 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Tail Auxiliary Learning for AI-Generated Image Detection
May 21, 2026As generative image models evolve rapidly, the perceptual gap between generated and real images continues to narrow, making AI-generated image detection increasingly challenging. Many existing methods exploit frequency-domain cues for detection, typically described as frequency-domain artifacts or high-frequency discrepancies. However, the specific and recurring spectral regularities remain insufficiently understood and characterized. In this paper, we systematically analyze the one-dimensional radial log-power spectra of real and generated images. We find that generated images do not necessarily exhibit higher or lower energy across the entire spectrum or high-band range. Instead, their spectra deviate from the power-law decay and show an anomalous uplift in the ultra-high-frequency tail. We term this phenomenon spectral tail uplift. We further attribute this phenomenon to nonlinear harmonic accumulation in trained generative models, suggesting that it can serve as a structural cue across generative architectures. Based on this observation, we propose Spectral Tail Auxiliary Learning (STAL), a frequency-domain auxiliary supervision framework for generalizable AI-generated image detection. STAL transfers spectral-tail cues from a tail-aware frequency teacher to a spatial detector during training, while all frequency-domain modules are discarded at inference time. Consequently, STAL introduces no inference overhead. Extensive experiments on 9 public datasets show that STAL achieves strong generalization and stability across generators, data distributions, and real-world scenarios.
CT-VoxelMap: Efficient Continuous-Time LiDAR-Inertial Odometry with Probabilistic Adaptive Voxel Mapping
Apr 04, 2026Maintaining stable and accurate localization during fast motion or on rough terrain remains highly challenging for mobile robots with onboard resources. Currently, multi-sensor fusion methods based on continuous-time representation offer a potential and effective solution to this challenge. Among these, spline-based methods provide an efficient and intuitive approach for continuous-time representation. Previous continuous-time odometry works based on B-splines either treat control points as variables to be estimated or perform estimation in quaternion space, which introduces complexity in deriving analytical Jacobians and often overlooks the fitting error between the spline and the true trajectory over time. To address these issues, we first propose representing the increments of control points on matrix Lie groups as variables to be estimated. Leveraging the feature of the cumulative form of B-splines, we derive a more compact formulation that yields simpler analytical Jacobians without requiring additional boundary condition considerations. Second, we utilize forward propagation information from IMU measurements to estimate fitting errors online and further introduce a hybrid feature-based voxel map management strategy, enhancing system accuracy and robustness. Finally, we propose a re-estimation policy that significantly improves system computational efficiency and robustness. The proposed method is evaluated on multiple challenging public datasets, demonstrating superior performance on most sequences. Detailed ablation studies are conducted to analyze the impact of each module on the overall pose estimation system.
iControl3D: An Interactive System for Controllable 3D Scene Generation
Aug 03, 2024



3D content creation has long been a complex and time-consuming process, often requiring specialized skills and resources. While recent advancements have allowed for text-guided 3D object and scene generation, they still fall short of providing sufficient control over the generation process, leading to a gap between the user's creative vision and the generated results. In this paper, we present iControl3D, a novel interactive system that empowers users to generate and render customizable 3D scenes with precise control. To this end, a 3D creator interface has been developed to provide users with fine-grained control over the creation process. Technically, we leverage 3D meshes as an intermediary proxy to iteratively merge individual 2D diffusion-generated images into a cohesive and unified 3D scene representation. To ensure seamless integration of 3D meshes, we propose to perform boundary-aware depth alignment before fusing the newly generated mesh with the existing one in 3D space. Additionally, to effectively manage depth discrepancies between remote content and foreground, we propose to model remote content separately with an environment map instead of 3D meshes. Finally, our neural rendering interface enables users to build a radiance field of their scene online and navigate the entire scene. Extensive experiments have been conducted to demonstrate the effectiveness of our system. The code will be made available at https://github.com/xingyi-li/iControl3D.
Instance Consistency Regularization for Semi-Supervised 3D Instance Segmentation
Jun 24, 2024



Large-scale datasets with point-wise semantic and instance labels are crucial to 3D instance segmentation but also expensive. To leverage unlabeled data, previous semi-supervised 3D instance segmentation approaches have explored self-training frameworks, which rely on high-quality pseudo labels for consistency regularization. They intuitively utilize both instance and semantic pseudo labels in a joint learning manner. However, semantic pseudo labels contain numerous noise derived from the imbalanced category distribution and natural confusion of similar but distinct categories, which leads to severe collapses in self-training. Motivated by the observation that 3D instances are non-overlapping and spatially separable, we ask whether we can solely rely on instance consistency regularization for improved semi-supervised segmentation. To this end, we propose a novel self-training network InsTeacher3D to explore and exploit pure instance knowledge from unlabeled data. We first build a parallel base 3D instance segmentation model DKNet, which distinguishes each instance from the others via discriminative instance kernels without reliance on semantic segmentation. Based on DKNet, we further design a novel instance consistency regularization framework to generate and leverage high-quality instance pseudo labels. Experimental results on multiple large-scale datasets show that the InsTeacher3D significantly outperforms prior state-of-the-art semi-supervised approaches. Code is available: https://github.com/W1zheng/InsTeacher3D.
Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations
Mar 21, 2024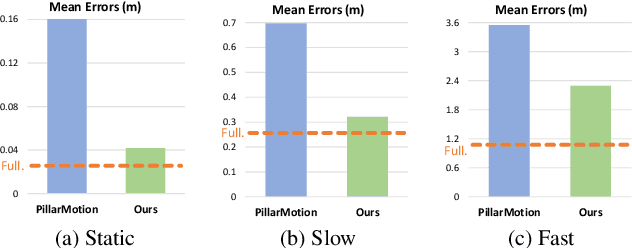
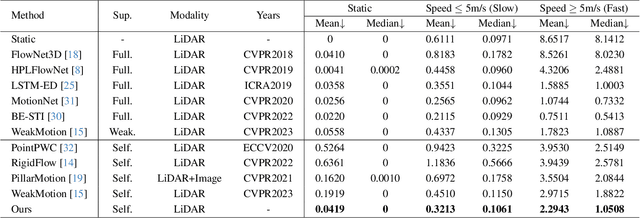
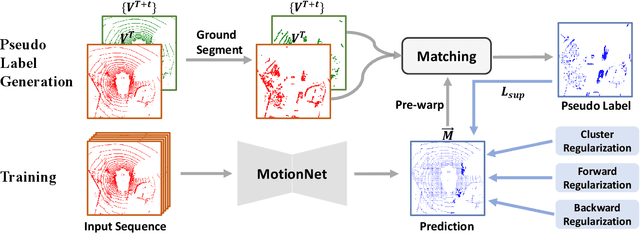
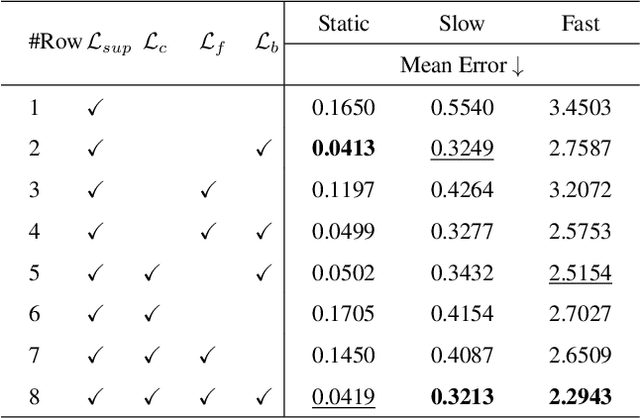
The perception of motion behavior in a dynamic environment holds significant importance for autonomous driving systems, wherein class-agnostic motion prediction methods directly predict the motion of the entire point cloud. While most existing methods rely on fully-supervised learning, the manual labeling of point cloud data is laborious and time-consuming. Therefore, several annotation-efficient methods have been proposed to address this challenge. Although effective, these methods rely on weak annotations or additional multi-modal data like images, and the potential benefits inherent in the point cloud sequence are still underexplored. To this end, we explore the feasibility of self-supervised motion prediction with only unlabeled LiDAR point clouds. Initially, we employ an optimal transport solver to establish coarse correspondences between current and future point clouds as the coarse pseudo motion labels. Training models directly using such coarse labels leads to noticeable spatial and temporal prediction inconsistencies. To mitigate these issues, we introduce three simple spatial and temporal regularization losses, which facilitate the self-supervised training process effectively. Experimental results demonstrate the significant superiority of our approach over the state-of-the-art self-supervised methods.
DyBluRF: Dynamic Neural Radiance Fields from Blurry Monocular Video
Mar 19, 2024Recent advancements in dynamic neural radiance field methods have yielded remarkable outcomes. However, these approaches rely on the assumption of sharp input images. When faced with motion blur, existing dynamic NeRF methods often struggle to generate high-quality novel views. In this paper, we propose DyBluRF, a dynamic radiance field approach that synthesizes sharp novel views from a monocular video affected by motion blur. To account for motion blur in input images, we simultaneously capture the camera trajectory and object Discrete Cosine Transform (DCT) trajectories within the scene. Additionally, we employ a global cross-time rendering approach to ensure consistent temporal coherence across the entire scene. We curate a dataset comprising diverse dynamic scenes that are specifically tailored for our task. Experimental results on our dataset demonstrate that our method outperforms existing approaches in generating sharp novel views from motion-blurred inputs while maintaining spatial-temporal consistency of the scene.
S-DyRF: Reference-Based Stylized Radiance Fields for Dynamic Scenes
Mar 13, 2024



Current 3D stylization methods often assume static scenes, which violates the dynamic nature of our real world. To address this limitation, we present S-DyRF, a reference-based spatio-temporal stylization method for dynamic neural radiance fields. However, stylizing dynamic 3D scenes is inherently challenging due to the limited availability of stylized reference images along the temporal axis. Our key insight lies in introducing additional temporal cues besides the provided reference. To this end, we generate temporal pseudo-references from the given stylized reference. These pseudo-references facilitate the propagation of style information from the reference to the entire dynamic 3D scene. For coarse style transfer, we enforce novel views and times to mimic the style details present in pseudo-references at the feature level. To preserve high-frequency details, we create a collection of stylized temporal pseudo-rays from temporal pseudo-references. These pseudo-rays serve as detailed and explicit stylization guidance for achieving fine style transfer. Experiments on both synthetic and real-world datasets demonstrate that our method yields plausible stylized results of space-time view synthesis on dynamic 3D scenes.
Semi-Supervised Class-Agnostic Motion Prediction with Pseudo Label Regeneration and BEVMix
Dec 14, 2023



Class-agnostic motion prediction methods aim to comprehend motion within open-world scenarios, holding significance for autonomous driving systems. However, training a high-performance model in a fully-supervised manner always requires substantial amounts of manually annotated data, which can be both expensive and time-consuming to obtain. To address this challenge, our study explores the potential of semi-supervised learning (SSL) for class-agnostic motion prediction. Our SSL framework adopts a consistency-based self-training paradigm, enabling the model to learn from unlabeled data by generating pseudo labels through test-time inference. To improve the quality of pseudo labels, we propose a novel motion selection and re-generation module. This module effectively selects reliable pseudo labels and re-generates unreliable ones. Furthermore, we propose two data augmentation strategies: temporal sampling and BEVMix. These strategies facilitate consistency regularization in SSL. Experiments conducted on nuScenes demonstrate that our SSL method can surpass the self-supervised approach by a large margin by utilizing only a tiny fraction of labeled data. Furthermore, our method exhibits comparable performance to weakly and some fully supervised methods. These results highlight the ability of our method to strike a favorable balance between annotation costs and performance. Code will be available at https://github.com/kwwcv/SSMP.
Make-It-4D: Synthesizing a Consistent Long-Term Dynamic Scene Video from a Single Image
Aug 20, 2023



We study the problem of synthesizing a long-term dynamic video from only a single image. This is challenging since it requires consistent visual content movements given large camera motions. Existing methods either hallucinate inconsistent perpetual views or struggle with long camera trajectories. To address these issues, it is essential to estimate the underlying 4D (including 3D geometry and scene motion) and fill in the occluded regions. To this end, we present Make-It-4D, a novel method that can generate a consistent long-term dynamic video from a single image. On the one hand, we utilize layered depth images (LDIs) to represent a scene, and they are then unprojected to form a feature point cloud. To animate the visual content, the feature point cloud is displaced based on the scene flow derived from motion estimation and the corresponding camera pose. Such 4D representation enables our method to maintain the global consistency of the generated dynamic video. On the other hand, we fill in the occluded regions by using a pretrained diffusion model to inpaint and outpaint the input image. This enables our method to work under large camera motions. Benefiting from our design, our method can be training-free which saves a significant amount of training time. Experimental results demonstrate the effectiveness of our approach, which showcases compelling rendering results.
SAD: Segment Any RGBD
May 23, 2023The Segment Anything Model (SAM) has demonstrated its effectiveness in segmenting any part of 2D RGB images. However, SAM exhibits a stronger emphasis on texture information while paying less attention to geometry information when segmenting RGB images. To address this limitation, we propose the Segment Any RGBD (SAD) model, which is specifically designed to extract geometry information directly from images. Inspired by the natural ability of humans to identify objects through the visualization of depth maps, SAD utilizes SAM to segment the rendered depth map, thus providing cues with enhanced geometry information and mitigating the issue of over-segmentation. We further include the open-vocabulary semantic segmentation in our framework, so that the 3D panoptic segmentation is fulfilled. The project is available on https://github.com/Jun-CEN/SegmentAnyRGBD.