 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multimodal LLMs on Code Generation for Complex Interactive Webpages
May 29, 2026Recent advancements in multimodal large language models (MLLMs) have achieved remarkable progress in multimodal reasoning and code generation, catalyzing a new paradigm for front-end development. In particular, these models can directly transform visual designs into executable code, significantly improving the efficiency and adaptability of web development. Modern web applications are dynamic and interactive, featuring frequent user-page interactions. However, existing benchmarks largely evaluate the code generation of static webpages, ignoring the complex interactive behaviors in real-world applications. Besides, their evaluation criteria remain confined to visual fidelity and code structure, overlooking the interaction consistency between the generated and the reference webpages. To address these limitations, we introduce WebIGBench, the first benchmark designed to evaluate code generation for interactive webpages with complex interactions. By combining manually designed interaction paths with UI automation, we collected 103 complex webpages from real-world websites. This benchmark covers 5 popular interactive action types (e.g., click, input) involving 871 distinct interactive actions. Moreover, we propose a novel evaluation pipeline to address the gap in automated assessment of interactive actions. Extensive experiments on several representative MLLMs reveal the performance boundaries of current models in interactive webpage code generation using WebIGBench. The proposed benchmark is available at https://github.com/anoa12159-hue/WebIGBench_eval.
Schedule-and-Calibrate: Utility-Guided Multi-Task Reinforcement Learning for Code LLMs
May 07, 2026Reinforcement learning (RL) with verifiable rewards has proven effective at post-training LLMs for coding, yet deploying separate task-specific specialists incurs costs that scale with the number of tasks, motivating a unified multi-task RL (MTRL) approach. However, existing MTRL methods treat all coding tasks uniformly, relying on fixed data curricula under a shared optimization strategy, ultimately limiting the effectiveness of multi-task training. To address these limitations, we propose ASTOR, a multi-tASk code reinforcement learning framework via uTility-driven coORdination. Centered on task utility, a signal capturing each task learning potential and cross-task synergy, ASTOR comprises two coupled modules: 1) Hierarchical Utility-Routed Data Scheduling module hierarchically allocates training budget and prioritizes informative prompts, steering training toward the most valuable data and 2) Adaptive Utility-Calibrated Policy Optimization module dynamically scales per-task KL regularization, matching update constraints to each tasks current training state. Experiments on two widely-used LLMs across four representative coding tasks demonstrate that ASTOR consistently improves a single model across all tasks, outperforming the best task-specific specialist by 9.0%-9.5% and surpassing the strongest MTRL baseline by 7.5%-12.8%.
Evaluating LLM-Based 0-to-1 Software Generation in End-to-End CLI Tool Scenarios
Apr 08, 2026Large Language Models (LLMs) are driving a shift towards intent-driven development, where agents build complete software from scratch. However, existing benchmarks fail to assess this 0-to-1 generation capability due to two limitations: reliance on predefined scaffolds that ignore repository structure planning, and rigid white-box unit testing that lacks end-to-end behavioral validation. To bridge this gap, we introduce CLI-Tool-Bench, a structure-agnostic benchmark for evaluating the ground-up generation of Command-Line Interface (CLI) tools. It features 100 diverse real-world repositories evaluated via a black-box differential testing framework. Agent-generated software is executed in sandboxes, comparing system side effects and terminal outputs against human-written oracles using multi-tiered equivalence metrics. Evaluating seven state-of-the-art LLMs, we reveal that top models achieve under 43% success, highlighting the ongoing challenge of 0-to-1 generation. Furthermore, higher token consumption does not guarantee better performance, and agents tend to generate monolithic code.
Evaluating Repository-level Software Documentation via Question Answering and Feature-Driven Development
Apr 08, 2026Software documentation is crucial for repository comprehension. While Large Language Models (LLMs) advance documentation generation from code snippets to entire repositories, existing benchmarks have two key limitations: (1) they lack a holistic, repository-level assessment, and (2) they rely on unreliable evaluation strategies, such as LLM-as-a-judge, which suffers from vague criteria and limited repository-level knowledge. To address these issues, we introduce SWD-Bench, a novel benchmark for evaluating repository-level software documentation. Inspired by documentation-driven development, our strategy evaluates documentation quality by assessing an LLM's ability to understand and implement functionalities using the documentation, rather than by directly scoring it. This is measured through function-driven Question Answering (QA) tasks. SWD-Bench comprises three interconnected QA tasks: (1) Functionality Detection, to determine if a functionality is described; (2) Functionality Localization, to evaluate the accuracy of locating related files; and (3) Functionality Completion, to measure the comprehensiveness of implementation details. We construct the benchmark, containing 4,170 entries, by mining high-quality Pull Requests and enriching them with repository-level context. Experiments reveal limitations in current documentation generation methods and show that source code provides complementary value. Notably, documentation from the best-performing method improves the issue-solving rate of SWE-Agent by 20.00%, which demonstrates the practical value of high-quality documentation in supporting documentation-driven development.
LLM-Based Test Case Generation in DBMS through Monte Carlo Tree Search
Mar 23, 2026Database Management Systems (DBMSs) are fundamental infrastructure for modern data-driven applications, where thorough testing with high-quality SQL test cases is essential for ensuring system reliability. Traditional approaches such as fuzzing can be effective for specific DBMSs, but adapting them to different proprietary dialects requires substantial manual effort. Large Language Models (LLMs) present promising opportunities for automated SQL test generation, but face critical challenges in industrial environments. First, lightweight models are widely used in organizations due to security and privacy constraints, but they struggle to generate syntactically valid queries for proprietary SQL dialects. Second, LLM-generated queries are often semantically similar and exercise only shallow execution paths, thereby quickly reaching a coverage plateau. To address these challenges, we propose MIST, an LLM-based test case generatIon framework for DBMS through Monte Carlo Tree search. MIST consists of two stages: Feature-Guided Error-Driven Test Case Synthetization, which constructs a hierarchical feature tree and uses error feedback to guide LLM generation, aiming to produce syntactically valid and semantically diverse queries for different DBMS dialects, and Monte Carlo Tree Search-Based Test Case Mutation, which jointly optimizes seed query selection and mutation rule application guided by coverage feedback, aiming at boosting code coverage by exploring deeper execution paths. Experiments on three widely-used DBMSs with four lightweight LLMs show that MIST achieves average improvements of 43.3% in line coverage, 32.3% in function coverage, and 46.4% in branch coverage compared to the baseline approach with the highest line coverage of 69.3% in the Optimizer module.
SWE-Fuse: Empowering Software Agents via Issue-free Trajectory Learning and Entropy-aware RLVR Training
Mar 09, 2026Large language models (LLMs) have transformed the software engineering landscape. Recently, numerous LLM-based agents have been developed to address real-world software issue fixing tasks. Despite their state-of-the-art performance, Despite achieving state-of-the-art performance, these agents face a significant challenge: \textbf{Insufficient high-quality issue descriptions.} Real-world datasets often exhibit misalignments between issue descriptions and their corresponding solutions, introducing noise and ambiguity that mislead automated agents and limit their problem-solving effectiveness. We propose \textbf{\textit{SWE-Fuse}}, an issue-description-aware training framework that fuses issue-description-guided and issue-free samples for training SWE agents. It consists of two key modules: (1) An issue-free-driven trajectory learning module for mitigating potentially misleading issue descriptions while enabling the model to learn step-by-step debugging processes; and (2) An entropy-aware RLVR training module, which adaptively adjusts training dynamics through entropy-driven clipping. It applies relaxed clipping under high entropy to encourage exploration, and stricter clipping under low entropy to ensure training stability. We evaluate SWE-Fuse on the widely studied SWE-bench Verified benchmark shows to demonstrate its effectiveness in solving real-world software problems. Specifically, SWE-Fuse outperforms the best 8B and 32B baselines by 43.0\% and 60.2\% in solve rate, respectively. Furthermore, integrating SWE-Fuse with test-time scaling (TTS) enables further performance improvements, achieving solve rates of 49.8\% and 65.2\% under TTS@8 for the 8B and 32B models, respectively.
AXIOM: Benchmarking LLM-as-a-Judge for Code via Rule-Based Perturbation and Multisource Quality Calibration
Dec 23, 2025Large language models (LLMs) have been increasingly deployed in real-world software engineering, fostering the development of code evaluation metrics to study the quality of LLM-generated code. Conventional rule-based metrics merely score programs based on their surface-level similarities with reference programs instead of analyzing functionality and code quality in depth. To address this limitation, researchers have developed LLM-as-a-judge metrics, prompting LLMs to evaluate and score code, and curated various code evaluation benchmarks to validate their effectiveness. However, these benchmarks suffer from critical limitations, hindering reliable assessments of evaluation capability: Some feature coarse-grained binary labels, which reduce rich code behavior to a single bit of information, obscuring subtle errors. Others propose fine-grained but subjective, vaguely-defined evaluation criteria, introducing unreliability in manually-annotated scores, which is the ground-truth they rely on. Furthermore, they often use uncontrolled data synthesis methods, leading to unbalanced score distributions that poorly represent real-world code generation scenarios. To curate a diverse benchmark with programs of well-balanced distributions across various quality levels and streamline the manual annotation procedure, we propose AXIOM, a novel perturbation-based framework for synthesizing code evaluation benchmarks at scale. It reframes program scores as the refinement effort needed for deployment, consisting of two stages: (1) Rule-guided perturbation, which prompts LLMs to apply sequences of predefined perturbation rules to existing high-quality programs to modify their functionality and code quality, enabling us to precisely control each program's target score to achieve balanced score distributions. (2) Multisource quality calibration, which first selects a subset of...
Benchmarking LLMs for Fine-Grained Code Review with Enriched Context in Practice
Nov 10, 2025



Code review is a cornerstone of software quality assurance, and recent advances in Large Language Models (LLMs) have shown promise in automating this process. However, existing benchmarks for LLM-based code review face three major limitations. (1) Lack of semantic context: most benchmarks provide only code diffs without textual information such as issue descriptions, which are crucial for understanding developer intent. (2) Data quality issues: without rigorous validation, many samples are noisy-e.g., reviews on outdated or irrelevant code-reducing evaluation reliability. (3) Coarse granularity: most benchmarks operate at the file or commit level, overlooking the fine-grained, line-level reasoning essential for precise review. We introduce ContextCRBench, a high-quality, context-rich benchmark for fine-grained LLM evaluation in code review. Our construction pipeline comprises: (1) Raw Data Crawling, collecting 153.7K issues and pull requests from top-tier repositories; (2) Comprehensive Context Extraction, linking issue-PR pairs for textual context and extracting the full surrounding function or class for code context; and (3) Multi-stage Data Filtering, combining rule-based and LLM-based validation to remove outdated, malformed, or low-value samples, resulting in 67,910 context-enriched entries. ContextCRBench supports three evaluation scenarios aligned with the review workflow: (1) hunk-level quality assessment, (2) line-level defect localization, and (3) line-level comment generation. Evaluating eight leading LLMs (four closed-source and four open-source) reveals that textual context yields greater performance gains than code context alone, while current LLMs remain far from human-level review ability. Deployed at ByteDance, ContextCRBench drives a self-evolving code review system, improving performance by 61.98% and demonstrating its robustness and industrial utility.
Boosting Vulnerability Detection of LLMs via Curriculum Preference Optimization with Synthetic Reasoning Data
Jun 09, 2025



Large language models (LLMs) demonstrate considerable proficiency in numerous coding-related tasks; however, their capabilities in detecting software vulnerabilities remain limited. This limitation primarily stems from two factors: (1) the absence of reasoning data related to vulnerabilities, which hinders the models' ability to capture underlying vulnerability patterns; and (2) their focus on learning semantic representations rather than the reason behind them, thus failing to recognize semantically similar vulnerability samples. Furthermore, the development of LLMs specialized in vulnerability detection is challenging, particularly in environments characterized by the scarcity of high-quality datasets. In this paper, we propose a novel framework ReVD that excels at mining vulnerability patterns through reasoning data synthesizing and vulnerability-specific preference optimization. Specifically, we construct forward and backward reasoning processes for vulnerability and corresponding fixed code, ensuring the synthesis of high-quality reasoning data. Moreover, we design the triplet supervised fine-tuning followed by curriculum online preference optimization for enabling ReVD to better understand vulnerability patterns. The extensive experiments conducted on PrimeVul and SVEN datasets demonstrate that ReVD sets new state-of-the-art for LLM-based software vulnerability detection, e.g., 12.24\%-22.77\% improvement in the accuracy. The source code and data are available at https://github.com/Xin-Cheng-Wen/PO4Vul.
Exploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities
May 28, 2025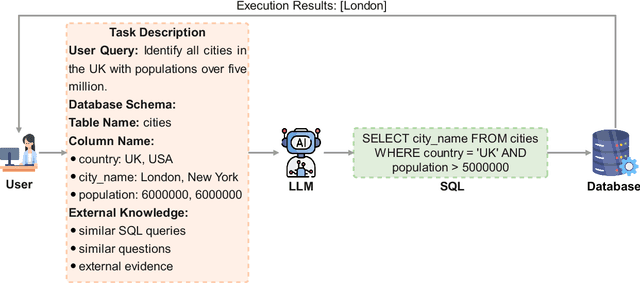
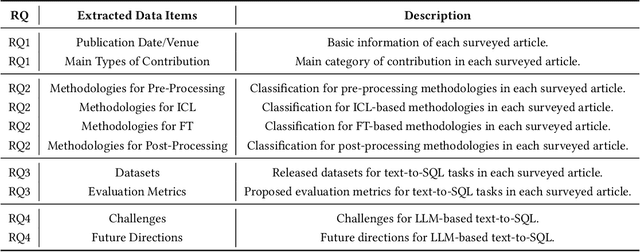
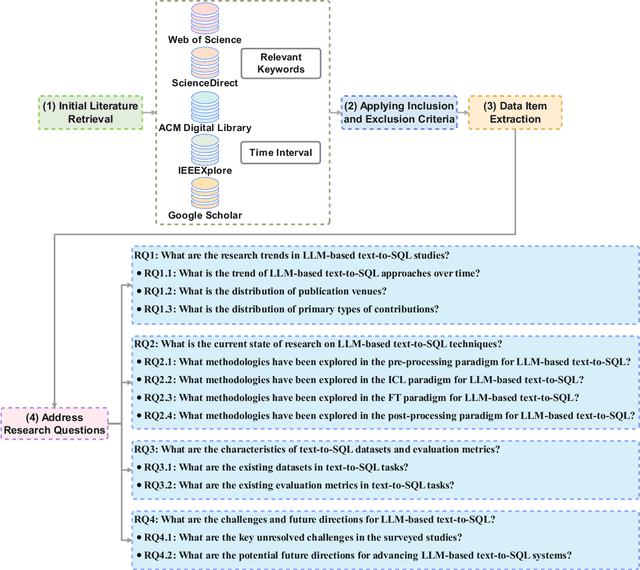
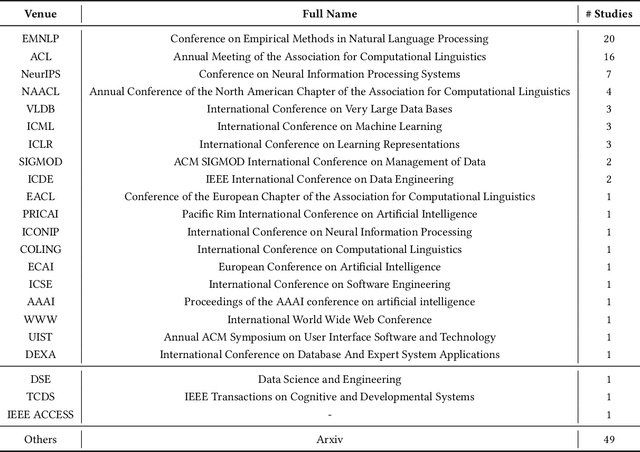
Converting natural language (NL) questions into SQL queries, referred to as Text-to-SQL, has emerged as a pivotal technology for facilitating access to relational databases, especially for users without SQL knowledge. Recent progress in large language models (LLMs) has markedly propelled the field of natural language processing (NLP), opening new avenues to improve text-to-SQL systems. This study presents a systematic review of LLM-based text-to-SQL, focusing on four key aspects: (1) an analysis of the research trends in LLM-based text-to-SQL; (2) an in-depth analysis of existing LLM-based text-to-SQL techniques from diverse perspectives; (3) summarization of existing text-to-SQL datasets and evaluation metrics; and (4) discussion on potential obstacles and avenues for future exploration in this domain. This survey seeks to furnish researchers with an in-depth understanding of LLM-based text-to-SQL, sparking new innovations and advancements in this field.