 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffVC: A Non-autoregressive Framework Based on Diffusion Model for Video Captioning
Apr 09, 2026Current video captioning methods usually use an encoder-decoder structure to generate text autoregressively. However, autoregressive methods have inherent limitations such as slow generation speed and large cumulative error. Furthermore, the few non-autoregressive counterparts suffer from deficiencies in generation quality due to the lack of sufficient multimodal interaction modeling. Therefore, we propose a non-autoregressive framework based on Diffusion model for Video Captioning (DiffVC) to address these issues. Its parallel decoding can effectively solve the problems of generation speed and cumulative error. At the same time, our proposed discriminative conditional Diffusion Model can generate higher-quality textual descriptions. Specifically, we first encode the video into a visual representation. During training, Gaussian noise is added to the textual representation of the ground-truth caption. Then, a new textual representation is generated via the discriminative denoiser with the visual representation as a conditional constraint. Finally, we input the new textual representation into a non-autoregressive language model to generate captions. During inference, we directly sample noise from the Gaussian distribution for generation. Experiments on MSVD, MSR-VTT, and VATEX show that our method can outperform previous non-autoregressive methods and achieve comparable performance to autoregressive methods, e.g., it achieved a maximum improvement of 9.9 on the CIDEr and improvement of 2.6 on the B@4, while having faster generation speed. The source code will be available soon.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024



We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
Knowledge Boundary and Persona Dynamic Shape A Better Social Media Agent
Apr 02, 2024Constructing personalized and anthropomorphic agents holds significant importance in the simulation of social networks. However, there are still two key problems in existing works: the agent possesses world knowledge that does not belong to its personas, and it cannot eliminate the interference of diverse persona information on current actions, which reduces the personalization and anthropomorphism of the agent. To solve the above problems, we construct the social media agent based on personalized knowledge and dynamic persona information. For personalized knowledge, we add external knowledge sources and match them with the persona information of agents, thereby giving the agent personalized world knowledge. For dynamic persona information, we use current action information to internally retrieve the persona information of the agent, thereby reducing the interference of diverse persona information on the current action. To make the agent suitable for social media, we design five basic modules for it: persona, planning, action, memory and reflection. To provide an interaction and verification environment for the agent, we build a social media simulation sandbox. In the experimental verification, automatic and human evaluations demonstrated the effectiveness of the agent we constructed.
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Dec 21, 2023



Generative pre-trained models have demonstrated remarkable effectiveness in language and vision domains by learning useful representations. In this paper, we extend the scope of this effectiveness by showing that visual robot manipulation can significantly benefit from large-scale video generative pre-training. We introduce GR-1, a straightforward GPT-style model designed for multi-task language-conditioned visual robot manipulation. GR-1 takes as inputs a language instruction, a sequence of observation images, and a sequence of robot states. It predicts robot actions as well as future images in an end-to-end manner. Thanks to a flexible design, GR-1 can be seamlessly finetuned on robot data after pre-trained on a large-scale video dataset. We perform extensive experiments on the challenging CALVIN benchmark and a real robot. On CALVIN benchmark, our method outperforms state-of-the-art baseline methods and improves the success rate from 88.9% to 94.9%. In the setting of zero-shot unseen scene generalization, GR-1 improves the success rate from 53.3% to 85.4%. In real robot experiments, GR-1 also outperforms baseline methods and shows strong potentials in generalization to unseen scenes and objects. We provide inaugural evidence that a unified GPT-style transformer, augmented with large-scale video generative pre-training, exhibits remarkable generalization to multi-task visual robot manipulation. Project page: https://GR1-Manipulation.github.io
Vision-Language Foundation Models as Effective Robot Imitators
Nov 06, 2023



Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step vision-language comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on language-conditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. We believe RoboFlamingo has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy.
Exploring Visual Pre-training for Robot Manipulation: Datasets, Models and Methods
Aug 07, 2023



Visual pre-training with large-scale real-world data has made great progress in recent years, showing great potential in robot learning with pixel observations. However, the recipes of visual pre-training for robot manipulation tasks are yet to be built. In this paper, we thoroughly investigate the effects of visual pre-training strategies on robot manipulation tasks from three fundamental perspectives: pre-training datasets, model architectures and training methods. Several significant experimental findings are provided that are beneficial for robot learning. Further, we propose a visual pre-training scheme for robot manipulation termed Vi-PRoM, which combines self-supervised learning and supervised learning. Concretely, the former employs contrastive learning to acquire underlying patterns from large-scale unlabeled data, while the latter aims learning visual semantics and temporal dynamics. Extensive experiments on robot manipulations in various simulation environments and the real robot demonstrate the superiority of the proposed scheme. Videos and more details can be found on \url{https://explore-pretrain-robot.github.io}.
MOMA-Force: Visual-Force Imitation for Real-World Mobile Manipulation
Aug 07, 2023



In this paper, we present a novel method for mobile manipulators to perform multiple contact-rich manipulation tasks. While learning-based methods have the potential to generate actions in an end-to-end manner, they often suffer from insufficient action accuracy and robustness against noise. On the other hand, classical control-based methods can enhance system robustness, but at the cost of extensive parameter tuning. To address these challenges, we present MOMA-Force, a visual-force imitation method that seamlessly combines representation learning for perception, imitation learning for complex motion generation, and admittance whole-body control for system robustness and controllability. MOMA-Force enables a mobile manipulator to learn multiple complex contact-rich tasks with high success rates and small contact forces. In a real household setting, our method outperforms baseline methods in terms of task success rates. Moreover, our method achieves smaller contact forces and smaller force variances compared to baseline methods without force imitation. Overall, we offer a promising approach for efficient and robust mobile manipulation in the real world. Videos and more details can be found on \url{https://visual-force-imitation.github.io}
Learning to Explore Informative Trajectories and Samples for Embodied Perception
Mar 20, 2023



We are witnessing significant progress on perception models, specifically those trained on large-scale internet images. However, efficiently generalizing these perception models to unseen embodied tasks is insufficiently studied, which will help various relevant applications (e.g., home robots). Unlike static perception methods trained on pre-collected images, the embodied agent can move around in the environment and obtain images of objects from any viewpoints. Therefore, efficiently learning the exploration policy and collection method to gather informative training samples is the key to this task. To do this, we first build a 3D semantic distribution map to train the exploration policy self-supervised by introducing the semantic distribution disagreement and the semantic distribution uncertainty rewards. Note that the map is generated from multi-view observations and can weaken the impact of misidentification from an unfamiliar viewpoint. Our agent is then encouraged to explore the objects with different semantic distributions across viewpoints, or uncertain semantic distributions. With the explored informative trajectories, we propose to select hard samples on trajectories based on the semantic distribution uncertainty to reduce unnecessary observations that can be correctly identified. Experiments show that the perception model fine-tuned with our method outperforms the baselines trained with other exploration policies. Further, we demonstrate the robustness of our method in real-robot experiments.
Towards Unifying Reference Expression Generation and Comprehension
Oct 24, 2022



Reference Expression Generation (REG) and Comprehension (REC) are two highly correlated tasks. Modeling REG and REC simultaneously for utilizing the relation between them is a promising way to improve both. However, the problem of distinct inputs, as well as building connections between them in a single model, brings challenges to the design and training of the joint model. To address the problems, we propose a unified model for REG and REC, named UniRef. It unifies these two tasks with the carefully-designed Image-Region-Text Fusion layer (IRTF), which fuses the image, region and text via the image cross-attention and region cross-attention. Additionally, IRTF could generate pseudo input regions for the REC task to enable a uniform way for sharing the identical representation space across the REC and REG. We further propose Vision-conditioned Masked Language Modeling (VMLM) and Text-Conditioned Region Prediction (TRP) to pre-train UniRef model on multi-granular corpora. The VMLM and TRP are directly related to REG and REC, respectively, but could help each other. We conduct extensive experiments on three benchmark datasets, RefCOCO, RefCOCO+ and RefCOCOg. Experimental results show that our model outperforms previous state-of-the-art methods on both REG and REC.
Locate then Segment: A Strong Pipeline for Referring Image Segmentation
Mar 30, 2021
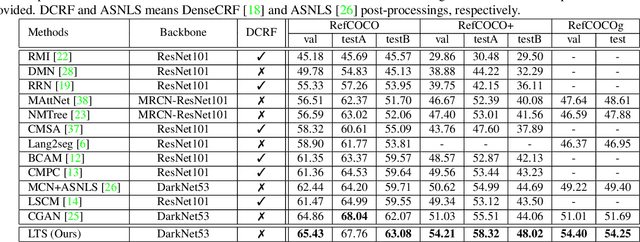
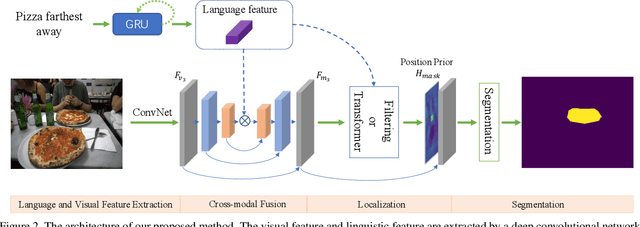
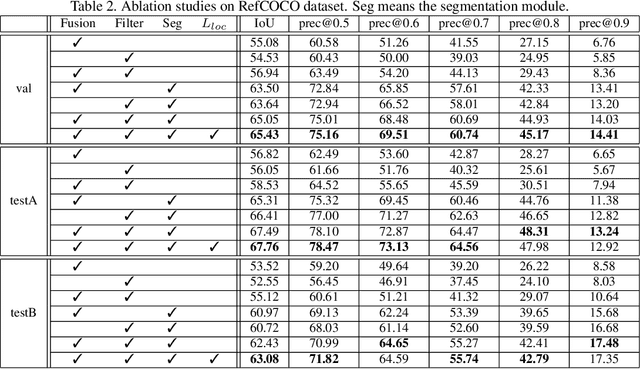
Referring image segmentation aims to segment the objects referred by a natural language expression. Previous methods usually focus on designing an implicit and recurrent feature interaction mechanism to fuse the visual-linguistic features to directly generate the final segmentation mask without explicitly modeling the localization information of the referent instances. To tackle these problems, we view this task from another perspective by decoupling it into a "Locate-Then-Segment" (LTS) scheme. Given a language expression, people generally first perform attention to the corresponding target image regions, then generate a fine segmentation mask about the object based on its context. The LTS first extracts and fuses both visual and textual features to get a cross-modal representation, then applies a cross-model interaction on the visual-textual features to locate the referred object with position prior, and finally generates the segmentation result with a light-weight segmentation network. Our LTS is simple but surprisingly effective. On three popular benchmark datasets, the LTS outperforms all the previous state-of-the-art methods by a large margin (e.g., +3.2% on RefCOCO+ and +3.4% on RefCOCOg). In addition, our model is more interpretable with explicitly locating the object, which is also proved by visualization experiments. We believe this framework is promising to serve as a strong baseline for referring image segmentation.