 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Motion Graphs
Mar 26, 2025We present Video Motion Graphs, a system designed to generate realistic human motion videos. Using a reference video and conditional signals such as music or motion tags, the system synthesizes new videos by first retrieving video clips with gestures matching the conditions and then generating interpolation frames to seamlessly connect clip boundaries. The core of our approach is HMInterp, a robust Video Frame Interpolation (VFI) model that enables seamless interpolation of discontinuous frames, even for complex motion scenarios like dancing. HMInterp i) employs a dual-branch interpolation approach, combining a Motion Diffusion Model for human skeleton motion interpolation with a diffusion-based video frame interpolation model for final frame generation. ii) adopts condition progressive training to effectively leverage identity strong and weak conditions, such as images and pose. These designs ensure both high video texture quality and accurate motion trajectory. Results show that our Video Motion Graphs outperforms existing generative- and retrieval-based methods for multi-modal conditioned human motion video generation. Project page can be found at https://h-liu1997.github.io/Video-Motion-Graphs/
Move-in-2D: 2D-Conditioned Human Motion Generation
Dec 17, 2024



Generating realistic human videos remains a challenging task, with the most effective methods currently relying on a human motion sequence as a control signal. Existing approaches often use existing motion extracted from other videos, which restricts applications to specific motion types and global scene matching. We propose Move-in-2D, a novel approach to generate human motion sequences conditioned on a scene image, allowing for diverse motion that adapts to different scenes. Our approach utilizes a diffusion model that accepts both a scene image and text prompt as inputs, producing a motion sequence tailored to the scene. To train this model, we collect a large-scale video dataset featuring single-human activities, annotating each video with the corresponding human motion as the target output. Experiments demonstrate that our method effectively predicts human motion that aligns with the scene image after projection. Furthermore, we show that the generated motion sequence improves human motion quality in video synthesis tasks.
KITTEN: A Knowledge-Intensive Evaluation of Image Generation on Visual Entities
Oct 15, 2024



Recent advancements in text-to-image generation have significantly enhanced the quality of synthesized images. Despite this progress, evaluations predominantly focus on aesthetic appeal or alignment with text prompts. Consequently, there is limited understanding of whether these models can accurately represent a wide variety of realistic visual entities - a task requiring real-world knowledge. To address this gap, we propose a benchmark focused on evaluating Knowledge-InTensive image generaTion on real-world ENtities (i.e., KITTEN). Using KITTEN, we conduct a systematic study on the fidelity of entities in text-to-image generation models, focusing on their ability to generate a wide range of real-world visual entities, such as landmark buildings, aircraft, plants, and animals. We evaluate the latest text-to-image models and retrieval-augmented customization models using both automatic metrics and carefully-designed human evaluations, with an emphasis on the fidelity of entities in the generated images. Our findings reveal that even the most advanced text-to-image models often fail to generate entities with accurate visual details. Although retrieval-augmented models can enhance the fidelity of entity by incorporating reference images during testing, they often over-rely on these references and struggle to produce novel configurations of the entity as requested in creative text prompts.
Fine-grained Controllable Video Generation via Object Appearance and Context
Dec 05, 2023



Text-to-video generation has shown promising results. However, by taking only natural languages as input, users often face difficulties in providing detailed information to precisely control the model's output. In this work, we propose fine-grained controllable video generation (FACTOR) to achieve detailed control. Specifically, FACTOR aims to control objects' appearances and context, including their location and category, in conjunction with the text prompt. To achieve detailed control, we propose a unified framework to jointly inject control signals into the existing text-to-video model. Our model consists of a joint encoder and adaptive cross-attention layers. By optimizing the encoder and the inserted layer, we adapt the model to generate videos that are aligned with both text prompts and fine-grained control. Compared to existing methods relying on dense control signals such as edge maps, we provide a more intuitive and user-friendly interface to allow object-level fine-grained control. Our method achieves controllability of object appearances without finetuning, which reduces the per-subject optimization efforts for the users. Extensive experiments on standard benchmark datasets and user-provided inputs validate that our model obtains a 70% improvement in controllability metrics over competitive baselines.
Video Generation Beyond a Single Clip
Apr 15, 2023We tackle the long video generation problem, i.e.~generating videos beyond the output length of video generation models. Due to the computation resource constraints, video generation models can only generate video clips that are relatively short compared with the length of real videos. Existing works apply a sliding window approach to generate long videos at inference time, which is often limited to generating recurrent events or homogeneous content. To generate long videos covering diverse content and multiple events, we propose to use additional guidance to control the video generation process. We further present a two-stage approach to the problem, which allows us to utilize existing video generation models to generate high-quality videos within a small time window while modeling the video holistically based on the input guidance. The proposed approach is complementary to existing efforts on video generation, which focus on generating realistic video within a fixed time window. Extensive experiments on challenging real-world videos validate the benefit of the proposed method, which improves over state-of-the-art by up to 9.5% in objective metrics and is preferred by users more than 80% of time.
Self-supervised AutoFlow
Dec 08, 2022



Recently, AutoFlow has shown promising results on learning a training set for optical flow, but requires ground truth labels in the target domain to compute its search metric. Observing a strong correlation between the ground truth search metric and self-supervised losses, we introduce self-supervised AutoFlow to handle real-world videos without ground truth labels. Using self-supervised loss as the search metric, our self-supervised AutoFlow performs on par with AutoFlow on Sintel and KITTI where ground truth is available, and performs better on the real-world DAVIS dataset. We further explore using self-supervised AutoFlow in the (semi-)supervised setting and obtain competitive results against the state of the art.
Adaptive Transformers for Robust Few-shot Cross-domain Face Anti-spoofing
Mar 23, 2022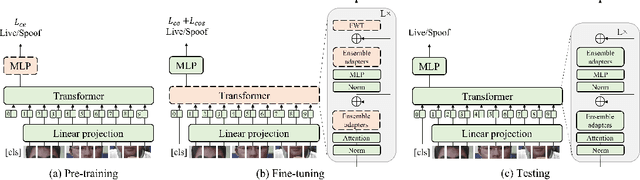
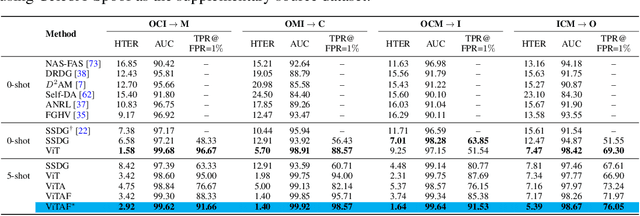
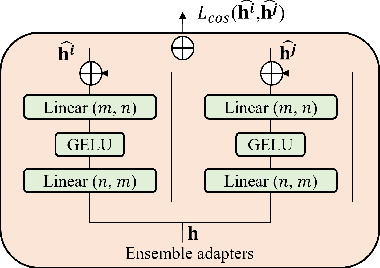
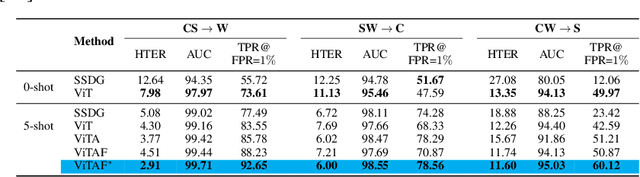
While recent face anti-spoofing methods perform well under the intra-domain setups, an effective approach needs to account for much larger appearance variations of images acquired in complex scenes with different sensors for robust performance. In this paper, we present adaptive vision transformers (ViT) for robust cross-domain face anti-spoofing. Specifically, we adopt ViT as a backbone to exploit its strength to account for long-range dependencies among pixels. We further introduce the ensemble adapters module and feature-wise transformation layers in the ViT to adapt to different domains for robust performance with a few samples. Experiments on several benchmark datasets show that the proposed models achieve both robust and competitive performance against the state-of-the-art methods.
Learning to Stylize Novel Views
May 27, 2021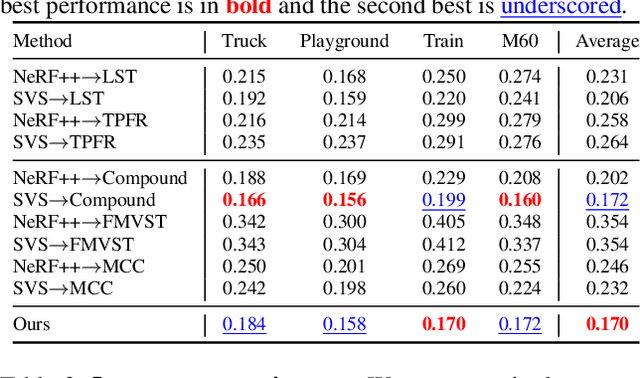

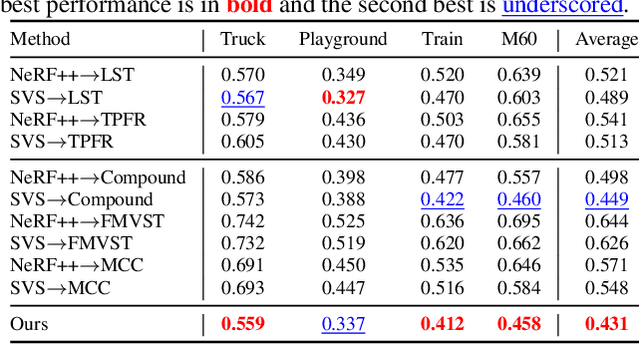
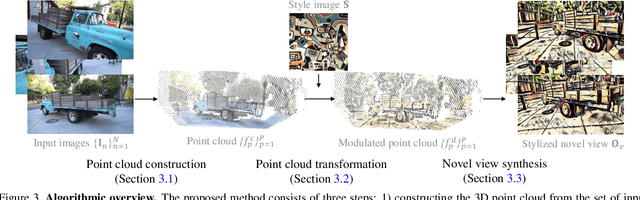
We tackle a 3D scene stylization problem - generating stylized images of a scene from arbitrary novel views given a set of images of the same scene and a reference image of the desired style as inputs. Direct solution of combining novel view synthesis and stylization approaches lead to results that are blurry or not consistent across different views. We propose a point cloud-based method for consistent 3D scene stylization. First, we construct the point cloud by back-projecting the image features to the 3D space. Second, we develop point cloud aggregation modules to gather the style information of the 3D scene, and then modulate the features in the point cloud with a linear transformation matrix. Finally, we project the transformed features to 2D space to obtain the novel views. Experimental results on two diverse datasets of real-world scenes validate that our method generates consistent stylized novel view synthesis results against other alternative approaches.
Semantic View Synthesis
Aug 24, 2020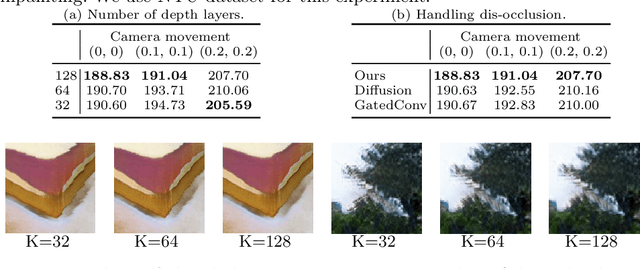
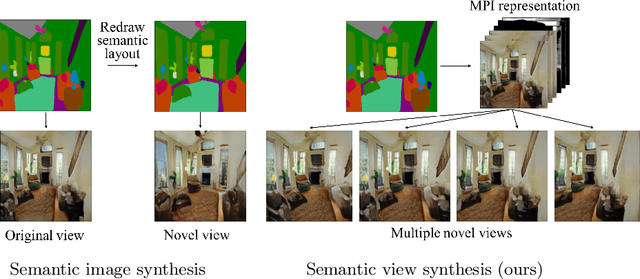
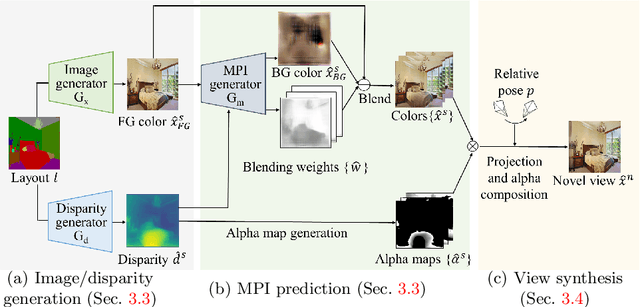

We tackle a new problem of semantic view synthesis -- generating free-viewpoint rendering of a synthesized scene using a semantic label map as input. We build upon recent advances in semantic image synthesis and view synthesis for handling photographic image content generation and view extrapolation. Direct application of existing image/view synthesis methods, however, results in severe ghosting/blurry artifacts. To address the drawbacks, we propose a two-step approach. First, we focus on synthesizing the color and depth of the visible surface of the 3D scene. We then use the synthesized color and depth to impose explicit constraints on the multiple-plane image (MPI) representation prediction process. Our method produces sharp contents at the original view and geometrically consistent renderings across novel viewpoints. The experiments on numerous indoor and outdoor images show favorable results against several strong baselines and validate the effectiveness of our approach.
Unsupervised Adversarial Domain Adaptation for Implicit Discourse Relation Classification
Apr 15, 2020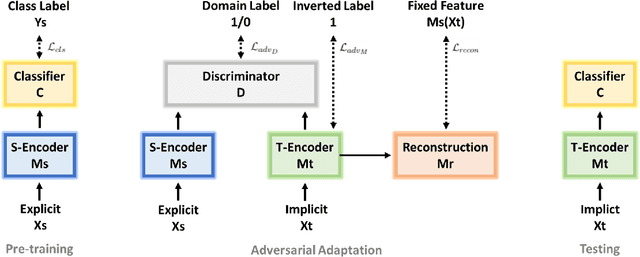
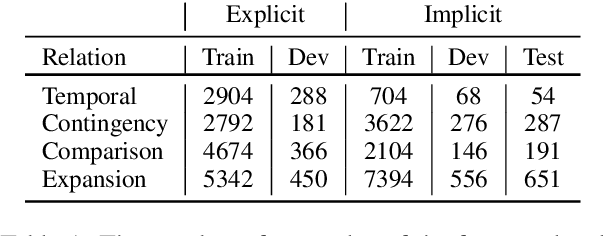
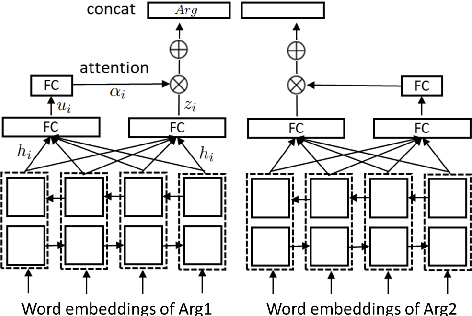
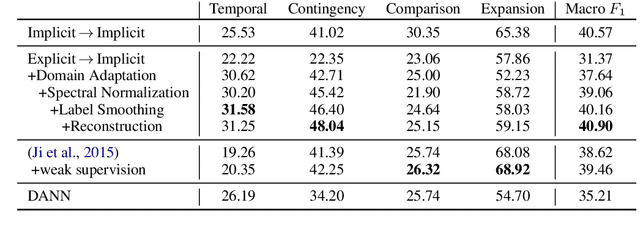
Implicit discourse relations are not only more challenging to classify, but also to annotate, than their explicit counterparts. We tackle situations where training data for implicit relations are lacking, and exploit domain adaptation from explicit relations (Ji et al., 2015). We present an unsupervised adversarial domain adaptive network equipped with a reconstruction component. Our system outperforms prior works and other adversarial benchmarks for unsupervised domain adaptation. Additionally, we extend our system to take advantage of labeled data if some are available.