 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy
Aug 26, 2024The robotics community has consistently aimed to achieve generalizable robot manipulation with flexible natural language instructions. One of the primary challenges is that obtaining robot data fully annotated with both actions and texts is time-consuming and labor-intensive. However, partially annotated data, such as human activity videos without action labels and robot play data without language labels, is much easier to collect. Can we leverage these data to enhance the generalization capability of robots? In this paper, we propose GR-MG, a novel method which supports conditioning on both a language instruction and a goal image. During training, GR-MG samples goal images from trajectories and conditions on both the text and the goal image or solely on the image when text is unavailable. During inference, where only the text is provided, GR-MG generates the goal image via a diffusion-based image-editing model and condition on both the text and the generated image. This approach enables GR-MG to leverage large amounts of partially annotated data while still using language to flexibly specify tasks. To generate accurate goal images, we propose a novel progress-guided goal image generation model which injects task progress information into the generation process, significantly improving the fidelity and the performance. In simulation experiments, GR-MG improves the average number of tasks completed in a row of 5 from 3.35 to 4.04. In real-robot experiments, GR-MG is able to perform 47 different tasks and improves the success rate from 62.5% to 75.0% and 42.4% to 57.6% in simple and generalization settings, respectively. Code and checkpoints will be available at the project page: https://gr-mg.github.io/.
IRASim: Learning Interactive Real-Robot Action Simulators
Jun 20, 2024



Scalable robot learning in the real world is limited by the cost and safety issues of real robots. In addition, rolling out robot trajectories in the real world can be time-consuming and labor-intensive. In this paper, we propose to learn an interactive real-robot action simulator as an alternative. We introduce a novel method, IRASim, which leverages the power of generative models to generate extremely realistic videos of a robot arm that executes a given action trajectory, starting from an initial given frame. To validate the effectiveness of our method, we create a new benchmark, IRASim Benchmark, based on three real-robot datasets and perform extensive experiments on the benchmark. Results show that IRASim outperforms all the baseline methods and is more preferable in human evaluations. We hope that IRASim can serve as an effective and scalable approach to enhance robot learning in the real world. To promote research for generative real-robot action simulators, we open-source code, benchmark, and checkpoints at https: //gen-irasim.github.io.
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Dec 21, 2023



Generative pre-trained models have demonstrated remarkable effectiveness in language and vision domains by learning useful representations. In this paper, we extend the scope of this effectiveness by showing that visual robot manipulation can significantly benefit from large-scale video generative pre-training. We introduce GR-1, a straightforward GPT-style model designed for multi-task language-conditioned visual robot manipulation. GR-1 takes as inputs a language instruction, a sequence of observation images, and a sequence of robot states. It predicts robot actions as well as future images in an end-to-end manner. Thanks to a flexible design, GR-1 can be seamlessly finetuned on robot data after pre-trained on a large-scale video dataset. We perform extensive experiments on the challenging CALVIN benchmark and a real robot. On CALVIN benchmark, our method outperforms state-of-the-art baseline methods and improves the success rate from 88.9% to 94.9%. In the setting of zero-shot unseen scene generalization, GR-1 improves the success rate from 53.3% to 85.4%. In real robot experiments, GR-1 also outperforms baseline methods and shows strong potentials in generalization to unseen scenes and objects. We provide inaugural evidence that a unified GPT-style transformer, augmented with large-scale video generative pre-training, exhibits remarkable generalization to multi-task visual robot manipulation. Project page: https://GR1-Manipulation.github.io
Vision-Language Foundation Models as Effective Robot Imitators
Nov 06, 2023



Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step vision-language comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on language-conditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. We believe RoboFlamingo has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy.
Learning 6-DoF Object Poses to Grasp Category-level Objects by Language Instructions
May 09, 2022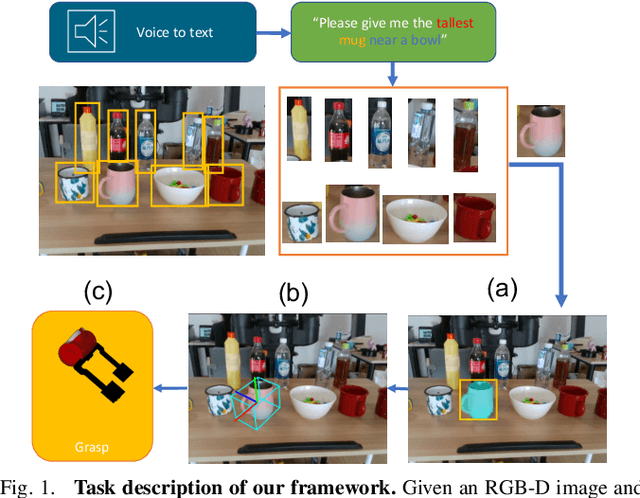

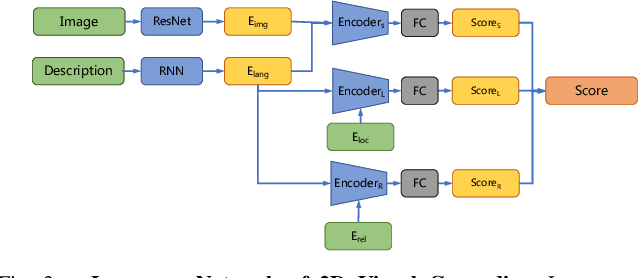

This paper studies the task of any objects grasping from the known categories by free-form language instructions. This task demands the technique in computer vision, natural language processing, and robotics. We bring these disciplines together on this open challenge, which is essential to human-robot interaction. Critically, the key challenge lies in inferring the category of objects from linguistic instructions and accurately estimating the 6-DoF information of unseen objects from the known classes. In contrast, previous works focus on inferring the pose of object candidates at the instance level. This significantly limits its applications in real-world scenarios.In this paper, we propose a language-guided 6-DoF category-level object localization model to achieve robotic grasping by comprehending human intention. To this end, we propose a novel two-stage method. Particularly, the first stage grounds the target in the RGB image through language description of names, attributes, and spatial relations of objects. The second stage extracts and segments point clouds from the cropped depth image and estimates the full 6-DoF object pose at category-level. Under such a manner, our approach can locate the specific object by following human instructions, and estimate the full 6-DoF pose of a category-known but unseen instance which is not utilized for training the model. Extensive experimental results show that our method is competitive with the state-of-the-art language-conditioned grasp method. Importantly, we deploy our approach on a physical robot to validate the usability of our framework in real-world applications. Please refer to the supplementary for the demo videos of our robot experiments.
I Know What You Draw: Learning Grasp Detection Conditioned on a Few Freehand Sketches
May 09, 2022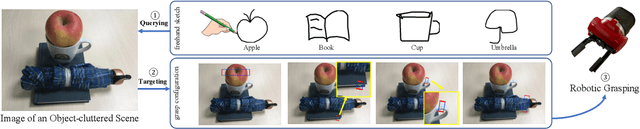
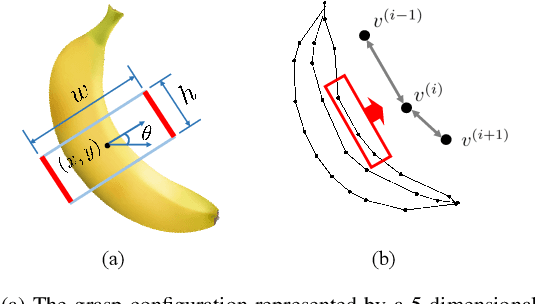
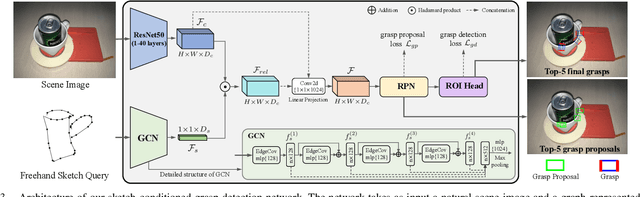

In this paper, we are interested in the problem of generating target grasps by understanding freehand sketches. The sketch is useful for the persons who cannot formulate language and the cases where a textual description is not available on the fly. However, very few works are aware of the usability of this novel interactive way between humans and robots. To this end, we propose a method to generate a potential grasp configuration relevant to the sketch-depicted objects. Due to the inherent ambiguity of sketches with abstract details, we take the advantage of the graph by incorporating the structure of the sketch to enhance the representation ability. This graph-represented sketch is further validated to improve the generalization of the network, capable of learning the sketch-queried grasp detection by using a small collection (around 100 samples) of hand-drawn sketches. Additionally, our model is trained and tested in an end-to-end manner which is easy to be implemented in real-world applications. Experiments on the multi-object VMRD and GraspNet-1Billion datasets demonstrate the good generalization of the proposed method. The physical robot experiments confirm the utility of our method in object-cluttered scenes.
DONet: Learning Category-Level 6D Object Pose and Size Estimation from Depth Observation
Jun 27, 2021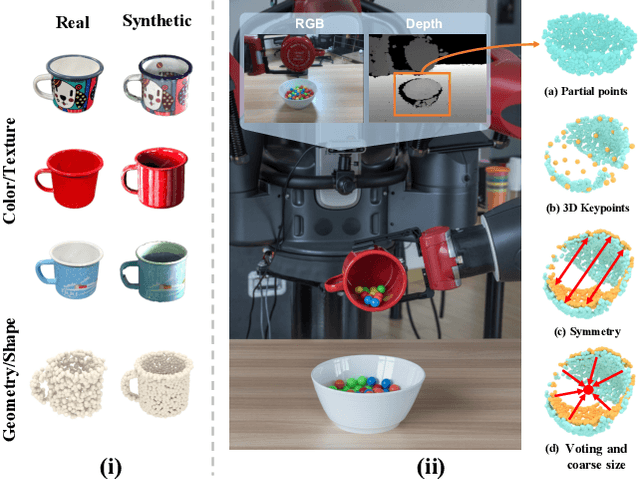
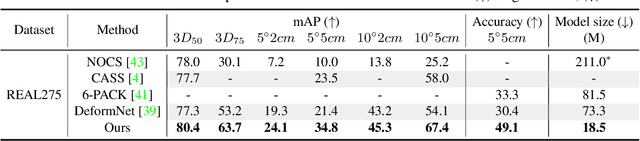
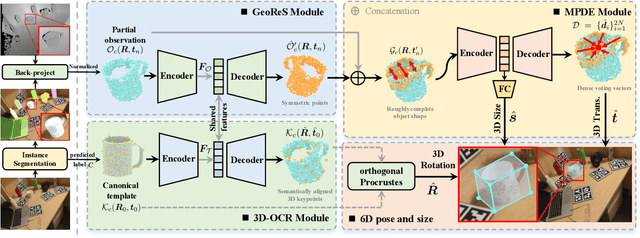
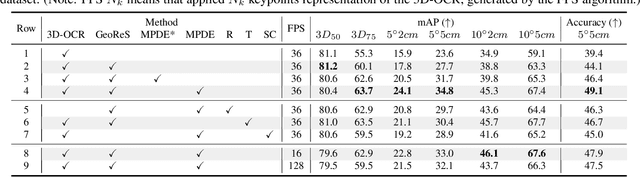
We propose a method of Category-level 6D Object Pose and Size Estimation (COPSE) from a single depth image, without external pose-annotated real-world training data. While previous works exploit visual cues in RGB(D) images, our method makes inferences based on the rich geometric information of the object in the depth channel alone. Essentially, our framework explores such geometric information by learning the unified 3D Orientation-Consistent Representations (3D-OCR) module, and further enforced by the property of Geometry-constrained Reflection Symmetry (GeoReS) module. The magnitude information of object size and the center point is finally estimated by Mirror-Paired Dimensional Estimation (MPDE) module. Extensive experiments on the category-level NOCS benchmark demonstrate that our framework competes with state-of-the-art approaches that require labeled real-world images. We also deploy our approach to a physical Baxter robot to perform manipulation tasks on unseen but category-known instances, and the results further validate the efficacy of our proposed model. Our videos are available in the supplementary material.