 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ERNIE-mmLayout: Multi-grained MultiModal Transformer for Document Understanding
Sep 18, 2022
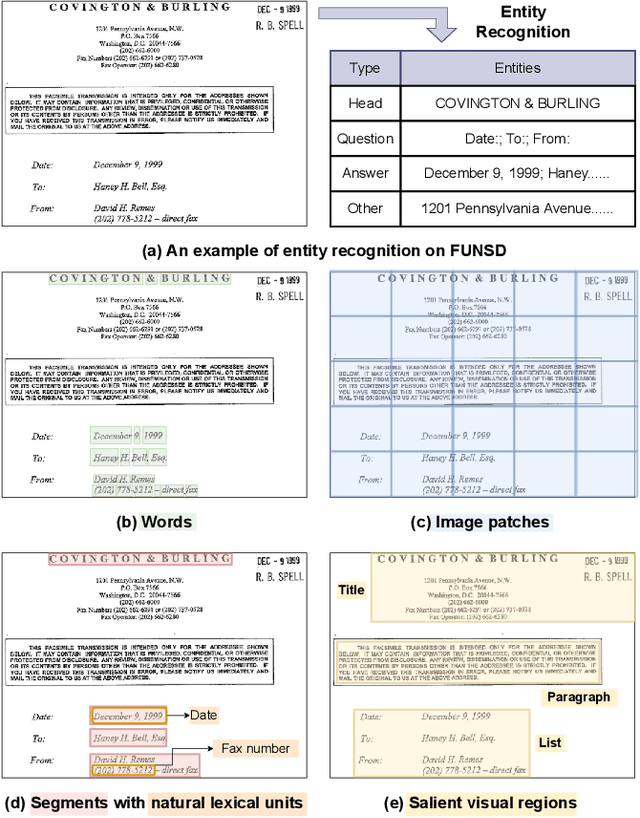
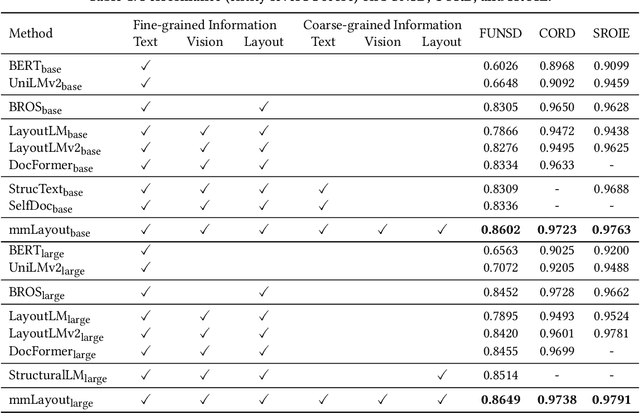
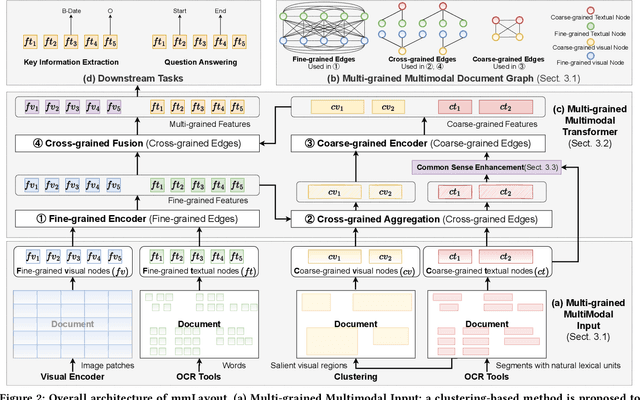
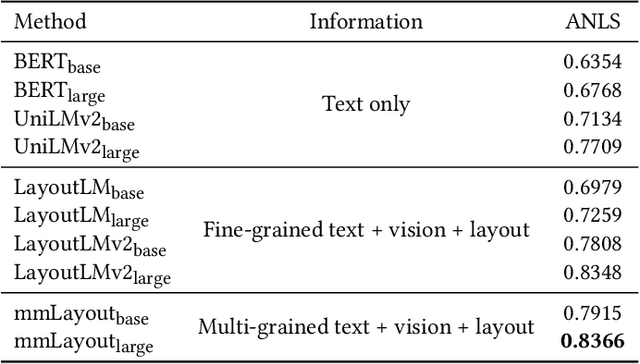
Recent efforts of multimodal Transformers have improved Visually Rich Document Understanding (VrDU) tasks via incorporating visual and textual information. However, existing approaches mainly focus on fine-grained elements such as words and document image patches, making it hard for them to learn from coarse-grained elements, including natural lexical units like phrases and salient visual regions like prominent image regions. In this paper, we attach more importance to coarse-grained elements containing high-density information and consistent semantics, which are valuable for document understanding. At first, a document graph is proposed to model complex relationships among multi-grained multimodal elements, in which salient visual regions are detected by a cluster-based method. Then, a multi-grained multimodal Transformer called mmLayout is proposed to incorporate coarse-grained information into existing pre-trained fine-grained multimodal Transformers based on the graph. In mmLayout, coarse-grained information is aggregated from fine-grained, and then, after further processing, is fused back into fine-grained for final prediction. Furthermore, common sense enhancement is introduced to exploit the semantic information of natural lexical units. Experimental results on four tasks, including information extraction and document question answering, show that our method can improve the performance of multimodal Transformers based on fine-grained elements and achieve better performance with fewer parameters. Qualitative analyses show that our method can capture consistent semantics in coarse-grained elements.
Label-only Model Inversion Attack: The Attack that Requires the Least Information
Mar 13, 2022
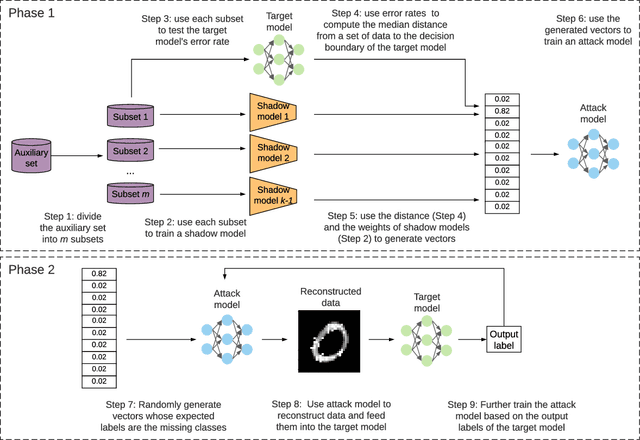
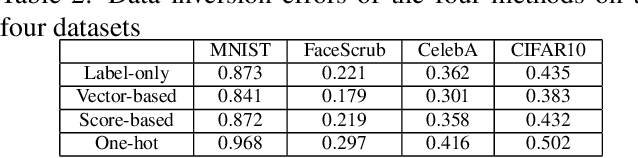
In a model inversion attack, an adversary attempts to reconstruct the data records, used to train a target model, using only the model's output. In launching a contemporary model inversion attack, the strategies discussed are generally based on either predicted confidence score vectors, i.e., black-box attacks, or the parameters of a target model, i.e., white-box attacks. However, in the real world, model owners usually only give out the predicted labels; the confidence score vectors and model parameters are hidden as a defense mechanism to prevent such attacks. Unfortunately, we have found a model inversion method that can reconstruct the input data records based only on the output labels. We believe this is the attack that requires the least information to succeed and, therefore, has the best applicability. The key idea is to exploit the error rate of the target model to compute the median distance from a set of data records to the decision boundary of the target model. The distance, then, is used to generate confidence score vectors which are adopted to train an attack model to reconstruct the data records. The experimental results show that highly recognizable data records can be reconstructed with far less information than existing methods.
EurNet: Efficient Multi-Range Relational Modeling of Spatial Multi-Relational Data
Nov 23, 2022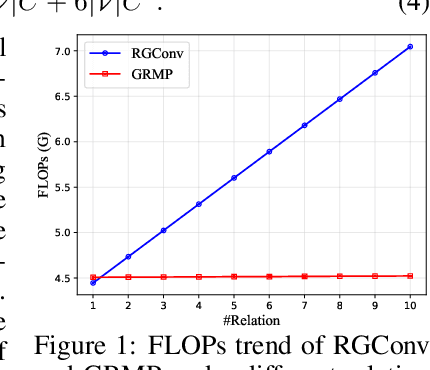
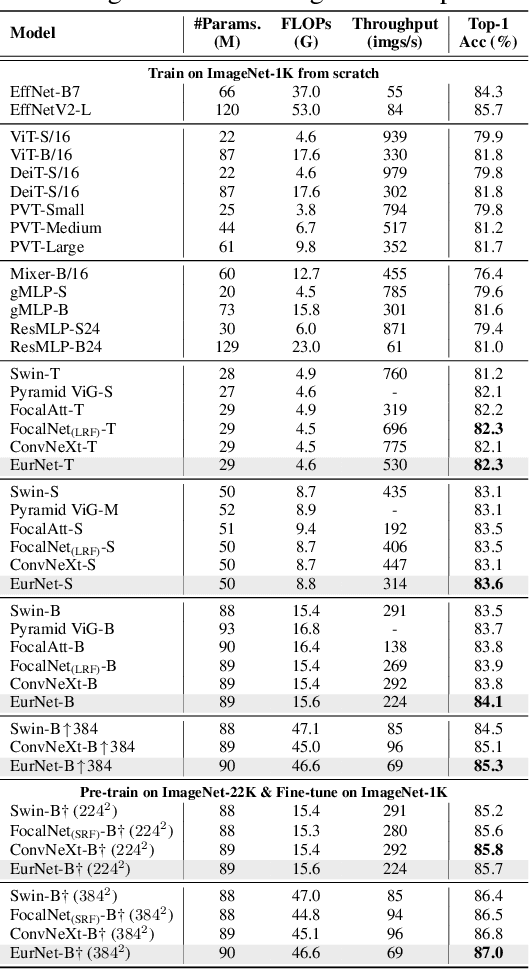
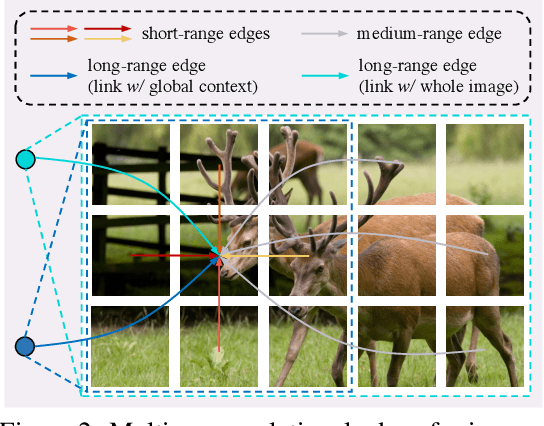
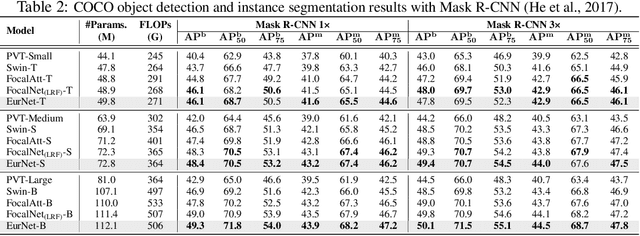
Modeling spatial relationship in the data remains critical across many different tasks, such as image classification, semantic segmentation and protein structure understanding. Previous works often use a unified solution like relative positional encoding. However, there exists different kinds of spatial relations, including short-range, medium-range and long-range relations, and modeling them separately can better capture the focus of different tasks on the multi-range relations (e.g., short-range relations can be important in instance segmentation, while long-range relations should be upweighted for semantic segmentation). In this work, we introduce the EurNet for Efficient multi-range relational modeling. EurNet constructs the multi-relational graph, where each type of edge corresponds to short-, medium- or long-range spatial interactions. In the constructed graph, EurNet adopts a novel modeling layer, called gated relational message passing (GRMP), to propagate multi-relational information across the data. GRMP captures multiple relations within the data with little extra computational cost. We study EurNets in two important domains for image and protein structure modeling. Extensive experiments on ImageNet classification, COCO object detection and ADE20K semantic segmentation verify the gains of EurNet over the previous SoTA FocalNet. On the EC and GO protein function prediction benchmarks, EurNet consistently surpasses the previous SoTA GearNet. Our results demonstrate the strength of EurNets on modeling spatial multi-relational data from various domains. The implementations of EurNet for image modeling are available at https://github.com/hirl-team/EurNet-Image . The implementations for other applied domains/tasks will be released soon.
Reason from Context with Self-supervised Learning
Nov 23, 2022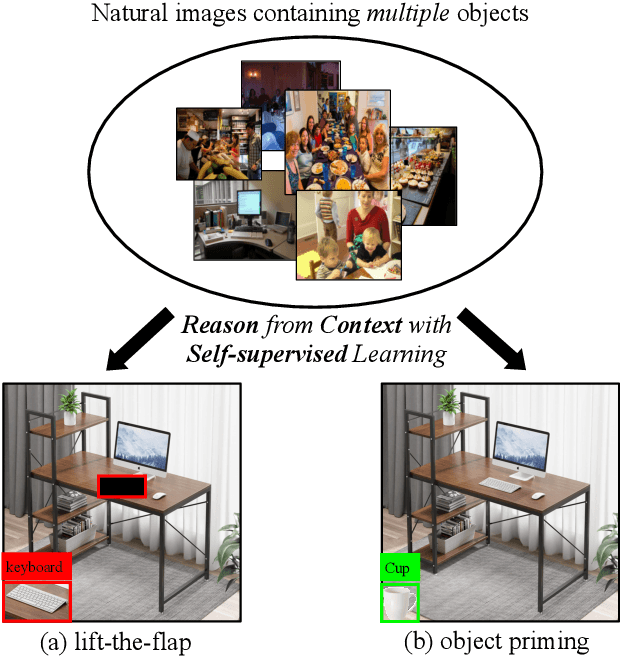
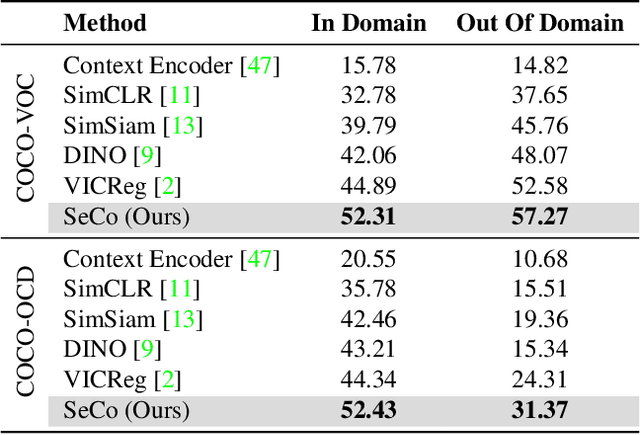
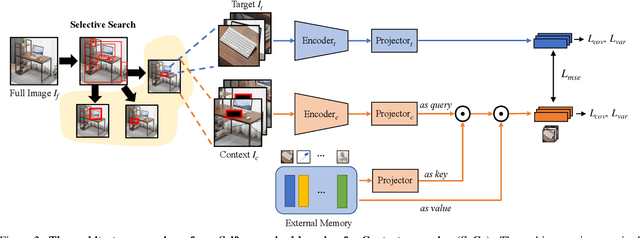

A tiny object in the sky cannot be an elephant. Context reasoning is critical in visual recognition, where current inputs need to be interpreted in the light of previous experience and knowledge. To date, research into contextual reasoning in visual recognition has largely proceeded with supervised learning methods. The question of whether contextual knowledge can be captured with self-supervised learning regimes remains under-explored. Here, we established a methodology for context-aware self-supervised learning. We proposed a novel Self-supervised Learning Method for Context Reasoning (SeCo), where the only inputs to SeCo are unlabeled images with multiple objects present in natural scenes. Similar to the distinction between fovea and periphery in human vision, SeCo processes self-proposed target object regions and their contexts separately, and then employs a learnable external memory for retrieving and updating context-relevant target information. To evaluate the contextual associations learned by the computational models, we introduced two evaluation protocols, lift-the-flap and object priming, addressing the problems of "what" and "where" in context reasoning. In both tasks, SeCo outperformed all state-of-the-art (SOTA) self-supervised learning methods by a significant margin. Our network analysis revealed that the external memory in SeCo learns to store prior contextual knowledge, facilitating target identity inference in lift-the-flap task. Moreover, we conducted psychophysics experiments and introduced a Human benchmark in Object Priming dataset (HOP). Our quantitative and qualitative results demonstrate that SeCo approximates human-level performance and exhibits human-like behavior. All our source code and data are publicly available here.
Knowledge-aware Neural Networks with Personalized Feature Referencing for Cold-start Recommendation
Sep 28, 2022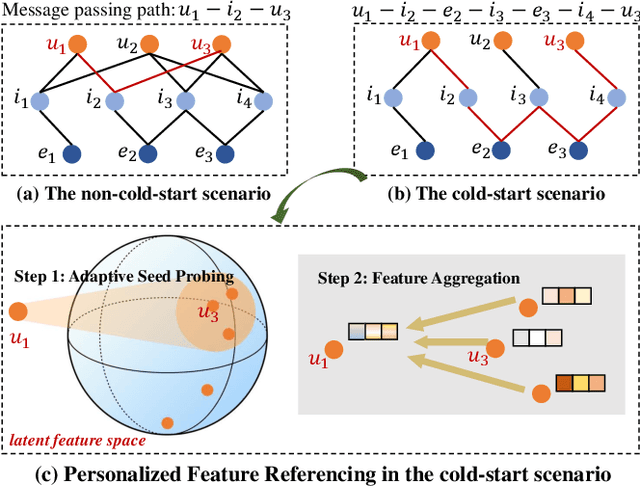
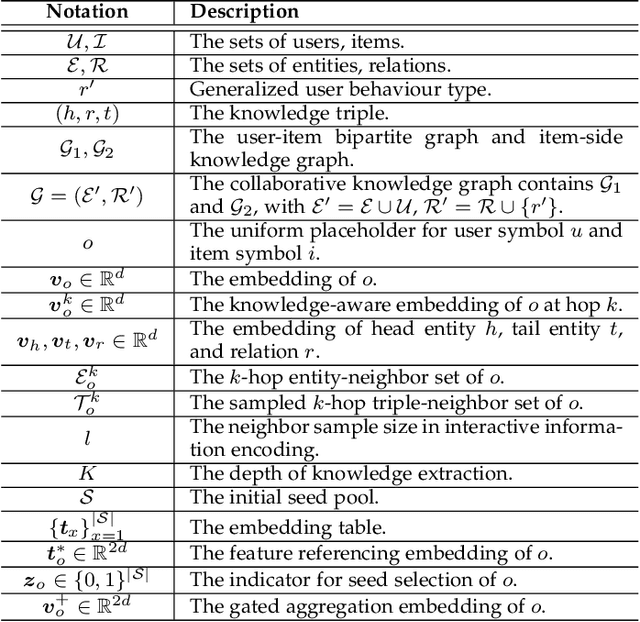
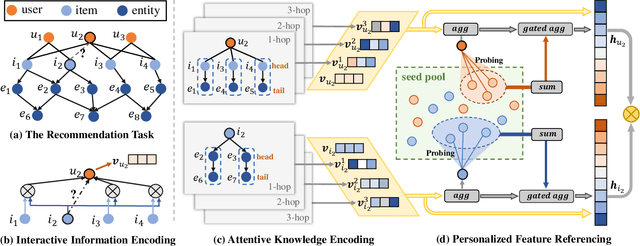
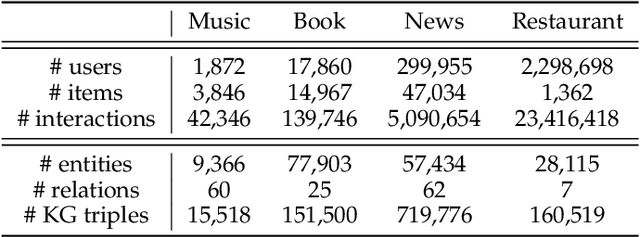
Incorporating knowledge graphs (KGs) as side information in recommendation has recently attracted considerable attention. Despite the success in general recommendation scenarios, prior methods may fall short of performance satisfaction for the cold-start problem in which users are associated with very limited interactive information. Since the conventional methods rely on exploring the interaction topology, they may however fail to capture sufficient information in cold-start scenarios. To mitigate the problem, we propose a novel Knowledge-aware Neural Networks with Personalized Feature Referencing Mechanism, namely KPER. Different from most prior methods which simply enrich the targets' semantics from KGs, e.g., product attributes, KPER utilizes the KGs as a "semantic bridge" to extract feature references for cold-start users or items. Specifically, given cold-start targets, KPER first probes semantically relevant but not necessarily structurally close users or items as adaptive seeds for referencing features. Then a Gated Information Aggregation module is introduced to learn the combinatorial latent features for cold-start users and items. Our extensive experiments over four real-world datasets show that, KPER consistently outperforms all competing methods in cold-start scenarios, whilst maintaining superiority in general scenarios without compromising overall performance, e.g., by achieving 0.81%-16.08% and 1.01%-14.49% performance improvement across all datasets in Top-10 recommendation.
Step out of KG: Knowledge Graph Completion via Knowledgeable Retrieval and Reading Comprehension
Oct 12, 2022
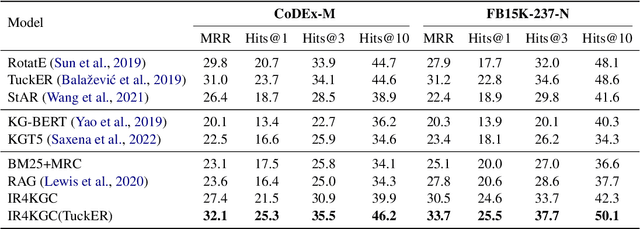
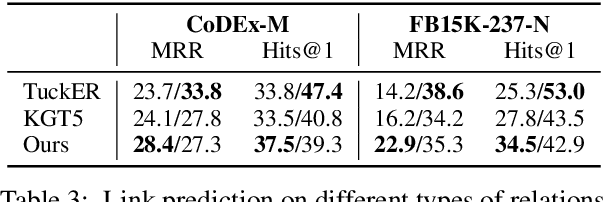
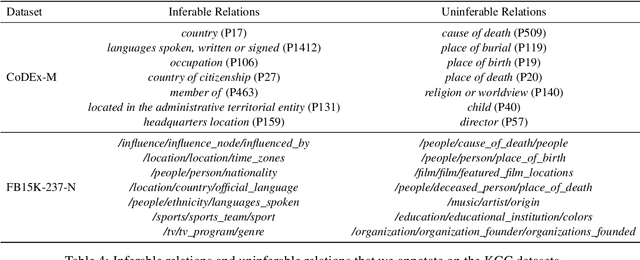
Knowledge graphs, as the cornerstone of many AI applications, usually face serious incompleteness problems. In recent years, there have been many efforts to study automatic knowledge graph completion (KGC), most of which use existing knowledge to infer new knowledge. However, in our experiments, we find that not all relations can be obtained by inference, which constrains the performance of existing models. To alleviate this problem, we propose a new model based on information retrieval and reading comprehension, namely IR4KGC. Specifically, we pre-train a knowledge-based information retrieval module that can retrieve documents related to the triples to be completed. Then, the retrieved documents are handed over to the reading comprehension module to generate the predicted answers. In experiments, we find that our model can well solve relations that cannot be inferred from existing knowledge, and achieve good results on KGC datasets.
Certified Data Removal in Sum-Product Networks
Oct 04, 2022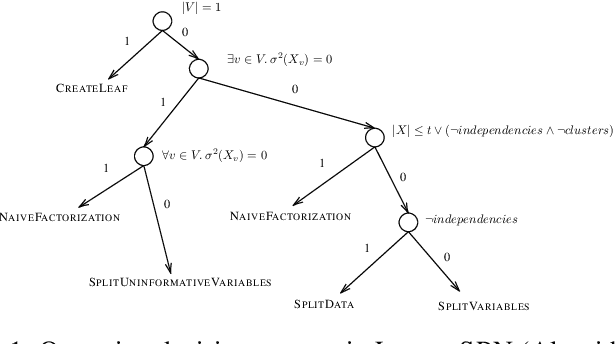
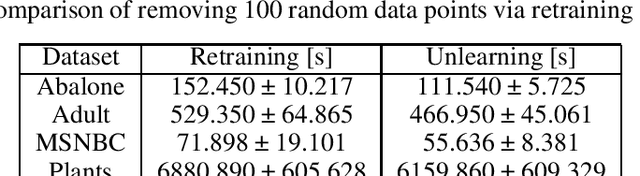
Data protection regulations like the GDPR or the California Consumer Privacy Act give users more control over the data that is collected about them. Deleting the collected data is often insufficient to guarantee data privacy since it is often used to train machine learning models, which can expose information about the training data. Thus, a guarantee that a trained model does not expose information about its training data is additionally needed. In this paper, we present UnlearnSPN -- an algorithm that removes the influence of single data points from a trained sum-product network and thereby allows fulfilling data privacy requirements on demand.
Hard Exudate Segmentation Supplemented by Super-Resolution with Multi-scale Attention Fusion Module
Nov 17, 2022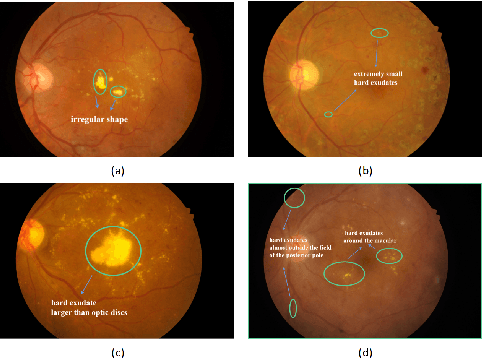
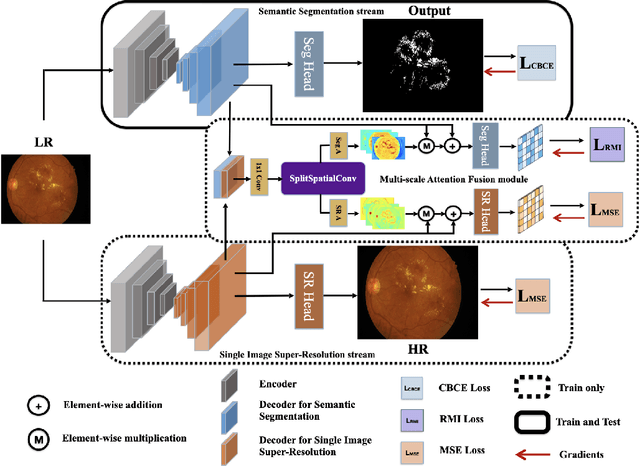
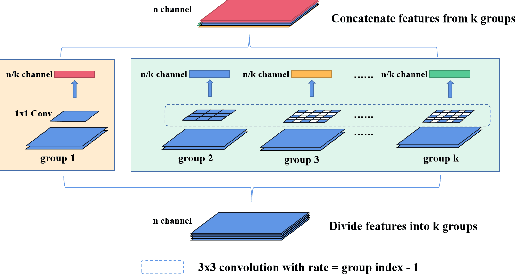
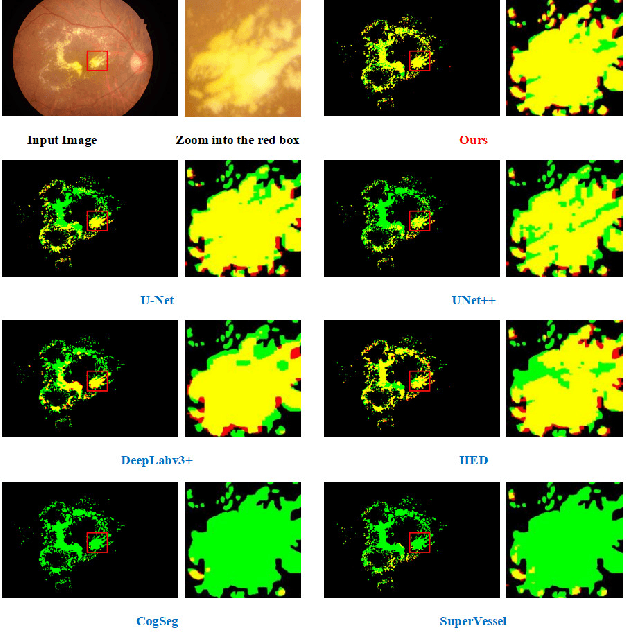
Hard exudates (HE) is the most specific biomarker for retina edema. Precise HE segmentation is vital for disease diagnosis and treatment, but automatic segmentation is challenged by its large variation of characteristics including size, shape and position, which makes it difficult to detect tiny lesions and lesion boundaries. Considering the complementary features between segmentation and super-resolution tasks, this paper proposes a novel hard exudates segmentation method named SS-MAF with an auxiliary super-resolution task, which brings in helpful detailed features for tiny lesion and boundaries detection. Specifically, we propose a fusion module named Multi-scale Attention Fusion (MAF) module for our dual-stream framework to effectively integrate features of the two tasks. MAF first adopts split spatial convolutional (SSC) layer for multi-scale features extraction and then utilize attention mechanism for features fusion of the two tasks. Considering pixel dependency, we introduce region mutual information (RMI) loss to optimize MAF module for tiny lesions and boundary detection. We evaluate our method on two public lesion datasets, IDRiD and E-Ophtha. Our method shows competitive performance with low-resolution inputs, both quantitatively and qualitatively. On E-Ophtha dataset, the method can achieve $\geq3\%$ higher dice and recall compared with the state-of-the-art methods.
Text-Aware Dual Routing Network for Visual Question Answering
Nov 17, 2022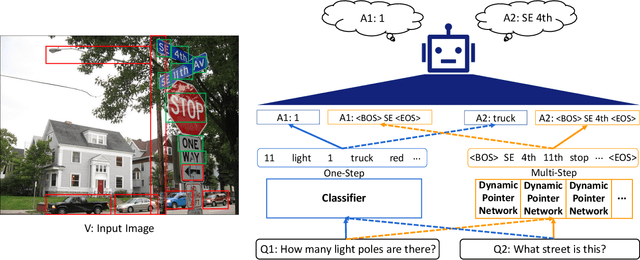
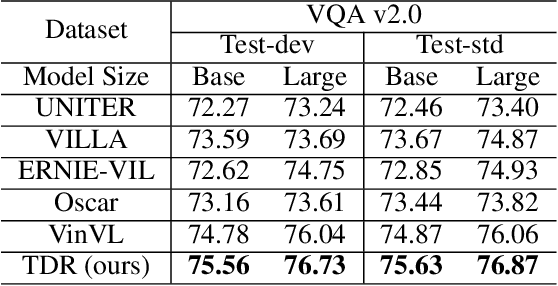
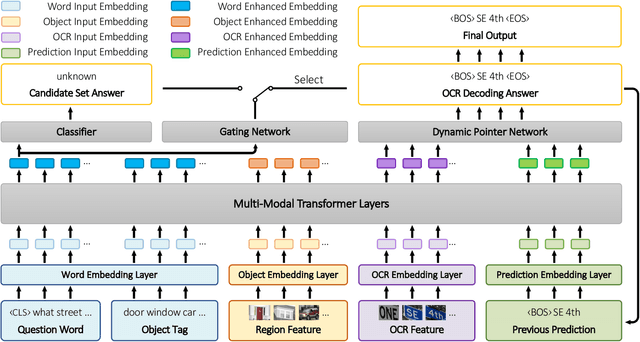

Visual question answering (VQA) is a challenging task to provide an accurate natural language answer given an image and a natural language question about the image. It involves multi-modal learning, i.e., computer vision (CV) and natural language processing (NLP), as well as flexible answer prediction for free-form and open-ended answers. Existing approaches often fail in cases that require reading and understanding text in images to answer questions. In practice, they cannot effectively handle the answer sequence derived from text tokens because the visual features are not text-oriented. To address the above issues, we propose a Text-Aware Dual Routing Network (TDR) which simultaneously handles the VQA cases with and without understanding text information in the input images. Specifically, we build a two-branch answer prediction network that contains a specific branch for each case and further develop a dual routing scheme to dynamically determine which branch should be chosen. In the branch that involves text understanding, we incorporate the Optical Character Recognition (OCR) features into the model to help understand the text in the images. Extensive experiments on the VQA v2.0 dataset demonstrate that our proposed TDR outperforms existing methods, especially on the ''number'' related VQA questions.
UMFuse: Unified Multi View Fusion for Human Editing applications
Nov 17, 2022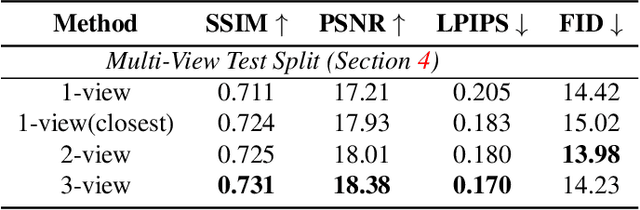
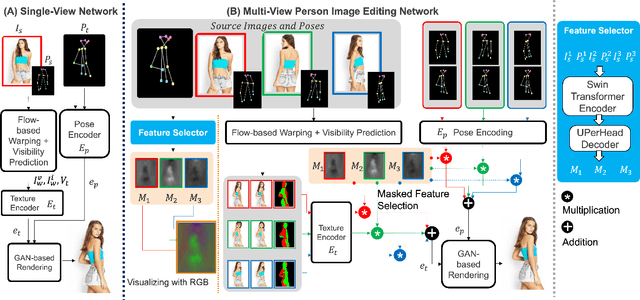
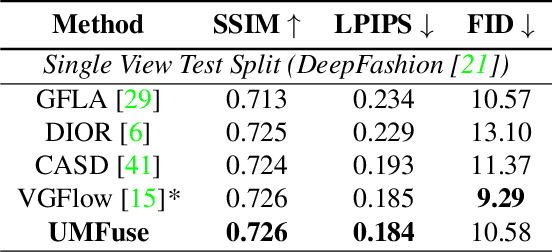
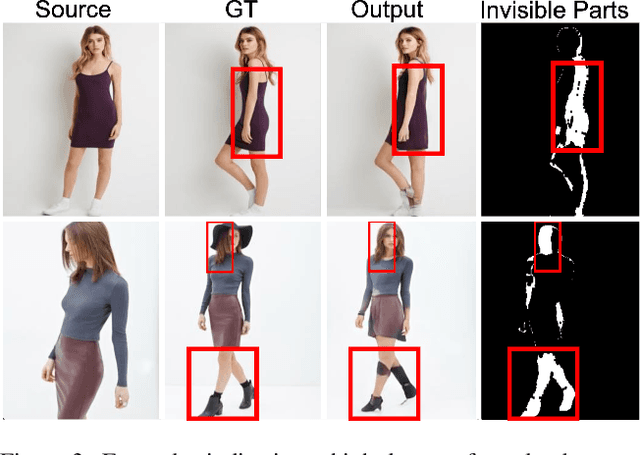
The vision community has explored numerous pose guided human editing methods due to their extensive practical applications. Most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. However, the problem is ill-defined in cases when the target pose is significantly different from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse the knowledge from multiple viewpoints, we design a selector network that takes the pose keypoints and texture from images and generates an interpretable per-pixel selection map. After that, the encodings from a separate network (trained on a single image human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on 2 newly proposed tasks - Multi-view human reposing, and Mix-and-match human image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a much better alternative.