 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Context Modeling in 3D Human Pose Estimation: A Unified Perspective
Mar 30, 2021
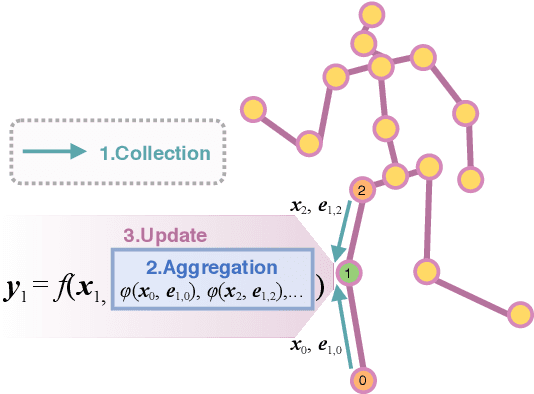
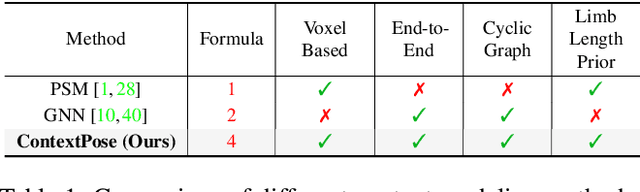
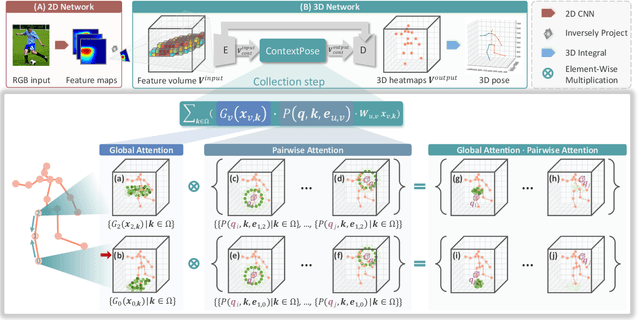
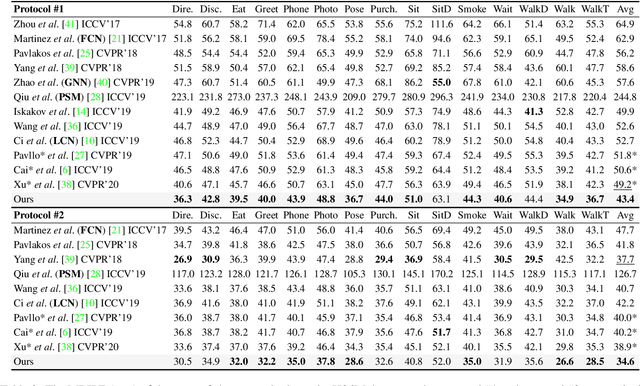
Estimating 3D human pose from a single image suffers from severe ambiguity since multiple 3D joint configurations may have the same 2D projection. The state-of-the-art methods often rely on context modeling methods such as pictorial structure model (PSM) or graph neural network (GNN) to reduce ambiguity. However, there is no study that rigorously compares them side by side. So we first present a general formula for context modeling in which both PSM and GNN are its special cases. By comparing the two methods, we found that the end-to-end training scheme in GNN and the limb length constraints in PSM are two complementary factors to improve results. To combine their advantages, we propose ContextPose based on attention mechanism that allows enforcing soft limb length constraints in a deep network. The approach effectively reduces the chance of getting absurd 3D pose estimates with incorrect limb lengths and achieves state-of-the-art results on two benchmark datasets. More importantly, the introduction of limb length constraints into deep networks enables the approach to achieve much better generalization performance.
Weakly-Supervised Multi-Face 3D Reconstruction
Jan 06, 2021


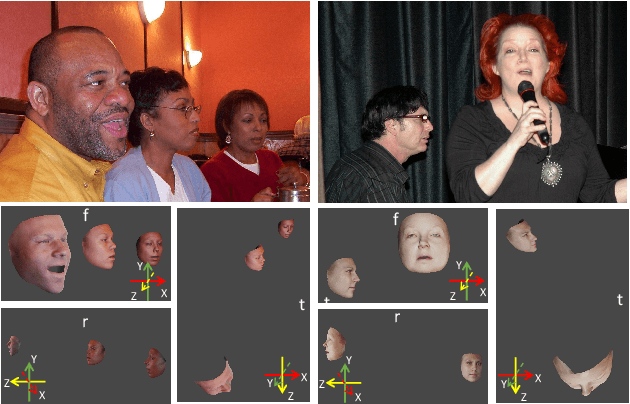
3D face reconstruction plays a very important role in many real-world multimedia applications, including digital entertainment, social media, affection analysis, and person identification. The de-facto pipeline for estimating the parametric face model from an image requires to firstly detect the facial regions with landmarks, and then crop each face to feed the deep learning-based regressor. Comparing to the conventional methods performing forward inference for each detected instance independently, we suggest an effective end-to-end framework for multi-face 3D reconstruction, which is able to predict the model parameters of multiple instances simultaneously using single network inference. Our proposed approach not only greatly reduces the computational redundancy in feature extraction but also makes the deployment procedure much easier using the single network model. More importantly, we employ the same global camera model for the reconstructed faces in each image, which makes it possible to recover the relative head positions and orientations in the 3D scene. We have conducted extensive experiments to evaluate our proposed approach on the sparse and dense face alignment tasks. The experimental results indicate that our proposed approach is very promising on face alignment tasks without fully-supervision and pre-processing like detection and crop. Our implementation is publicly available at \url{https://github.com/kalyo-zjl/WM3DR}.
Instance-Aware Graph Convolutional Network for Multi-Label Classification
Aug 19, 2020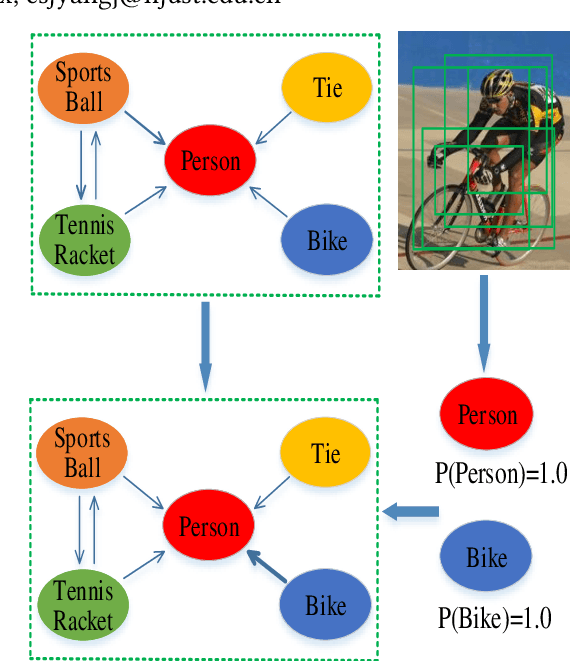
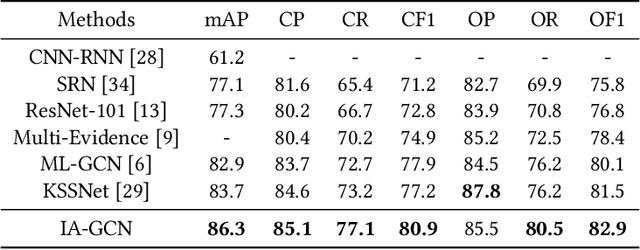
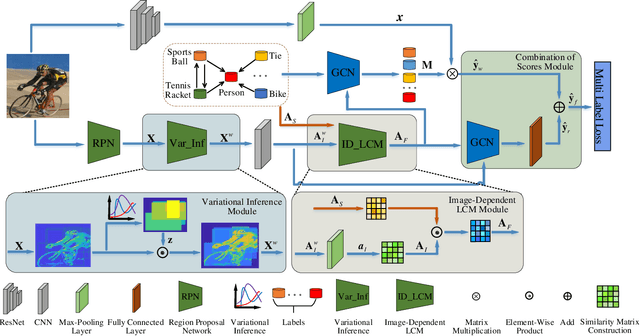
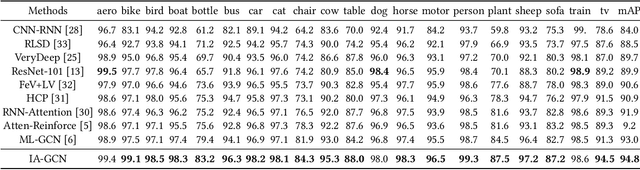
Graph convolutional neural network (GCN) has effectively boosted the multi-label image recognition task by introducing label dependencies based on statistical label co-occurrence of data. However, in previous methods, label correlation is computed based on statistical information of data and therefore the same for all samples, and this makes graph inference on labels insufficient to handle huge variations among numerous image instances. In this paper, we propose an instance-aware graph convolutional neural network (IA-GCN) framework for multi-label classification. As a whole, two fused branches of sub-networks are involved in the framework: a global branch modeling the whole image and a region-based branch exploring dependencies among regions of interests (ROIs). For label diffusion of instance-awareness in graph convolution, rather than using the statistical label correlation alone, an image-dependent label correlation matrix (LCM), fusing both the statistical LCM and an individual one of each image instance, is constructed for graph inference on labels to inject adaptive information of label-awareness into the learned features of the model. Specifically, the individual LCM of each image is obtained by mining the label dependencies based on the scores of labels about detected ROIs. In this process, considering the contribution differences of ROIs to multi-label classification, variational inference is introduced to learn adaptive scaling factors for those ROIs by considering their complex distribution. Finally, extensive experiments on MS-COCO and VOC datasets show that our proposed approach outperforms existing state-of-the-art methods.
Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data
Jul 23, 2018
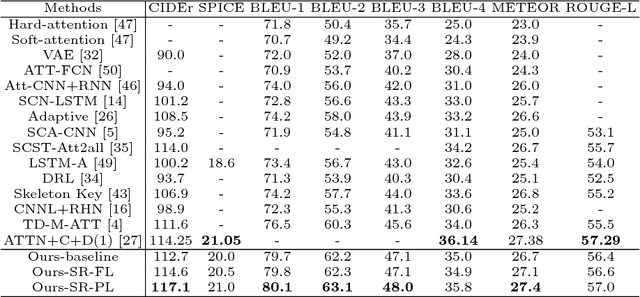
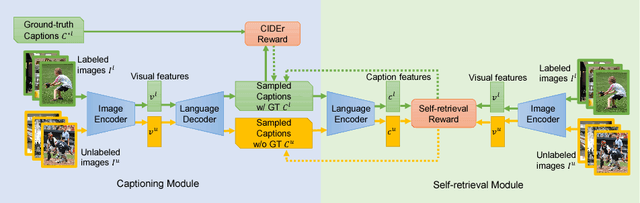
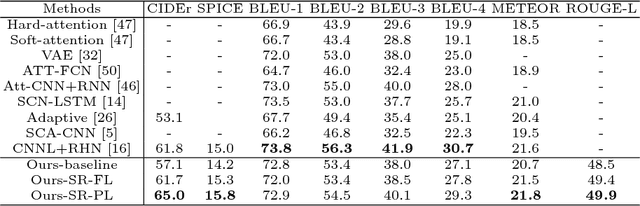
The aim of image captioning is to generate captions by machine to describe image contents. Despite many efforts, generating discriminative captions for images remains non-trivial. Most traditional approaches imitate the language structure patterns, thus tend to fall into a stereotype of replicating frequent phrases or sentences and neglect unique aspects of each image. In this work, we propose an image captioning framework with a self-retrieval module as training guidance, which encourages generating discriminative captions. It brings unique advantages: (1) the self-retrieval guidance can act as a metric and an evaluator of caption discriminativeness to assure the quality of generated captions. (2) The correspondence between generated captions and images are naturally incorporated in the generation process without human annotations, and hence our approach could utilize a large amount of unlabeled images to boost captioning performance with no additional laborious annotations. We demonstrate the effectiveness of the proposed retrieval-guided method on COCO and Flickr30k captioning datasets, and show its superior captioning performance with more discriminative captions.
Image Anomalies: a Review and Synthesis of Detection Methods
Aug 07, 2018
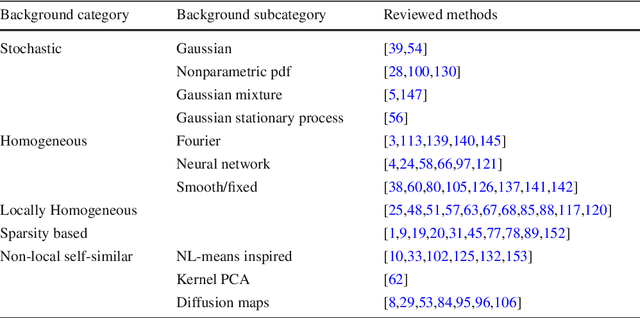

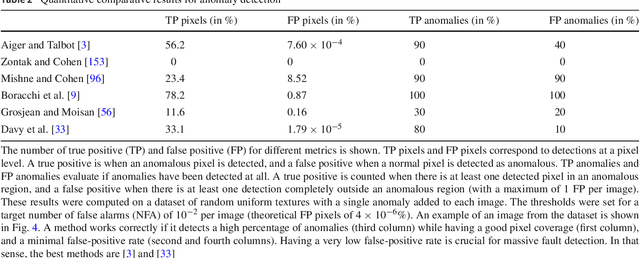
We review the broad variety of methods that have been proposed for anomaly detection in images. Most methods found in the literature have in mind a particular application. Yet we show that the methods can be classified mainly by the structural assumption they make on the "normal" image. Five different structural assumptions emerge. Our analysis leads us to reformulate the best representative algorithms by attaching to them an a contrario detection that controls the number of false positives and thus derive universal detection thresholds. By combining the most general structural assumptions expressing the background's normality with the best proposed statistical detection tools, we end up proposing generic algorithms that seem to generalize or reconcile most methods. We compare the six best representatives of our proposed classes of algorithms on anomalous images taken from classic papers on the subject, and on a synthetic database. Our conclusion is that it is possible to perform automatic anomaly detection on a single image.
Robust Differentiable SVD
Apr 08, 2021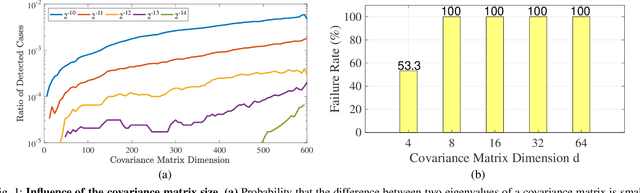



Eigendecomposition of symmetric matrices is at the heart of many computer vision algorithms. However, the derivatives of the eigenvectors tend to be numerically unstable, whether using the SVD to compute them analytically or using the Power Iteration (PI) method to approximate them. This instability arises in the presence of eigenvalues that are close to each other. This makes integrating eigendecomposition into deep networks difficult and often results in poor convergence, particularly when dealing with large matrices. While this can be mitigated by partitioning the data into small arbitrary groups, doing so has no theoretical basis and makes it impossible to exploit the full power of eigendecomposition. In previous work, we mitigated this using SVD during the forward pass and PI to compute the gradients during the backward pass. However, the iterative deflation procedure required to compute multiple eigenvectors using PI tends to accumulate errors and yield inaccurate gradients. Here, we show that the Taylor expansion of the SVD gradient is theoretically equivalent to the gradient obtained using PI without relying in practice on an iterative process and thus yields more accurate gradients. We demonstrate the benefits of this increased accuracy for image classification and style transfer.
* IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) PREPRINT 2021
Semantic View Synthesis
Aug 24, 2020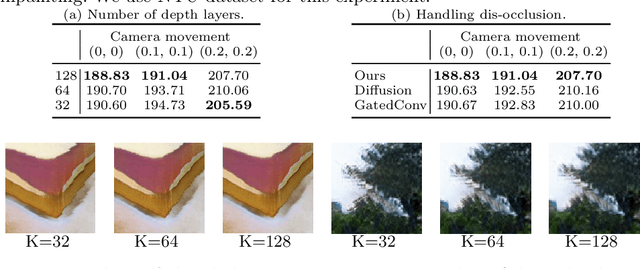
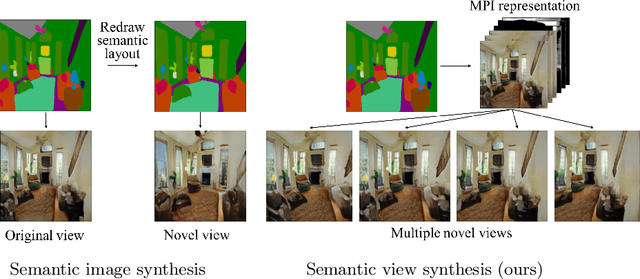
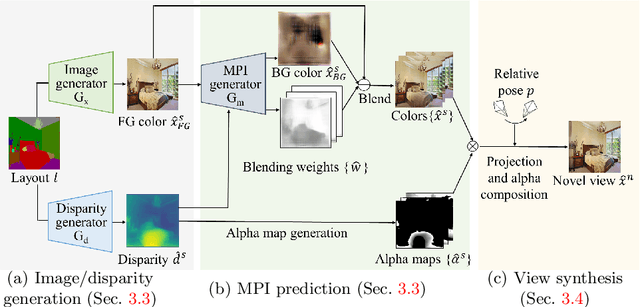

We tackle a new problem of semantic view synthesis -- generating free-viewpoint rendering of a synthesized scene using a semantic label map as input. We build upon recent advances in semantic image synthesis and view synthesis for handling photographic image content generation and view extrapolation. Direct application of existing image/view synthesis methods, however, results in severe ghosting/blurry artifacts. To address the drawbacks, we propose a two-step approach. First, we focus on synthesizing the color and depth of the visible surface of the 3D scene. We then use the synthesized color and depth to impose explicit constraints on the multiple-plane image (MPI) representation prediction process. Our method produces sharp contents at the original view and geometrically consistent renderings across novel viewpoints. The experiments on numerous indoor and outdoor images show favorable results against several strong baselines and validate the effectiveness of our approach.
Convolutional Nonlinear Dictionary with Cascaded Structure Filter Banks
Sep 02, 2020
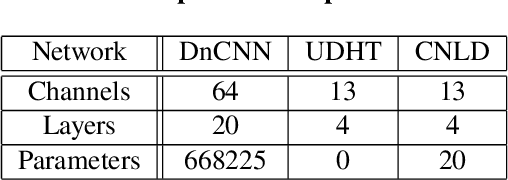
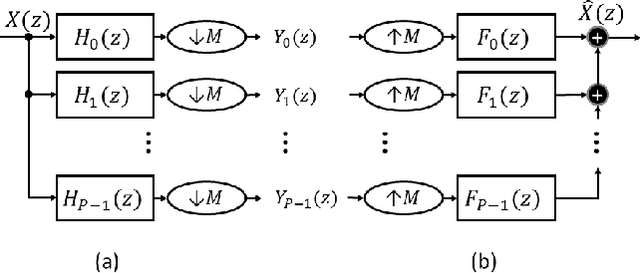
This study proposes a convolutional nonlinear dictionary (CNLD) for image restoration using cascaded filter banks. Generally, convolutional neural networks (CNN) demonstrate their practicality in image restoration applications; however, existing CNNs are constructed without considering the relationship among atomic images (convolution kernels). As a result, there remains room for discussing the role of design spaces. To provide a framework for constructing an effective and structured convolutional network, this study proposes the CNLD. The backpropagation learning procedure is derived from certain image restoration experiments, and thereby the significance of CNLD is verified. It is demonstrated that the number of parameters is reduced while preserving the restoration performance.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021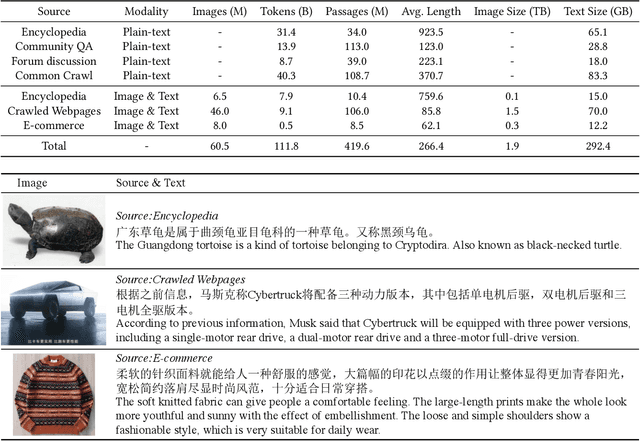
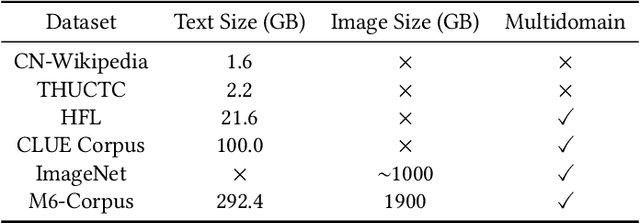

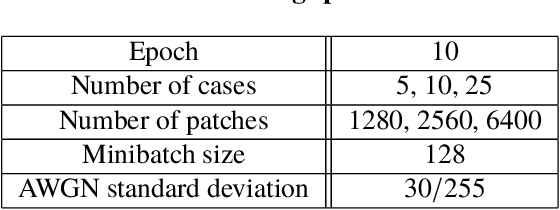
In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.
GenderRobustness: Robustness of Gender Detection in Facial Recognition Systems with variation in Image Properties
Nov 26, 2020In recent times, there have been increasing accusations on artificial intelligence systems and algorithms of computer vision of possessing implicit biases. Even though these conversations are more prevalent now and systems are improving by performing extensive testing and broadening their horizon, biases still do exist. One such class of systems where bias is said to exist is facial recognition systems, where bias has been observed on the basis of gender, ethnicity, skin tone and other facial attributes. This is even more disturbing, given the fact that these systems are used in practically every sector of the industries today. From as critical as criminal identification to as simple as getting your attendance registered, these systems have gained a huge market, especially in recent years. That in itself is a good enough reason for developers of these systems to ensure that the bias is kept to a bare minimum or ideally non-existent, to avoid major issues like favoring a particular gender, race, or class of people or rather making a class of people susceptible to false accusations due to inability of these systems to correctly recognize those people.