 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

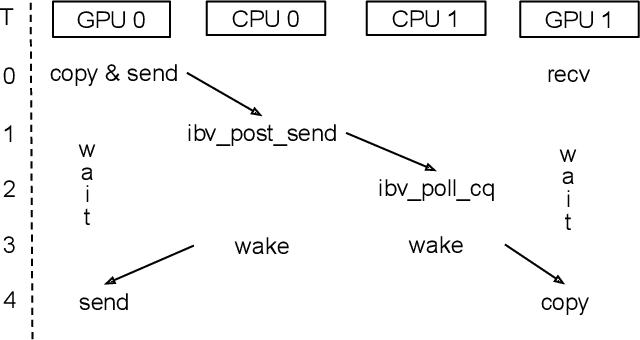
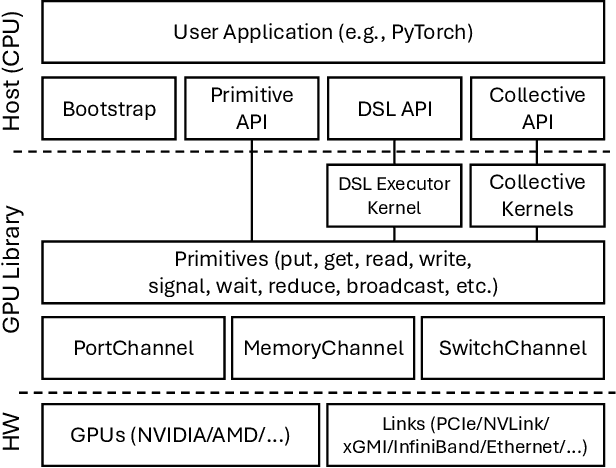
Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
DroidSpeak: Enhancing Cross-LLM Communication
Nov 05, 2024



In multi-agent systems utilizing Large Language Models (LLMs), communication between agents traditionally relies on natural language. This communication often includes the full context of the query so far, which can introduce significant prefill-phase latency, especially with long contexts. We introduce DroidSpeak, a novel framework to target this cross-LLM communication by leveraging the reuse of intermediate data, such as input embeddings (E-cache) and key-value caches (KV-cache). We efficiently bypass the need to reprocess entire contexts for fine-tuned versions of the same foundational model. This approach allows faster context integration while maintaining the quality of task performance. Experimental evaluations demonstrate DroidSpeak's ability to significantly accelerate inter-agent communication, achieving up to a 2.78x speedup in prefill latency with negligible loss in accuracy. Our findings underscore the potential to create more efficient and scalable multi-agent systems.
LLM-Vectorizer: LLM-based Verified Loop Vectorizer
Jun 07, 2024



Vectorization is a powerful optimization technique that significantly boosts the performance of high performance computing applications operating on large data arrays. Despite decades of research on auto-vectorization, compilers frequently miss opportunities to vectorize code. On the other hand, writing vectorized code manually using compiler intrinsics is still a complex, error-prone task that demands deep knowledge of specific architecture and compilers. In this paper, we evaluate the potential of large-language models (LLMs) to generate vectorized (Single Instruction Multiple Data) code from scalar programs that process individual array elements. We propose a novel finite-state machine multi-agents based approach that harnesses LLMs and test-based feedback to generate vectorized code. Our findings indicate that LLMs are capable of producing high performance vectorized code with run-time speedup ranging from 1.1x to 9.4x as compared to the state-of-the-art compilers such as Intel Compiler, GCC, and Clang. To verify the correctness of vectorized code, we use Alive2, a leading bounded translation validation tool for LLVM IR. We describe a few domain-specific techniques to improve the scalability of Alive2 on our benchmark dataset. Overall, our approach is able to verify 38.2% of vectorizations as correct on the TSVC benchmark dataset.
Towards Generating Functionally Correct Code Edits from Natural Language Issue Descriptions
Apr 07, 2023



Large language models (LLMs), such as OpenAI's Codex, have demonstrated their potential to generate code from natural language descriptions across a wide range of programming tasks. Several benchmarks have recently emerged to evaluate the ability of LLMs to generate functionally correct code from natural language intent with respect to a set of hidden test cases. This has enabled the research community to identify significant and reproducible advancements in LLM capabilities. However, there is currently a lack of benchmark datasets for assessing the ability of LLMs to generate functionally correct code edits based on natural language descriptions of intended changes. This paper aims to address this gap by motivating the problem NL2Fix of translating natural language descriptions of code changes (namely bug fixes described in Issue reports in repositories) into correct code fixes. To this end, we introduce Defects4J-NL2Fix, a dataset of 283 Java programs from the popular Defects4J dataset augmented with high-level descriptions of bug fixes, and empirically evaluate the performance of several state-of-the-art LLMs for the this task. Results show that these LLMS together are capable of generating plausible fixes for 64.6% of the bugs, and the best LLM-based technique can achieve up to 21.20% top-1 and 35.68% top-5 accuracy on this benchmark.
Synthesizing Collective Communication Algorithms for Heterogeneous Networks with TACCL
Nov 15, 2021

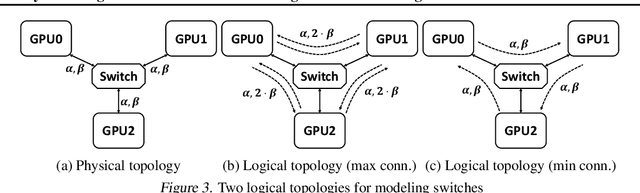
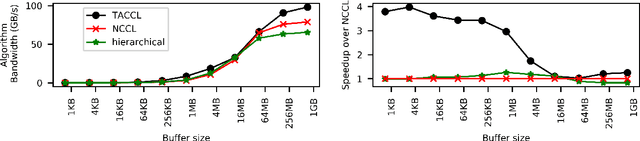
Large ML models and datasets have necessitated the use of multi-GPU systems for distributed model training. To harness the power offered by multi-GPU systems, it is critical to eliminate bottlenecks in inter-GPU communication - a problem made challenging by the heterogeneous nature of interconnects. In this work, we present TACCL, a synthesizer for collective communication primitives for large-scale multi-GPU systems. TACCL encodes a profiled topology and input size into a synthesis problem to generate optimized communication algorithms. TACCL is built on top of the standard NVIDIA Collective Communication Library (NCCL), allowing it to be a drop-in replacement for GPU communication in frameworks like PyTorch with minimal changes. TACCL generates algorithms for communication primitives like Allgather, Alltoall, and Allreduce that are up to $3\times$ faster than NCCL. Using TACCL's algorithms speeds up the end-to-end training of an internal mixture of experts model by $17\%$. By decomposing the optimization problem into parts and leveraging the symmetry in multi-GPU topologies, TACCL synthesizes collectives for up to 80-GPUs in less than 3 minutes, at least two orders of magnitude faster than other synthesis-based state-of-the-art collective communication libraries.
GenderRobustness: Robustness of Gender Detection in Facial Recognition Systems with variation in Image Properties
Nov 26, 2020In recent times, there have been increasing accusations on artificial intelligence systems and algorithms of computer vision of possessing implicit biases. Even though these conversations are more prevalent now and systems are improving by performing extensive testing and broadening their horizon, biases still do exist. One such class of systems where bias is said to exist is facial recognition systems, where bias has been observed on the basis of gender, ethnicity, skin tone and other facial attributes. This is even more disturbing, given the fact that these systems are used in practically every sector of the industries today. From as critical as criminal identification to as simple as getting your attendance registered, these systems have gained a huge market, especially in recent years. That in itself is a good enough reason for developers of these systems to ensure that the bias is kept to a bare minimum or ideally non-existent, to avoid major issues like favoring a particular gender, race, or class of people or rather making a class of people susceptible to false accusations due to inability of these systems to correctly recognize those people.
Scaling Distributed Training with Adaptive Summation
Jun 04, 2020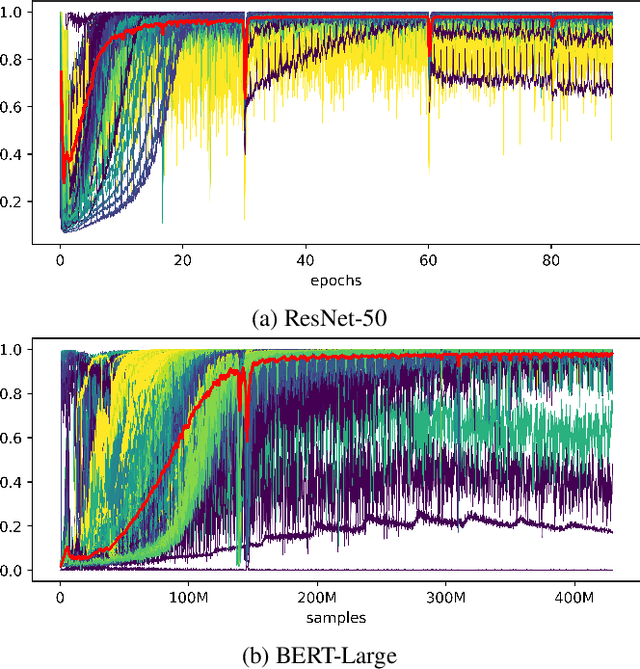
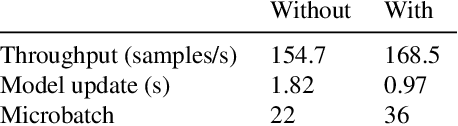
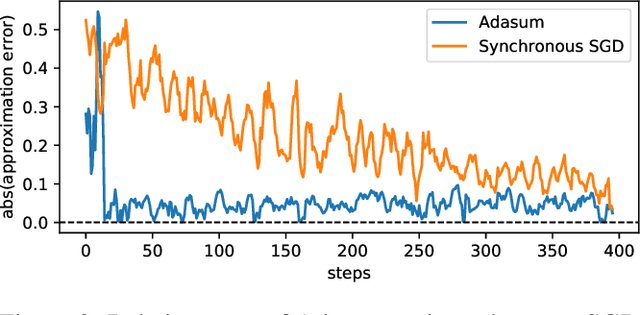

Stochastic gradient descent (SGD) is an inherently sequential training algorithm--computing the gradient at batch $i$ depends on the model parameters learned from batch $i-1$. Prior approaches that break this dependence do not honor them (e.g., sum the gradients for each batch, which is not what sequential SGD would do) and thus potentially suffer from poor convergence. This paper introduces a novel method to combine gradients called Adasum (for adaptive sum) that converges faster than prior work. Adasum is easy to implement, almost as efficient as simply summing gradients, and is integrated into the open-source toolkit Horovod. This paper first provides a formal justification for Adasum and then empirically demonstrates Adasum is more accurate than prior gradient accumulation methods. It then introduces a series of case-studies to show Adasum works with multiple frameworks, (TensorFlow and PyTorch), scales multiple optimizers (Momentum-SGD, Adam, and LAMB) to larger batch-sizes while still giving good downstream accuracy. Finally, it proves that Adasum converges. To summarize, Adasum scales Momentum-SGD on the MLPerf Resnet50 benchmark to 64K examples before communication (no MLPerf v0.5 entry converged with more than 16K), the Adam optimizer to 64K examples before communication on BERT-LARGE (prior work showed Adam stopped scaling at 16K), and the LAMB optimizer to 128K before communication on BERT-LARGE (prior work used 64K), all while maintaining downstream accuracy metrics. Finally, if a user does not need to scale, we show LAMB with Adasum on BERT-LARGE converges in 30% fewer steps than the baseline.
Distributed Word2Vec using Graph Analytics Frameworks
Sep 08, 2019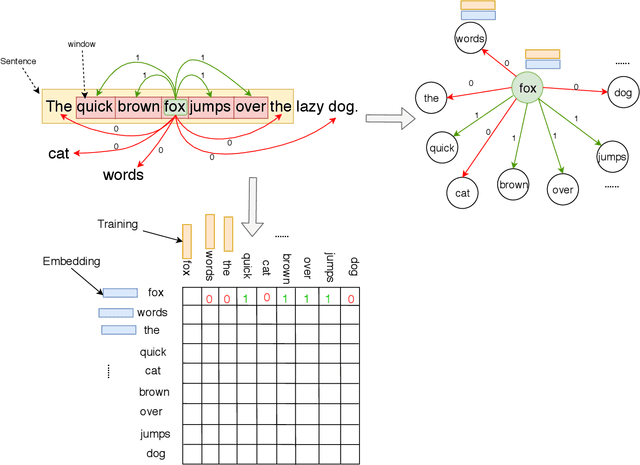
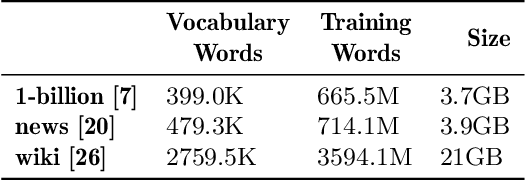
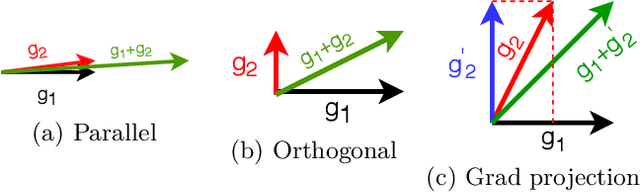
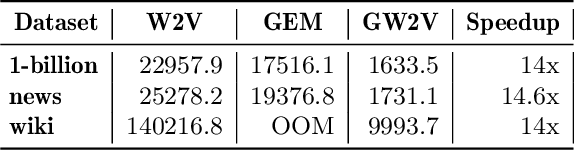
Word embeddings capture semantic and syntactic similarities of words, represented as vectors. Word2Vec is a popular implementation of word embeddings; it takes as input a large corpus of text and learns a model that maps unique words in that corpus to other contextually relevant words. After training, Word2Vec's internal vector representation of words in the corpus map unique words to a vector space, which are then used in many downstream tasks. Training these models requires significant computational resources (training time often measured in days) and is difficult to parallelize. Most word embedding training uses stochastic gradient descent (SGD), an "inherently" sequential algorithm where at each step, the processing of the current example depends on the parameters learned from the previous examples. Prior approaches to parallelizing SGD do not honor these dependencies and thus potentially suffer poor convergence. This paper introduces GraphWord2Vec, a distributedWord2Vec algorithm which formulates the Word2Vec training process as a distributed graph problem and thus leverage state-of-the-art distributed graph analytics frameworks such as D-Galois and Gemini that scale to large distributed clusters. GraphWord2Vec also demonstrates how to use model combiners to honor data dependencies in SGD and thus scale without giving up convergence. We will show that GraphWord2Vec has linear scalability up to 32 machines converging as fast as a sequential run in terms of epochs, thus reducing training time by 14x.