an effective method for extracting high-quality feedback directly from language models.
Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations
Mar 21, 2024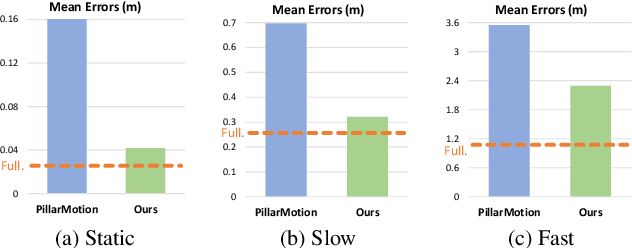
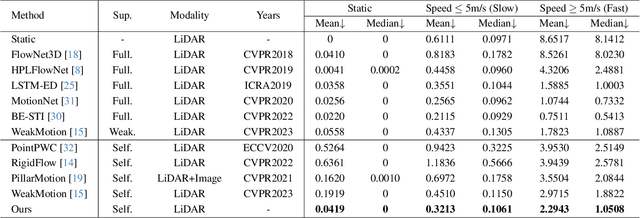
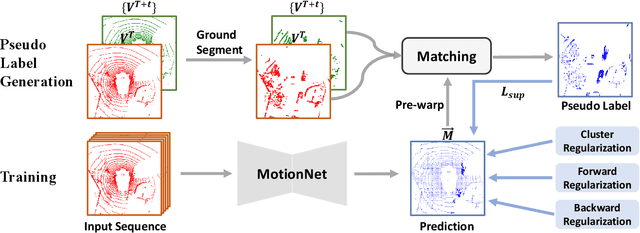
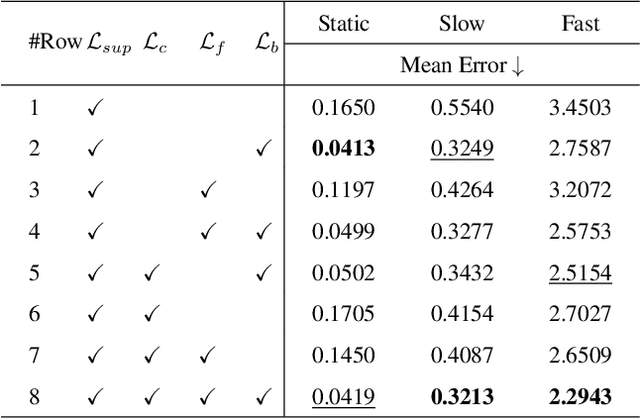
The perception of motion behavior in a dynamic environment holds significant importance for autonomous driving systems, wherein class-agnostic motion prediction methods directly predict the motion of the entire point cloud. While most existing methods rely on fully-supervised learning, the manual labeling of point cloud data is laborious and time-consuming. Therefore, several annotation-efficient methods have been proposed to address this challenge. Although effective, these methods rely on weak annotations or additional multi-modal data like images, and the potential benefits inherent in the point cloud sequence are still underexplored. To this end, we explore the feasibility of self-supervised motion prediction with only unlabeled LiDAR point clouds. Initially, we employ an optimal transport solver to establish coarse correspondences between current and future point clouds as the coarse pseudo motion labels. Training models directly using such coarse labels leads to noticeable spatial and temporal prediction inconsistencies. To mitigate these issues, we introduce three simple spatial and temporal regularization losses, which facilitate the self-supervised training process effectively. Experimental results demonstrate the significant superiority of our approach over the state-of-the-art self-supervised methods.
Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond
Mar 21, 2024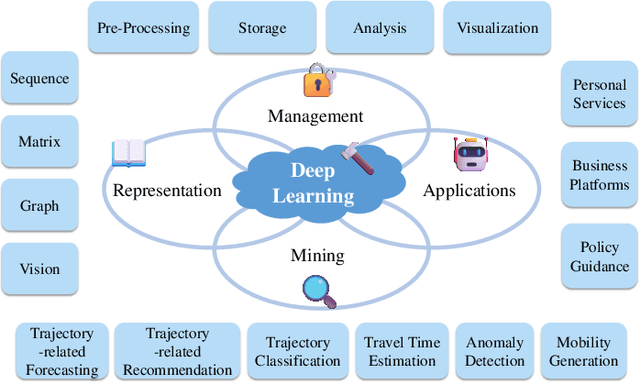
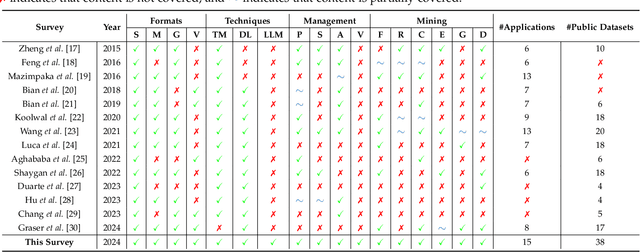
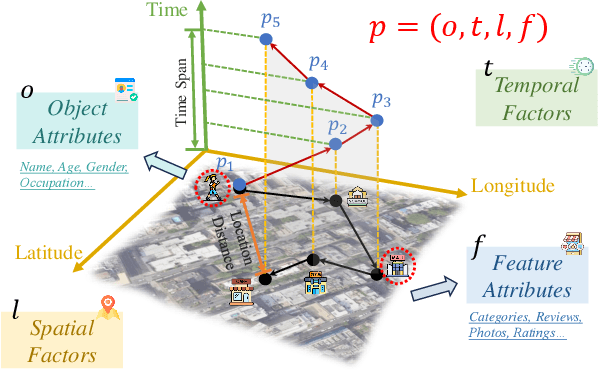
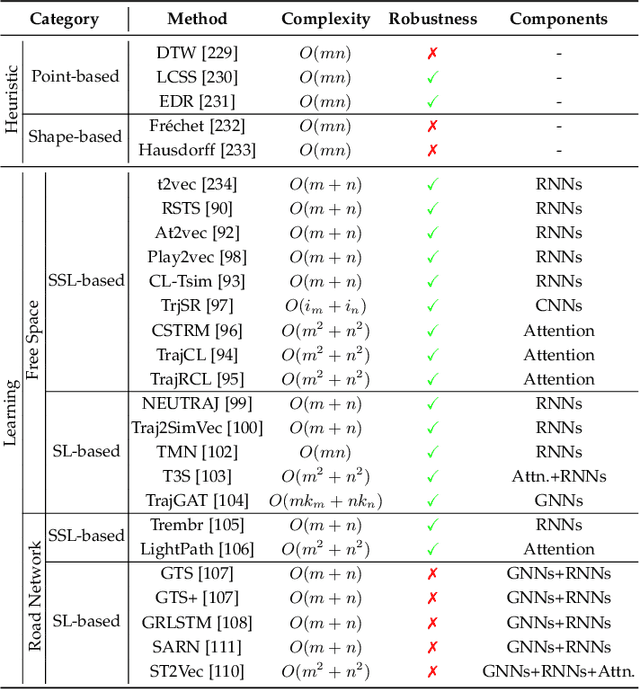
Trajectory computing is a pivotal domain encompassing trajectory data management and mining, garnering widespread attention due to its crucial role in various practical applications such as location services, urban traffic, and public safety. Traditional methods, focusing on simplistic spatio-temporal features, face challenges of complex calculations, limited scalability, and inadequate adaptability to real-world complexities. In this paper, we present a comprehensive review of the development and recent advances in deep learning for trajectory computing (DL4Traj). We first define trajectory data and provide a brief overview of widely-used deep learning models. Systematically, we explore deep learning applications in trajectory management (pre-processing, storage, analysis, and visualization) and mining (trajectory-related forecasting, trajectory-related recommendation, trajectory classification, travel time estimation, anomaly detection, and mobility generation). Notably, we encapsulate recent advancements in Large Language Models (LLMs) that hold the potential to augment trajectory computing. Additionally, we summarize application scenarios, public datasets, and toolkits. Finally, we outline current challenges in DL4Traj research and propose future directions. Relevant papers and open-source resources have been collated and are continuously updated at: \href{https://github.com/yoshall/Awesome-Trajectory-Computing}{DL4Traj Repo}.
A LiDAR-Aided Channel Model for Vehicular Intelligent Sensing-Communication Integration
Mar 21, 2024
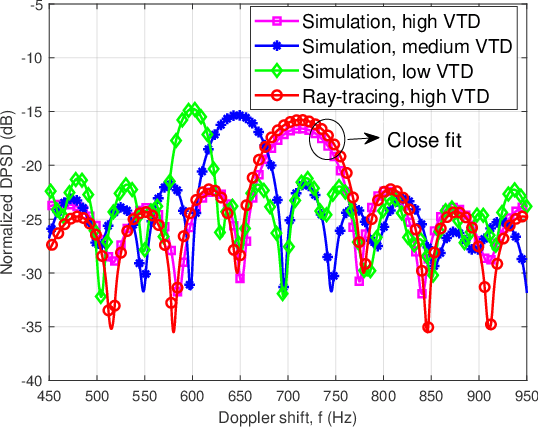
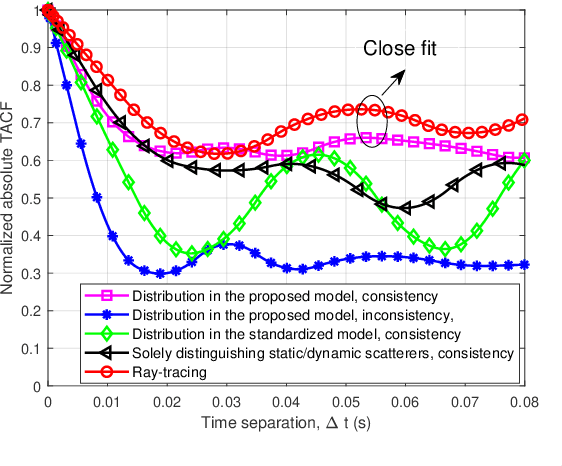
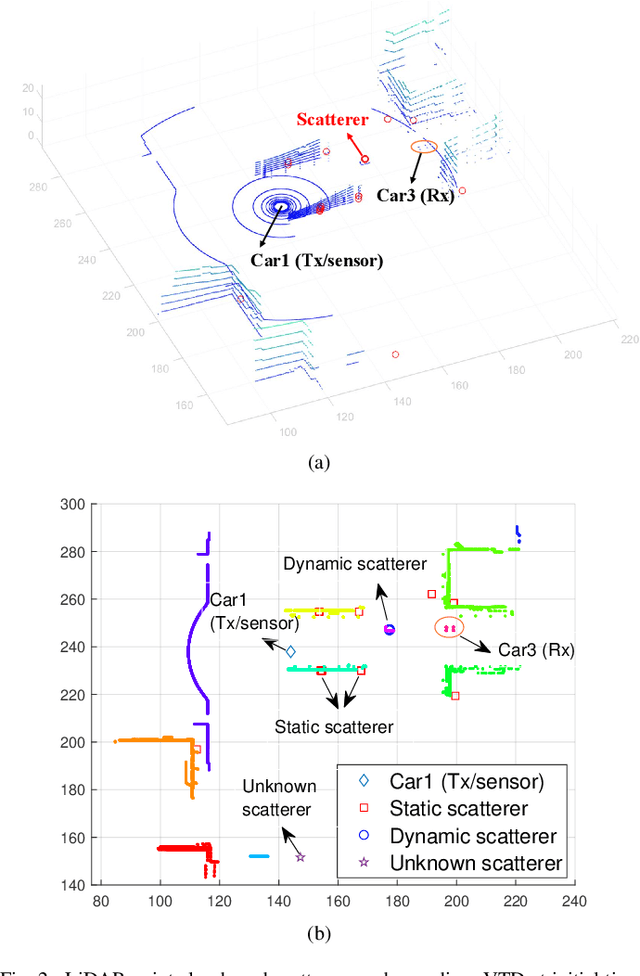
In this paper, a novel channel modeling approach, named light detection and ranging (LiDAR)-aided geometry-based stochastic modeling (LA-GBSM), is developed. Based on the developed LA-GBSM approach, a new millimeter wave (mmWave) channel model for sixth-generation (6G) vehicular intelligent sensing-communication integration is proposed, which can support the design of intelligent transportation systems (ITSs). The proposed LA-GBSM is accurately parameterized under high, medium, and low vehicular traffic density (VTD) conditions via a sensing-communication simulation dataset with LiDAR point clouds and scatterer information for the first time. Specifically, by detecting dynamic vehicles and static building/tress through LiDAR point clouds via machine learning, scatterers are divided into static and dynamic scatterers. Furthermore, statistical distributions of parameters, e.g., distance, angle, number, and power, related to static and dynamic scatterers are quantified under high, medium, and low VTD conditions. To mimic channel non-stationarity and consistency, based on the quantified statistical distributions, a new visibility region (VR)-based algorithm in consideration of newly generated static/dynamic scatterers is developed. Key channel statistics are derived and simulated. By comparing simulation results and ray-tracing (RT)-based results, the utility of the proposed LA-GBSM is verified.
Real-Time Simulated Avatar from Head-Mounted Sensors
Mar 11, 2024

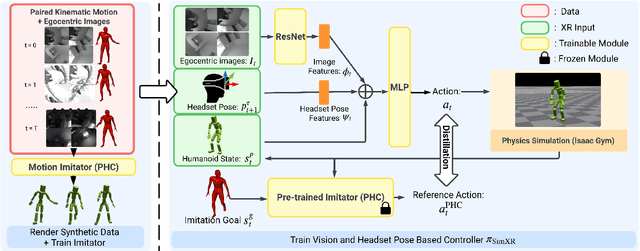
We present SimXR, a method for controlling a simulated avatar from information (headset pose and cameras) obtained from AR / VR headsets. Due to the challenging viewpoint of head-mounted cameras, the human body is often clipped out of view, making traditional image-based egocentric pose estimation challenging. On the other hand, headset poses provide valuable information about overall body motion, but lack fine-grained details about the hands and feet. To synergize headset poses with cameras, we control a humanoid to track headset movement while analyzing input images to decide body movement. When body parts are seen, the movements of hands and feet will be guided by the images; when unseen, the laws of physics guide the controller to generate plausible motion. We design an end-to-end method that does not rely on any intermediate representations and learns to directly map from images and headset poses to humanoid control signals. To train our method, we also propose a large-scale synthetic dataset created using camera configurations compatible with a commercially available VR headset (Quest 2) and show promising results on real-world captures. To demonstrate the applicability of our framework, we also test it on an AR headset with a forward-facing camera.
Towards a Comprehensive, Efficient and Promptable Anatomic Structure Segmentation Model using 3D Whole-body CT Scans
Mar 22, 2024Segment anything model (SAM) demonstrates strong generalization ability on natural image segmentation. However, its direct adaption in medical image segmentation tasks shows significant performance drops with inferior accuracy and unstable results. It may also requires an excessive number of prompt points to obtain a reasonable accuracy. For segmenting 3D radiological CT or MRI scans, a 2D SAM model has to separately handle hundreds of 2D slices. Although quite a few studies explore adapting SAM into medical image volumes, the efficiency of 2D adaption methods is unsatisfactory and 3D adaptation methods only capable of segmenting specific organs/tumors. In this work, we propose a comprehensive and scalable 3D SAM model for whole-body CT segmentation, named CT-SAM3D. Instead of adapting SAM, we propose a 3D promptable segmentation model using a (nearly) fully labeled CT dataset. To train CT-SAM3D effectively, ensuring the model's accurate responses to higher-dimensional spatial prompts is crucial, and 3D patch-wise training is required due to GPU memory constraints. For this purpose, we propose two key technical developments: 1) a progressively and spatially aligned prompt encoding method to effectively encode click prompts in local 3D space; and 2) a cross-patch prompt learning scheme to capture more 3D spatial context, which is beneficial for reducing the editing workloads when interactively prompting on large organs. CT-SAM3D is trained and validated using a curated dataset of 1204 CT scans containing 107 whole-body anatomies, reporting significantly better quantitative performance against all previous SAM-derived models by a large margin with much fewer click prompts. Our model can handle segmenting unseen organ as well. Code, data, and our 3D interactive segmentation tool with quasi-real-time responses will be made publicly available.
Extracting Human Attention through Crowdsourced Patch Labeling
Mar 22, 2024In image classification, a significant problem arises from bias in the datasets. When it contains only specific types of images, the classifier begins to rely on shortcuts - simplistic and erroneous rules for decision-making. This leads to high performance on the training dataset but inferior results on new, varied images, as the classifier's generalization capability is reduced. For example, if the images labeled as mustache consist solely of male figures, the model may inadvertently learn to classify images by gender rather than the presence of a mustache. One approach to mitigate such biases is to direct the model's attention toward the target object's location, usually marked using bounding boxes or polygons for annotation. However, collecting such annotations requires substantial time and human effort. Therefore, we propose a novel patch-labeling method that integrates AI assistance with crowdsourcing to capture human attention from images, which can be a viable solution for mitigating bias. Our method consists of two steps. First, we extract the approximate location of a target using a pre-trained saliency detection model supplemented by human verification for accuracy. Then, we determine the human-attentive area in the image by iteratively dividing the image into smaller patches and employing crowdsourcing to ascertain whether each patch can be classified as the target object. We demonstrated the effectiveness of our method in mitigating bias through improved classification accuracy and the refined focus of the model. Also, crowdsourced experiments validate that our method collects human annotation up to 3.4 times faster than annotating object locations with polygons, significantly reducing the need for human resources. We conclude the paper by discussing the advantages of our method in a crowdsourcing context, mainly focusing on aspects of human errors and accessibility.
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 22, 2024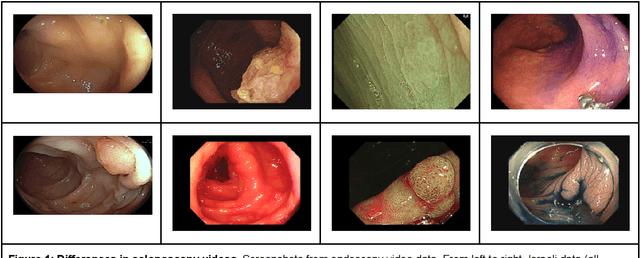
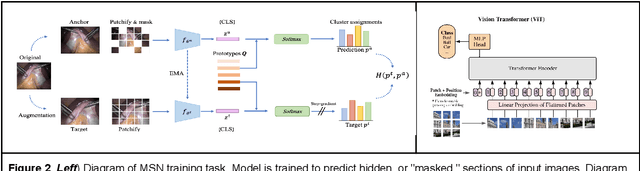
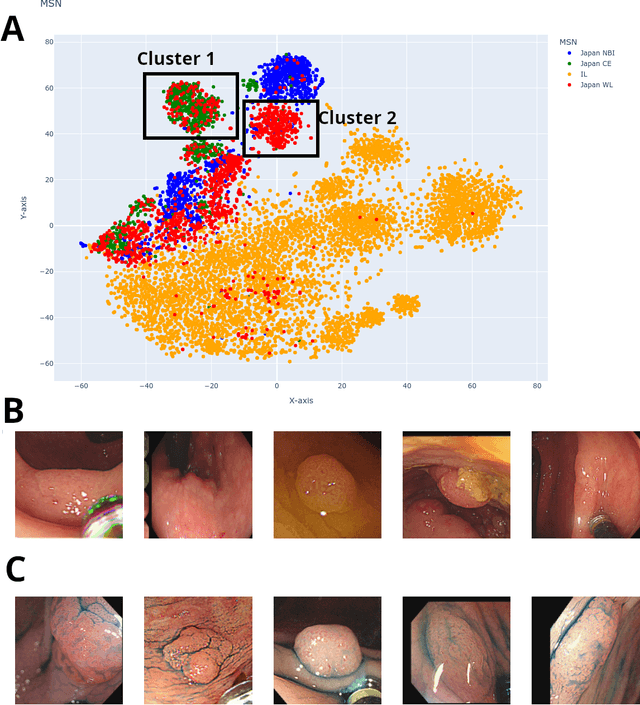
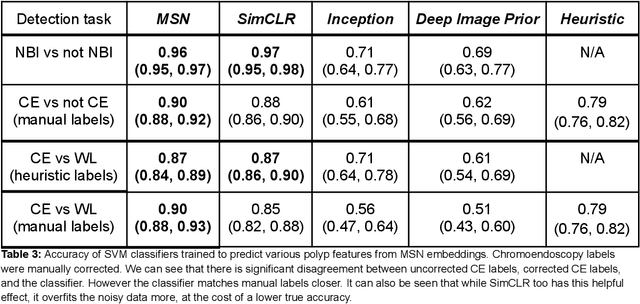
$\textbf{Background}$: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. $\textbf{Methods}$: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. $\textbf{Results}$: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). $\textbf{Conclusion}$: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.