 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Vision-Language Foundation Models as Effective Robot Imitators
Nov 06, 2023
Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step vision-language comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on language-conditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. We believe RoboFlamingo has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy.
Continual atlas-based segmentation of prostate MRI
Nov 06, 2023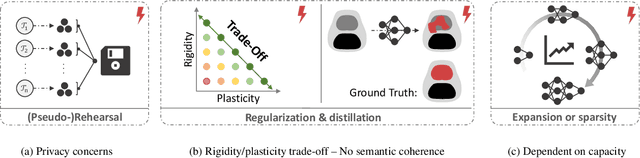
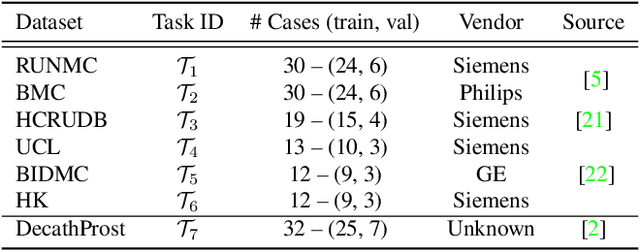
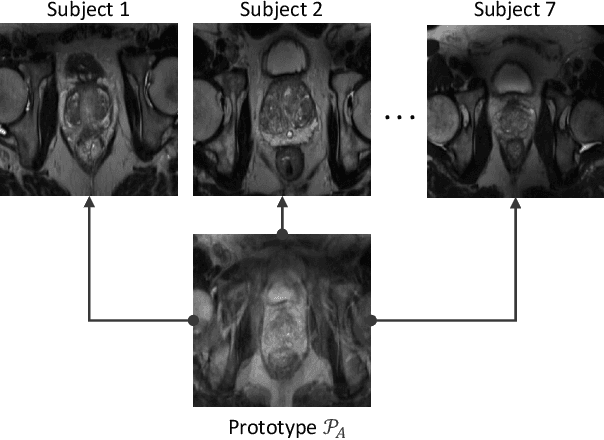
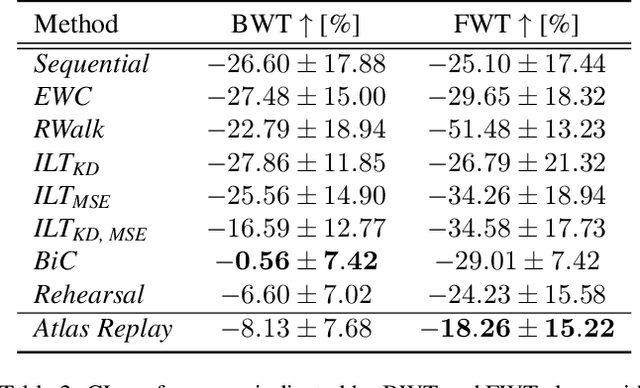
Continual learning (CL) methods designed for natural image classification often fail to reach basic quality standards for medical image segmentation. Atlas-based segmentation, a well-established approach in medical imaging, incorporates domain knowledge on the region of interest, leading to semantically coherent predictions. This is especially promising for CL, as it allows us to leverage structural information and strike an optimal balance between model rigidity and plasticity over time. When combined with privacy-preserving prototypes, this process offers the advantages of rehearsal-based CL without compromising patient privacy. We propose Atlas Replay, an atlas-based segmentation approach that uses prototypes to generate high-quality segmentation masks through image registration that maintain consistency even as the training distribution changes. We explore how our proposed method performs compared to state-of-the-art CL methods in terms of knowledge transferability across seven publicly available prostate segmentation datasets. Prostate segmentation plays a vital role in diagnosing prostate cancer, however, it poses challenges due to substantial anatomical variations, benign structural differences in older age groups, and fluctuating acquisition parameters. Our results show that Atlas Replay is both robust and generalizes well to yet-unseen domains while being able to maintain knowledge, unlike end-to-end segmentation methods. Our code base is available under https://github.com/MECLabTUDA/Atlas-Replay.
Zero-shot Bilingual App Reviews Mining with Large Language Models
Nov 06, 2023App reviews from app stores are crucial for improving software requirements. A large number of valuable reviews are continually being posted, describing software problems and expected features. Effectively utilizing user reviews necessitates the extraction of relevant information, as well as their subsequent summarization. Due to the substantial volume of user reviews, manual analysis is arduous. Various approaches based on natural language processing (NLP) have been proposed for automatic user review mining. However, the majority of them requires a manually crafted dataset to train their models, which limits their usage in real-world scenarios. In this work, we propose Mini-BAR, a tool that integrates large language models (LLMs) to perform zero-shot mining of user reviews in both English and French. Specifically, Mini-BAR is designed to (i) classify the user reviews, (ii) cluster similar reviews together, (iii) generate an abstractive summary for each cluster and (iv) rank the user review clusters. To evaluate the performance of Mini-BAR, we created a dataset containing 6,000 English and 6,000 French annotated user reviews and conducted extensive experiments. Preliminary results demonstrate the effectiveness and efficiency of Mini-BAR in requirement engineering by analyzing bilingual app reviews. (Replication package containing the code, dataset, and experiment setups on https://github.com/Jl-wei/mini-bar )
Beyond Words: A Mathematical Framework for Interpreting Large Language Models
Nov 06, 2023Large language models (LLMs) are powerful AI tools that can generate and comprehend natural language text and other complex information. However, the field lacks a mathematical framework to systematically describe, compare and improve LLMs. We propose Hex a framework that clarifies key terms and concepts in LLM research, such as hallucinations, alignment, self-verification and chain-of-thought reasoning. The Hex framework offers a precise and consistent way to characterize LLMs, identify their strengths and weaknesses, and integrate new findings. Using Hex, we differentiate chain-of-thought reasoning from chain-of-thought prompting and establish the conditions under which they are equivalent. This distinction clarifies the basic assumptions behind chain-of-thought prompting and its implications for methods that use it, such as self-verification and prompt programming. Our goal is to provide a formal framework for LLMs that can help both researchers and practitioners explore new possibilities for generative AI. We do not claim to have a definitive solution, but rather a tool for opening up new research avenues. We argue that our formal definitions and results are crucial for advancing the discussion on how to build generative AI systems that are safe, reliable, fair and robust, especially in domains like healthcare and software engineering.
EmojiLM: Modeling the New Emoji Language
Nov 03, 2023With the rapid development of the internet, online social media welcomes people with different backgrounds through its diverse content. The increasing usage of emoji becomes a noticeable trend thanks to emoji's rich information beyond cultural or linguistic borders. However, the current study on emojis is limited to single emoji prediction and there are limited data resources available for further study of the interesting linguistic phenomenon. To this end, we synthesize a large text-emoji parallel corpus, Text2Emoji, from a large language model. Based on the parallel corpus, we distill a sequence-to-sequence model, EmojiLM, which is specialized in the text-emoji bidirectional translation. Extensive experiments on public benchmarks and human evaluation demonstrate that our proposed model outperforms strong baselines and the parallel corpus benefits emoji-related downstream tasks.
Causal inference with Machine Learning-Based Covariate Representation
Nov 03, 2023Utilizing covariate information has been a powerful approach to improve the efficiency and accuracy for causal inference, which support massive amount of randomized experiments run on data-driven enterprises. However, state-of-art approaches can become practically unreliable when the dimension of covariate increases to just 50, whereas experiments on large platforms can observe even higher dimension of covariate. We propose a machine-learning-assisted covariate representation approach that can effectively make use of historical experiment or observational data that are run on the same platform to understand which lower dimensions can effectively represent the higher-dimensional covariate. We then propose design and estimation methods with the covariate representation. We prove statistically reliability and performance guarantees for the proposed methods. The empirical performance is demonstrated using numerical experiments.
Embrace Divergence for Richer Insights: A Multi-document Summarization Benchmark and a Case Study on Summarizing Diverse Information from News Articles
Sep 17, 2023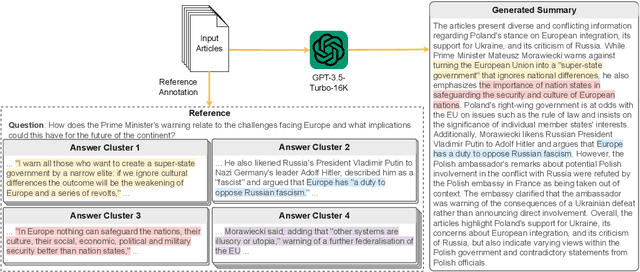

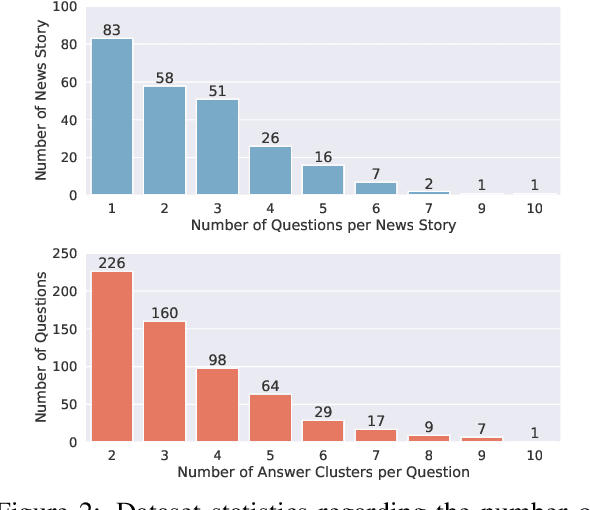
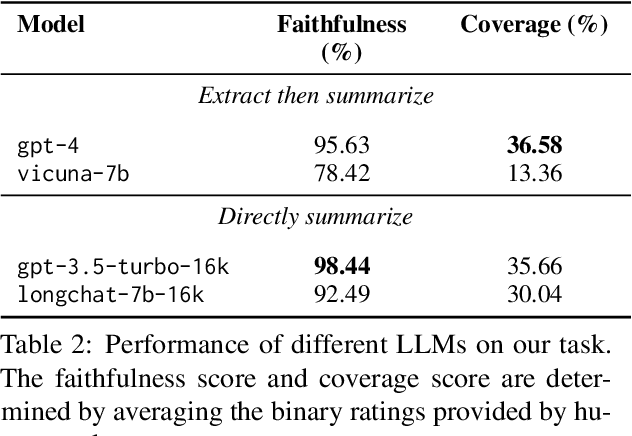
Previous research in multi-document news summarization has typically concentrated on collating information that all sources agree upon. However, to our knowledge, the summarization of diverse information dispersed across multiple articles about an event has not been previously investigated. The latter imposes a different set of challenges for a summarization model. In this paper, we propose a new task of summarizing diverse information encountered in multiple news articles encompassing the same event. To facilitate this task, we outlined a data collection schema for identifying diverse information and curated a dataset named DiverseSumm. The dataset includes 245 news stories, with each story comprising 10 news articles and paired with a human-validated reference. Moreover, we conducted a comprehensive analysis to pinpoint the position and verbosity biases when utilizing Large Language Model (LLM)-based metrics for evaluating the coverage and faithfulness of the summaries, as well as their correlation with human assessments. We applied our findings to study how LLMs summarize multiple news articles by analyzing which type of diverse information LLMs are capable of identifying. Our analyses suggest that despite the extraordinary capabilities of LLMs in single-document summarization, the proposed task remains a complex challenge for them mainly due to their limited coverage, with GPT-4 only able to cover less than 40% of the diverse information on average.
Towards Grouping in Large Scenes with Occlusion-aware Spatio-temporal Transformers
Oct 30, 2023Group detection, especially for large-scale scenes, has many potential applications for public safety and smart cities. Existing methods fail to cope with frequent occlusions in large-scale scenes with multiple people, and are difficult to effectively utilize spatio-temporal information. In this paper, we propose an end-to-end framework,GroupTransformer, for group detection in large-scale scenes. To deal with the frequent occlusions caused by multiple people, we design an occlusion encoder to detect and suppress severely occluded person crops. To explore the potential spatio-temporal relationship, we propose spatio-temporal transformers to simultaneously extract trajectory information and fuse inter-person features in a hierarchical manner. Experimental results on both large-scale and small-scale scenes demonstrate that our method achieves better performance compared with state-of-the-art methods. On large-scale scenes, our method significantly boosts the performance in terms of precision and F1 score by more than 10%. On small-scale scenes, our method still improves the performance of F1 score by more than 5%. The project page with code can be found at http://cic.tju.edu.cn/faculty/likun/projects/GroupTrans.
* 11 pages, 5 figures
Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents
Oct 30, 2023

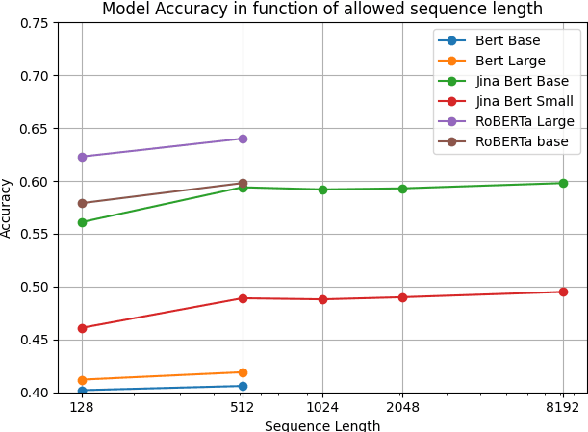
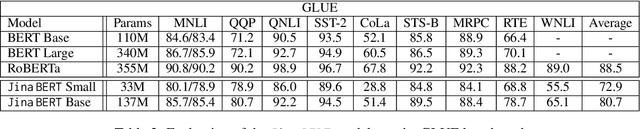
Text embedding models have emerged as powerful tools for transforming sentences into fixed-sized feature vectors that encapsulate semantic information. While these models are essential for tasks like information retrieval, semantic clustering, and text re-ranking, most existing open-source models, especially those built on architectures like BERT, struggle to represent lengthy documents and often resort to truncation. One common approach to mitigate this challenge involves splitting documents into smaller paragraphs for embedding. However, this strategy results in a much larger set of vectors, consequently leading to increased memory consumption and computationally intensive vector searches with elevated latency. To address these challenges, we introduce Jina Embeddings 2, an open-source text embedding model capable of accommodating up to 8192 tokens. This model is designed to transcend the conventional 512-token limit and adeptly process long documents. Jina Embeddings 2 not only achieves state-of-the-art performance on a range of embedding-related tasks in the MTEB benchmark but also matches the performance of OpenAI's proprietary ada-002 model. Additionally, our experiments indicate that an extended context can enhance performance in tasks such as NarrativeQA.
Reboost Large Language Model-based Text-to-SQL, Text-to-Python, and Text-to-Function -- with Real Applications in Traffic Domain
Oct 28, 2023Previous state-of-the-art (SOTA) method achieved a remarkable execution accuracy on the Spider dataset, which is one of the largest and most diverse datasets in the Text-to-SQL domain. However, during our reproduce of the business dataset, we observed a significant drop in performance. We examined the differences in dataset complexity, as well as the clarity of questions' intentions, and assessed how those differences could impact the performance of prompting methods. Subsequently, We develop a more adaptable and more general prompting method, involving mainly query rewriting and SQL boosting, which respectively transform vague information into exact and precise information and enhance the SQL itself by incorporating execution feedback and the query results from the database content. In order to prevent information gaps, we include the comments, value types, and value samples for columns as part of the database description in the prompt. Our experiments with Large Language Models (LLMs) illustrate the significant performance improvement on the business dataset and prove the substantial potential of our method. In terms of execution accuracy on the business dataset, the SOTA method scored 21.05, while our approach scored 65.79. As a result, our approach achieved a notable performance improvement even when using a less capable pre-trained language model. Last but not the least, we also explore the Text-to-Python and Text-to-Function options, and we deeply analyze the pros and cons among them, offering valuable insights to the community.