 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Scaling Fails: Mitigating Audio Perception Decay of LALMs via Multi-Step Perception-Aware Reasoning
Feb 28, 2026Test-Time Scaling has shown notable efficacy in addressing complex problems through scaling inference compute. However, within Large Audio-Language Models (LALMs), an unintuitive phenomenon exists: post-training models for structured reasoning trajectories results in marginal or even negative gains compared to post-training for direct answering. To investigate it, we introduce CAFE, an evaluation framework designed to precisely quantify audio reasoning errors. Evaluation results reveal LALMs struggle with perception during reasoning and encounter a critical bottleneck: reasoning performance suffers from audio perception decay as reasoning length extends. To address it, we propose MPAR$^2$, a paradigm that encourages dynamic perceptual reasoning and decomposes complex questions into perception-rich sub-problems. Leveraging reinforcement learning, MPAR$^2$ improves perception performance on CAFE from 31.74% to 63.51% and effectively mitigates perception decay, concurrently enhancing reasoning capabilities to achieve a significant 74.59% accuracy on the MMAU benchmark. Further analysis demonstrates that MPAR$^2$ reinforces LALMs to attend to audio input and dynamically adapts reasoning budget to match task complexity.
EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
Sep 11, 2025Speech-to-speech large language models (SLLMs) are attracting increasing attention. Derived from text-based large language models (LLMs), SLLMs often exhibit degradation in knowledge and reasoning capabilities. We hypothesize that this limitation arises because current training paradigms for SLLMs fail to bridge the acoustic-semantic gap in the feature representation space. To address this issue, we propose EchoX, which leverages semantic representations and dynamically generates speech training targets. This approach integrates both acoustic and semantic learning, enabling EchoX to preserve strong reasoning abilities as a speech LLM. Experimental results demonstrate that EchoX, with about six thousand hours of training data, achieves advanced performance on multiple knowledge-based question-answering benchmarks. The project is available at https://github.com/FreedomIntelligence/EchoX.
SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
Aug 28, 2025Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.
Leveraging Unit Language Guidance to Advance Speech Modeling in Textless Speech-to-Speech Translation
May 21, 2025



The success of building textless speech-to-speech translation (S2ST) models has attracted much attention. However, S2ST still faces two main challenges: 1) extracting linguistic features for various speech signals, called cross-modal (CM), and 2) learning alignment of difference languages in long sequences, called cross-lingual (CL). We propose the unit language to overcome the two modeling challenges. The unit language can be considered a text-like representation format, constructed using $n$-gram language modeling. We implement multi-task learning to utilize the unit language in guiding the speech modeling process. Our initial results reveal a conflict when applying source and target unit languages simultaneously. We propose task prompt modeling to mitigate this conflict. We conduct experiments on four languages of the Voxpupil dataset. Our method demonstrates significant improvements over a strong baseline and achieves performance comparable to models trained with text.
RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
Mar 22, 2024



Large Language Models (LLMs) have achieved impressive performance across various reasoning tasks. However, even state-of-the-art LLMs such as ChatGPT are prone to logical errors during their reasoning processes. Existing solutions, such as deploying task-specific verifiers or voting over multiple reasoning paths, either require extensive human annotations or fail in scenarios with inconsistent responses. To address these challenges, we introduce RankPrompt, a new prompting method that enables LLMs to self-rank their responses without additional resources. RankPrompt breaks down the ranking problem into a series of comparisons among diverse responses, leveraging the inherent capabilities of LLMs to generate chains of comparison as contextual exemplars. Our experiments across 11 arithmetic and commonsense reasoning tasks show that RankPrompt significantly enhances the reasoning performance of ChatGPT and GPT-4, with improvements of up to 13%. Moreover, RankPrompt excels in LLM-based automatic evaluations for open-ended tasks, aligning with human judgments 74% of the time in the AlpacaEval dataset. It also exhibits robustness to variations in response order and consistency. Collectively, our results validate RankPrompt as an effective method for eliciting high-quality feedback from language models.
RankNAS: Efficient Neural Architecture Search by Pairwise Ranking
Sep 17, 2021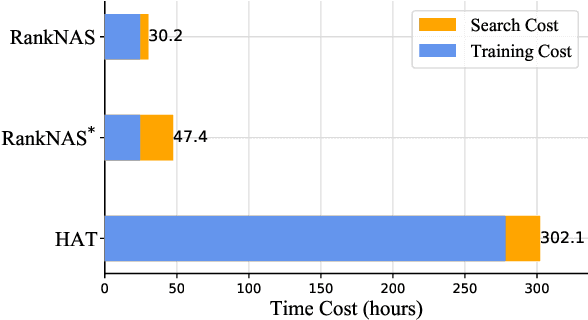
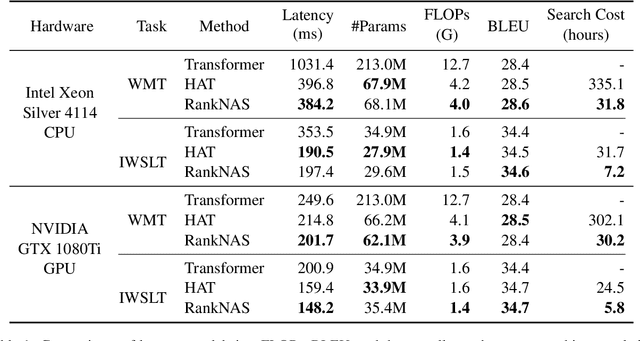
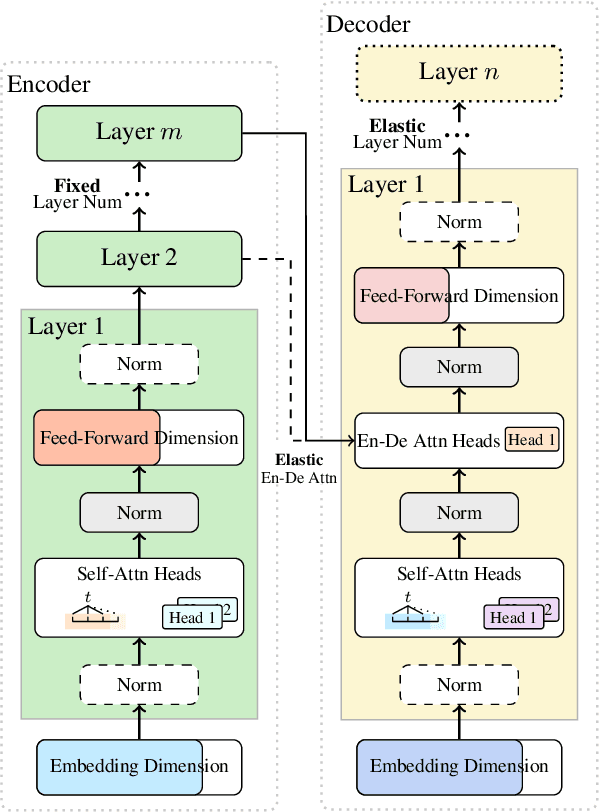
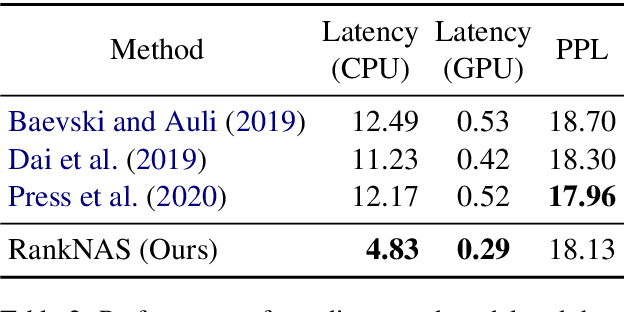
This paper addresses the efficiency challenge of Neural Architecture Search (NAS) by formulating the task as a ranking problem. Previous methods require numerous training examples to estimate the accurate performance of architectures, although the actual goal is to find the distinction between "good" and "bad" candidates. Here we do not resort to performance predictors. Instead, we propose a performance ranking method (RankNAS) via pairwise ranking. It enables efficient architecture search using much fewer training examples. Moreover, we develop an architecture selection method to prune the search space and concentrate on more promising candidates. Extensive experiments on machine translation and language modeling tasks show that RankNAS can design high-performance architectures while being orders of magnitude faster than state-of-the-art NAS systems.