 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comparative Study of Deep Learning Loss Functions for Multi-Label Remote Sensing Image Classification
Sep 29, 2020
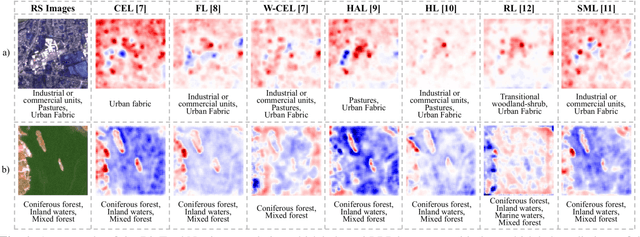
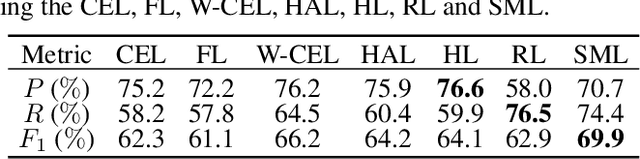
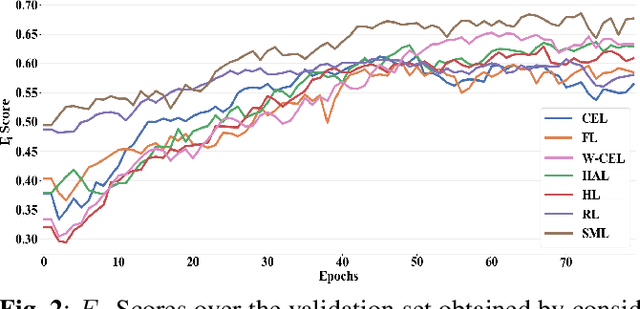
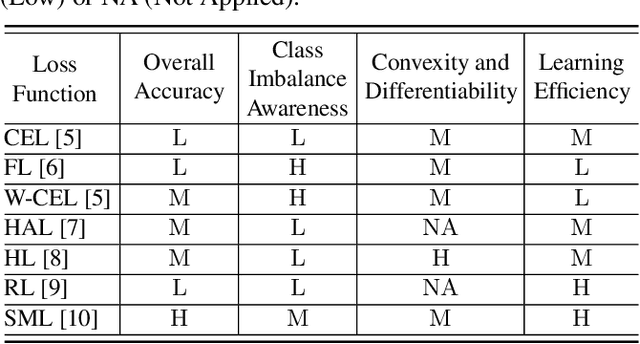
This paper analyzes and compares different deep learning loss functions in the framework of multi-label remote sensing (RS) image scene classification problems. We consider seven loss functions: 1) cross-entropy loss; 2) focal loss; 3) weighted cross-entropy loss; 4) Hamming loss; 5) Huber loss; 6) ranking loss; and 7) sparseMax loss. All the considered loss functions are analyzed for the first time in RS. After a theoretical analysis, an experimental analysis is carried out to compare the considered loss functions in terms of their: 1) overall accuracy; 2) class imbalance awareness (for which the number of samples associated to each class significantly varies); 3) convexibility and differentiability; and 4) learning efficiency (i.e., convergence speed). On the basis of our analysis, some guidelines are derived for a proper selection of a loss function in multi-label RS scene classification problems.
ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks
Oct 23, 2021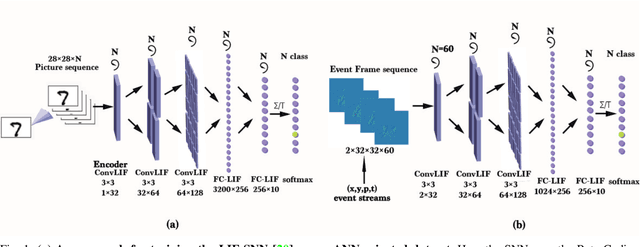
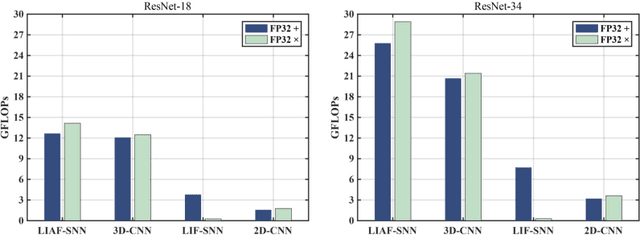
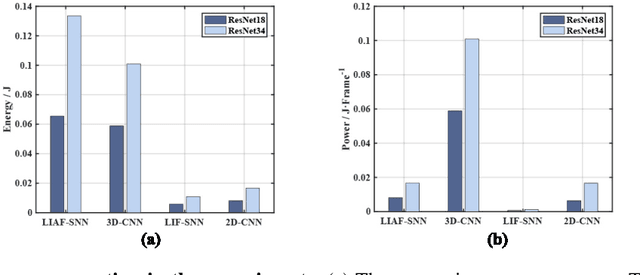
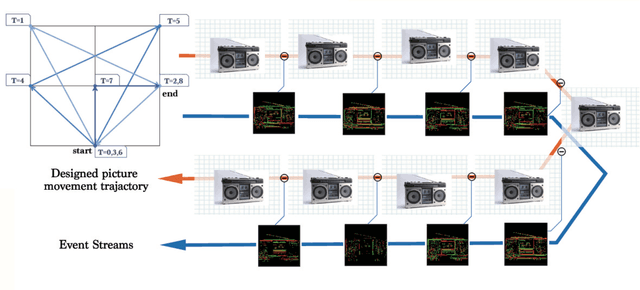
With event-driven algorithms, especially the spiking neural networks (SNNs), achieving continuous improvement in neuromorphic vision processing, a more challenging event-stream-dataset is urgently needed. However, it is well known that creating an ES-dataset is a time-consuming and costly task with neuromorphic cameras like dynamic vision sensors (DVS). In this work, we propose a fast and effective algorithm termed Omnidirectional Discrete Gradient (ODG) to convert the popular computer vision dataset ILSVRC2012 into its event-stream (ES) version, generating about 1,300,000 frame-based images into ES-samples in 1000 categories. In this way, we propose an ES-dataset called ES-ImageNet, which is dozens of times larger than other neuromorphic classification datasets at present and completely generated by the software. The ODG algorithm implements an image motion to generate local value changes with discrete gradient information in different directions, providing a low-cost and high-speed way for converting frame-based images into event streams, along with Edge-Integral to reconstruct the high-quality images from event streams. Furthermore, we analyze the statistics of the ES-ImageNet in multiple ways, and a performance benchmark of the dataset is also provided using both famous deep neural network algorithms and spiking neural network algorithms. We believe that this work shall provide a new large-scale benchmark dataset for SNNs and neuromorphic vision.
Constrained Generative Adversarial Networks for Interactive Image Generation
Apr 03, 2019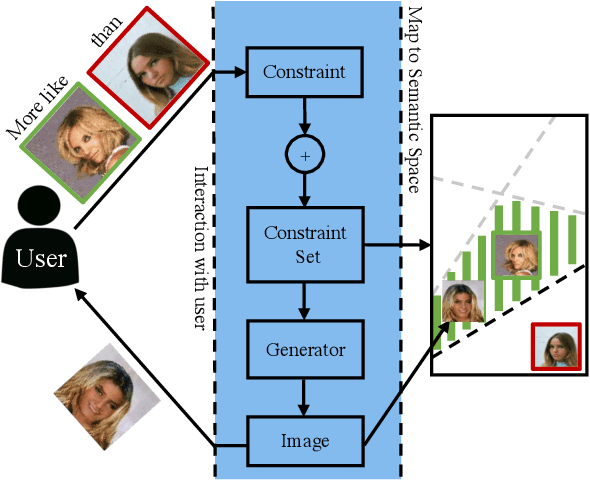


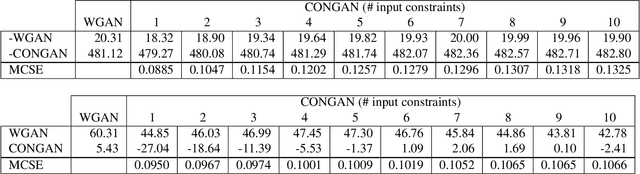
Generative Adversarial Networks (GANs) have received a great deal of attention due in part to recent success in generating original, high-quality samples from visual domains. However, most current methods only allow for users to guide this image generation process through limited interactions. In this work we develop a novel GAN framework that allows humans to be "in-the-loop" of the image generation process. Our technique iteratively accepts relative constraints of the form "Generate an image more like image A than image B". After each constraint is given, the user is presented with new outputs from the GAN, informing the next round of feedback. This feedback is used to constrain the output of the GAN with respect to an underlying semantic space that can be designed to model a variety of different notions of similarity (e.g. classes, attributes, object relationships, color, etc.). In our experiments, we show that our GAN framework is able to generate images that are of comparable quality to equivalent unsupervised GANs while satisfying a large number of the constraints provided by users, effectively changing a GAN into one that allows users interactive control over image generation without sacrificing image quality.
The Medical Segmentation Decathlon
Jun 10, 2021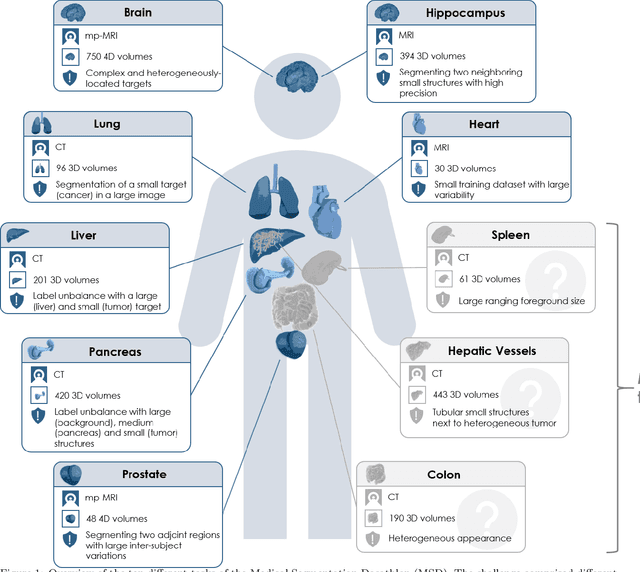
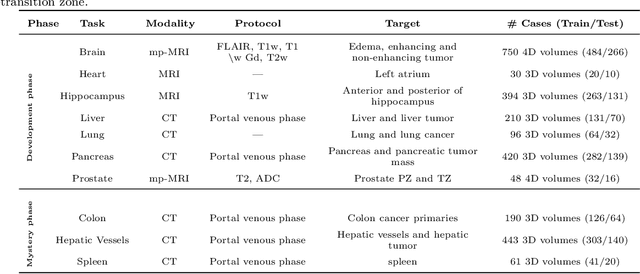
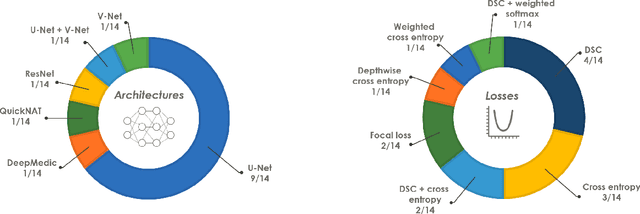
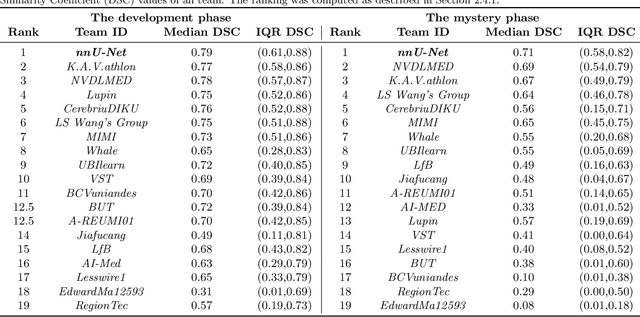
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Learning Multilingual Word Embeddings Using Image-Text Data
May 29, 2019
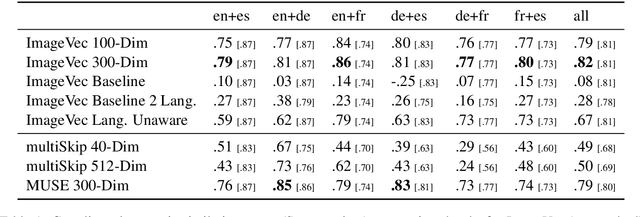
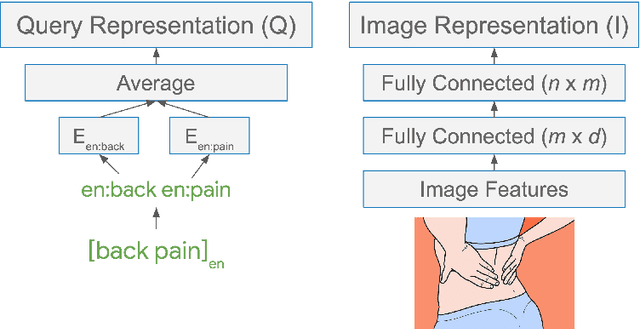
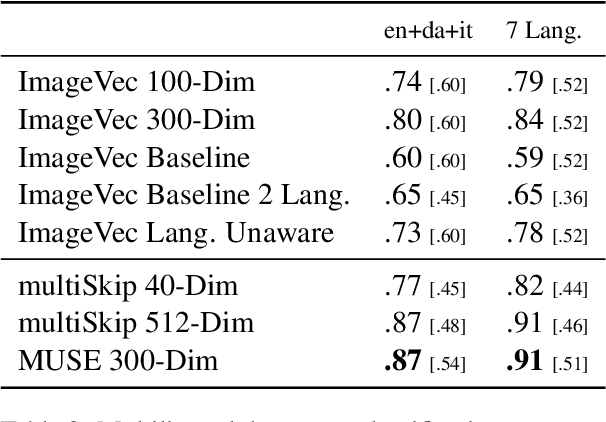
There has been significant interest recently in learning multilingual word embeddings -- in which semantically similar words across languages have similar embeddings. State-of-the-art approaches have relied on expensive labeled data, which is unavailable for low-resource languages, or have involved post-hoc unification of monolingual embeddings. In the present paper, we investigate the efficacy of multilingual embeddings learned from weakly-supervised image-text data. In particular, we propose methods for learning multilingual embeddings using image-text data, by enforcing similarity between the representations of the image and that of the text. Our experiments reveal that even without using any expensive labeled data, a bag-of-words-based embedding model trained on image-text data achieves performance comparable to the state-of-the-art on crosslingual semantic similarity tasks.
Towards Unsupervised Image Captioning with Shared Multimodal Embeddings
Aug 25, 2019
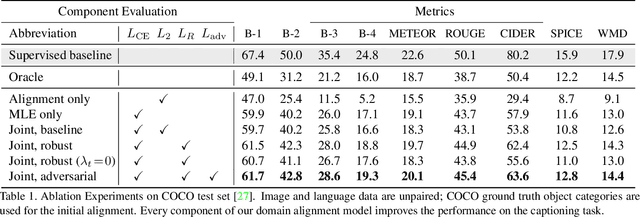
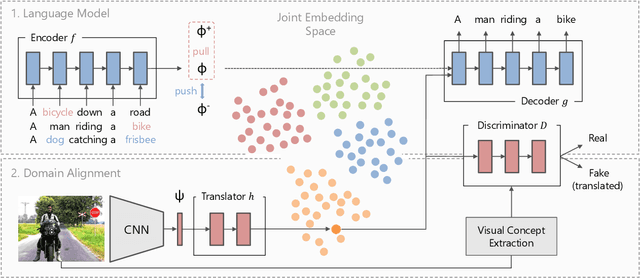
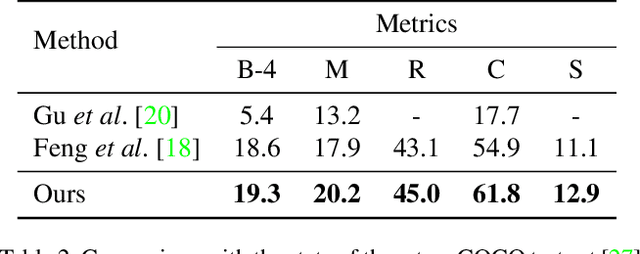
Understanding images without explicit supervision has become an important problem in computer vision. In this paper, we address image captioning by generating language descriptions of scenes without learning from annotated pairs of images and their captions. The core component of our approach is a shared latent space that is structured by visual concepts. In this space, the two modalities should be indistinguishable. A language model is first trained to encode sentences into semantically structured embeddings. Image features that are translated into this embedding space can be decoded into descriptions through the same language model, similarly to sentence embeddings. This translation is learned from weakly paired images and text using a loss robust to noisy assignments and a conditional adversarial component. Our approach allows to exploit large text corpora outside the annotated distributions of image/caption data. Our experiments show that the proposed domain alignment learns a semantically meaningful representation which outperforms previous work.
MIMIR: Deep Regression for Automated Analysis of UK Biobank Body MRI
Jun 22, 2021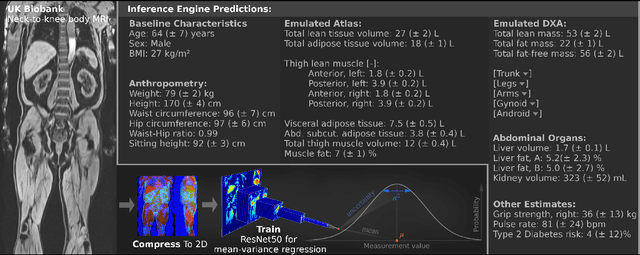
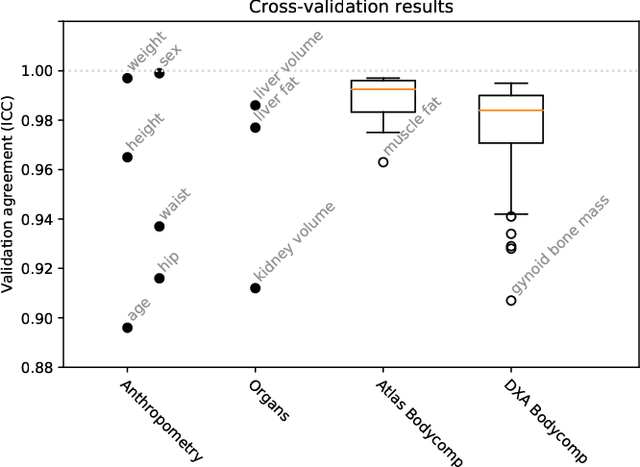
UK Biobank (UKB) is conducting a large-scale study of more than half a million volunteers, collecting health-related information on genetics, lifestyle, blood biochemistry, and more. Medical imaging furthermore targets 100,000 subjects, with 70,000 follow-up sessions, enabling measurements of organs, muscle, and body composition. With up to 170,000 mounting MR images, various methodologies are accordingly engaged in large-scale image analysis. This work presents an experimental inference engine that can automatically predict a comprehensive profile of subject metadata from UKB neck-to-knee body MRI. In cross-validation, it accurately inferred baseline characteristics such as age, height, weight, and sex, but also emulated measurements of body composition by DXA, organ volumes, and abstract properties like grip strength, pulse rate, and type 2 diabetic status (AUC: 0.866). The proposed system can automatically analyze thousands of subjects within hours and provide individual confidence intervals. The underlying methodology is based on convolutional neural networks for image-based mean-variance regression on two-dimensional representations of the MRI data. This work aims to make the proposed system available for free to researchers, who can use it to obtain fast and fully-automated estimates of 72 different measurements immediately upon release of new UK Biobank image data.
Attention W-Net: Improved Skip Connections for better Representations
Oct 17, 2021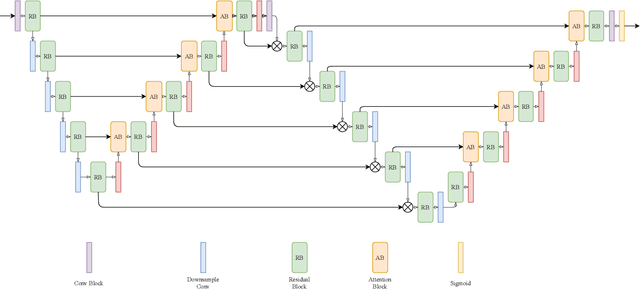

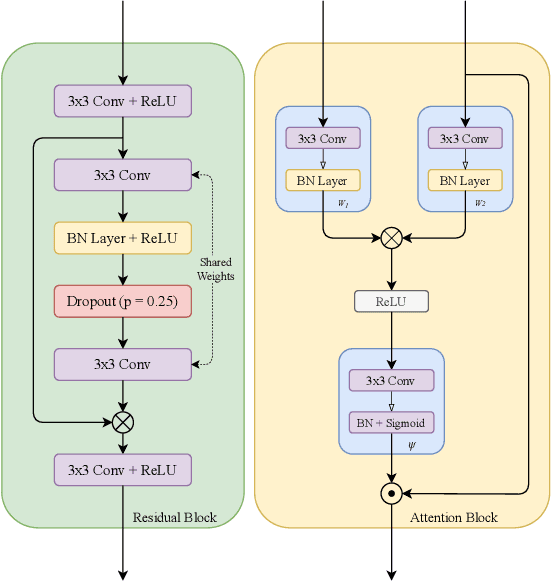
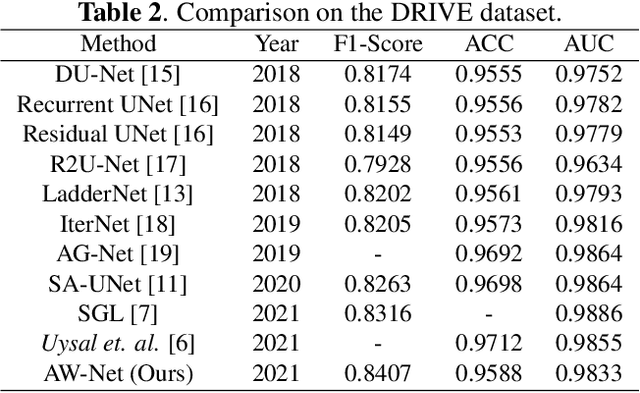
Segmentation of macro and microvascular structures in fundoscopic retinal images plays a crucial role in detection of multiple retinal and systemic diseases, yet it is a difficult problem to solve. Most deep learning approaches for this task involve an autoencoder based architecture, but they face several issues such as lack of enough parameters, overfitting when there are enough parameters and incompatibility between internal feature-spaces. Due to such issues, these techniques are hence not able to extract the best semantic information from the limited data present for such tasks. We propose Attention W-Net, a new U-Net based architecture for retinal vessel segmentation to address these problems. In this architecture with a LadderNet backbone, we have two main contributions: Attention Block and regularisation measures. Our Attention Block uses decoder features to attend over the encoder features from skip-connections during upsampling, resulting in higher compatibility when the encoder and decoder features are added. Our regularisation measures include image augmentation and modifications to the ResNet Block used, which prevent overfitting. With these additions, we observe an AUC and F1-Score of 0.8407 and 0.9833 - a sizeable improvement over its LadderNet backbone as well as competitive performance among the contemporary state-of-the-art methods.
Affinity Fusion Graph-based Framework for Natural Image Segmentation
Jun 24, 2020

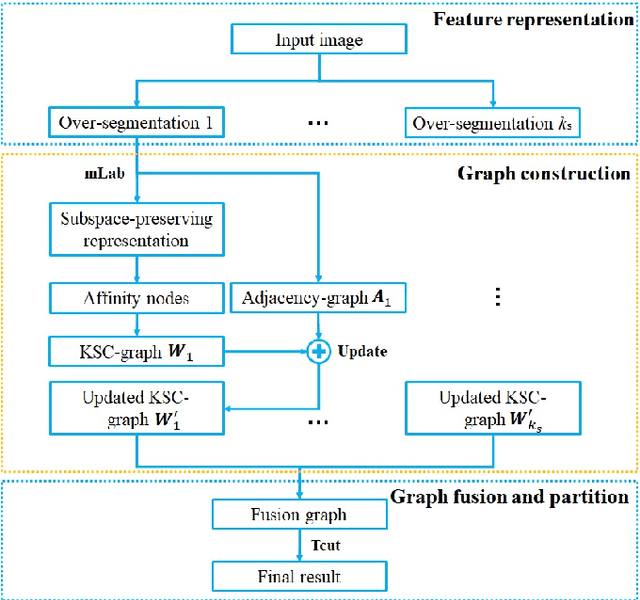
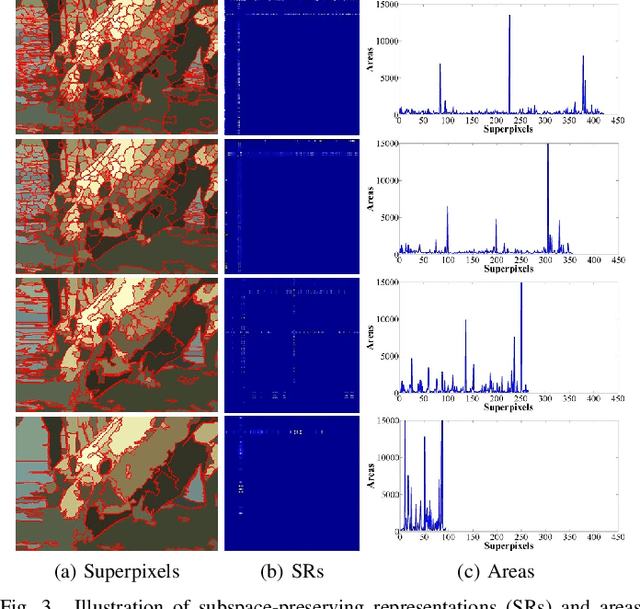
This paper proposes an affinity fusion graph framework to effectively connect different graphs with highly discriminating power and nonlinearity for natural image segmentation. The proposed framework combines adjacency-graphs and kernel spectral clustering based graphs (KSC-graphs) according to a new definition named affinity nodes of multi-scale superpixels. These affinity nodes are selected based on a better affiliation of superpixels, namely subspace-preserving representation which is generated by sparse subspace clustering based on subspace pursuit. Then a KSC-graph is built via a novel kernel spectral clustering to explore the nonlinear relationships among these affinity nodes. Moreover, an adjacency-graph at each scale is constructed, which is further used to update the proposed KSC-graph at affinity nodes. The fusion graph is built across different scales, and it is partitioned to obtain final segmentation result. Experimental results on the Berkeley segmentation dataset and Microsoft Research Cambridge dataset show the superiority of our framework in comparison with the state-of-the-art methods. The code is available at https://github.com/Yangzhangcst/AF-graph.
O2NA: An Object-Oriented Non-Autoregressive Approach for Controllable Video Captioning
Aug 05, 2021
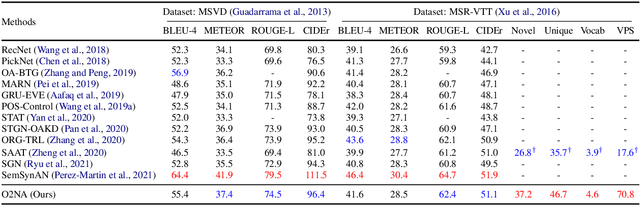
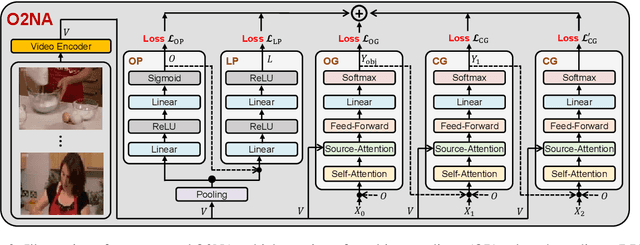
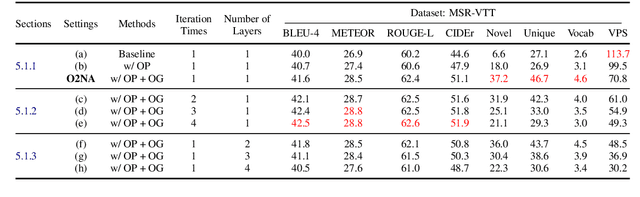
Video captioning combines video understanding and language generation. Different from image captioning that describes a static image with details of almost every object, video captioning usually considers a sequence of frames and biases towards focused objects, e.g., the objects that stay in focus regardless of the changing background. Therefore, detecting and properly accommodating focused objects is critical in video captioning. To enforce the description of focused objects and achieve controllable video captioning, we propose an Object-Oriented Non-Autoregressive approach (O2NA), which performs caption generation in three steps: 1) identify the focused objects and predict their locations in the target caption; 2) generate the related attribute words and relation words of these focused objects to form a draft caption; and 3) combine video information to refine the draft caption to a fluent final caption. Since the focused objects are generated and located ahead of other words, it is difficult to apply the word-by-word autoregressive generation process; instead, we adopt a non-autoregressive approach. The experiments on two benchmark datasets, i.e., MSR-VTT and MSVD, demonstrate the effectiveness of O2NA, which achieves results competitive with the state-of-the-arts but with both higher diversity and higher inference speed.