 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDownscaled Representation Matters: Improving Image Rescaling with Collaborative Downscaled Images
Nov 19, 2022



Deep networks have achieved great success in image rescaling (IR) task that seeks to learn the optimal downscaled representations, i.e., low-resolution (LR) images, to reconstruct the original high-resolution (HR) images. Compared with super-resolution methods that consider a fixed downscaling scheme, e.g., bicubic, IR often achieves significantly better reconstruction performance thanks to the learned downscaled representations. This highlights the importance of a good downscaled representation in image reconstruction tasks. Existing IR methods mainly learn the downscaled representation by jointly optimizing the downscaling and upscaling models. Unlike them, we seek to improve the downscaled representation through a different and more direct way: optimizing the downscaled image itself instead of the down-/upscaling models. Specifically, we propose a collaborative downscaling scheme that directly generates the collaborative LR examples by descending the gradient w.r.t. the reconstruction loss on them to benefit the IR process. Furthermore, since LR images are downscaled from the corresponding HR images, one can also improve the downscaled representation if we have a better representation in the HR domain. Inspired by this, we propose a Hierarchical Collaborative Downscaling (HCD) method that performs gradient descent in both HR and LR domains to improve the downscaled representations. Extensive experiments show that our HCD significantly improves the reconstruction performance both quantitatively and qualitatively. Moreover, we also highlight the flexibility of our HCD since it can generalize well across diverse IR models.
Text-Aware Dual Routing Network for Visual Question Answering
Nov 17, 2022



Visual question answering (VQA) is a challenging task to provide an accurate natural language answer given an image and a natural language question about the image. It involves multi-modal learning, i.e., computer vision (CV) and natural language processing (NLP), as well as flexible answer prediction for free-form and open-ended answers. Existing approaches often fail in cases that require reading and understanding text in images to answer questions. In practice, they cannot effectively handle the answer sequence derived from text tokens because the visual features are not text-oriented. To address the above issues, we propose a Text-Aware Dual Routing Network (TDR) which simultaneously handles the VQA cases with and without understanding text information in the input images. Specifically, we build a two-branch answer prediction network that contains a specific branch for each case and further develop a dual routing scheme to dynamically determine which branch should be chosen. In the branch that involves text understanding, we incorporate the Optical Character Recognition (OCR) features into the model to help understand the text in the images. Extensive experiments on the VQA v2.0 dataset demonstrate that our proposed TDR outperforms existing methods, especially on the ''number'' related VQA questions.
Priority prediction of Asian Hornet sighting report using machine learning methods
Jun 28, 2021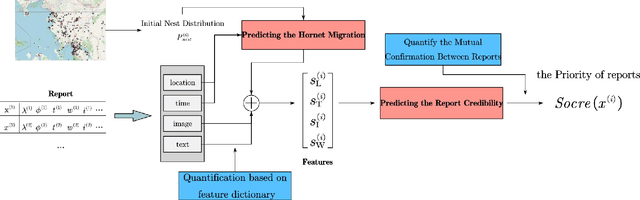
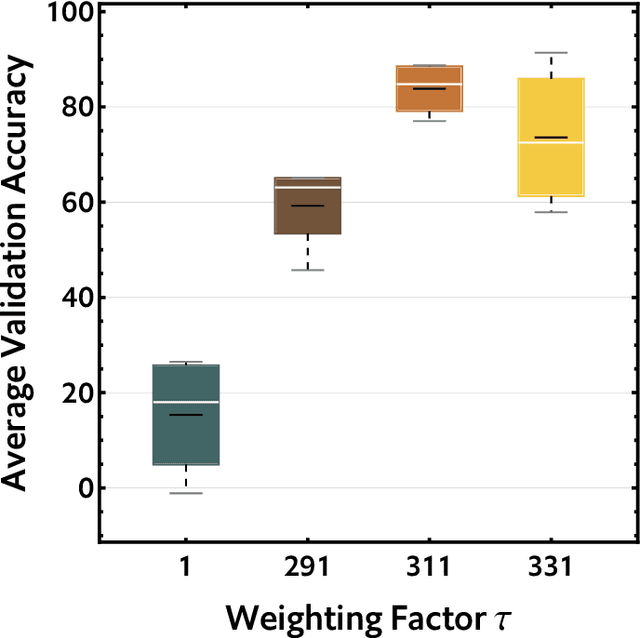
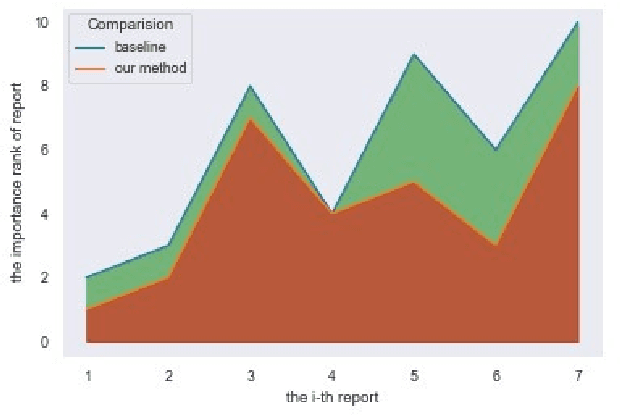
As infamous invaders to the North American ecosystem, the Asian giant hornet (Vespa mandarinia) is devastating not only to native bee colonies, but also to local apiculture. One of the most effective way to combat the harmful species is to locate and destroy their nests. By mobilizing the public to actively report possible sightings of the Asian giant hornet, the governmentcould timely send inspectors to confirm and possibly destroy the nests. However, such confirmation requires lab expertise, where manually checking the reports one by one is extremely consuming of human resources. Further given the limited knowledge of the public about the Asian giant hornet and the randomness of report submission, only few of the numerous reports proved positive, i.e. existing nests. How to classify or prioritize the reports efficiently and automatically, so as to determine the dispatch of personnel, is of great significance to the control of the Asian giant hornet. In this paper, we propose a method to predict the priority of sighting reports based on machine learning. We model the problem of optimal prioritization of sighting reports as a problem of classification and prediction. We extracted a variety of rich features in the report: location, time, image(s), and textual description. Based on these characteristics, we propose a classification model based on logistic regression to predict the credibility of a certain report. Furthermore, our model quantifies the impact between reports to get the priority ranking of the reports. Extensive experiments on the public dataset from the WSDA (the Washington State Department of Agriculture) have proved the effectiveness of our method.