 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV-Control: Parameter-Efficient K/V Injection for Trajectory-Controlled Text-to-Motion
Jun 04, 2026Text-conditioned 3D human motion models now synthesize plausible motions from prompts, but practical animation and embodied-agent workflows rarely stop at text: a character may need to follow a sketched root path, hit an end-effector target, or satisfy a multi-joint trajectory while still preserving the gait, style, and intent described by language. This exposes a control trade-off. A trajectory controller should be precise without overwriting the pretrained text-conditioned motion prior, yet existing solutions either duplicate large portions of the generator to regain per-layer control access or move much of the cost to test-time optimization. We introduce KV-Control, a compact attention-side control interface for frozen masked text-to-motion transformers. The key idea is to make geometric constraints available as memory inside self-attention rather than injecting them through a global pose token or enforcing them only at the output side. To support this interface, we co-design a part-tokenized motion substrate and controller: \textbf{PartVQ} learns anatomy-aligned part codebooks, T-Concat exposes each frame--part token as an attention-addressable site, and KV-Control injects control-conditioned key/value memories at every self-attention layer while preserving the pretrained query stream, text cross-attention, FFN, and all backbone weights. The resulting adapter adds only trainable injection parameters atop a shared trajectory encoder, yet tracks root and multi-joint constraints with sub-centimeter accuracy under the inherited refinement protocol while retaining text-conditioned motion quality. KV-Control reframes trajectory conditioning as lightweight memory retrieval, providing a small, precise, and transparent control interface for text-to-motion generation.
AnchorRoute: Human Motion Synthesis with Interval-Routed Sparse Contro
May 14, 2026Sparse anchors provide a compact interface for human motion authoring: users specify a few root positions, planar trajectory samples, or body-point targets, while the system synthesizes the full-body motion that completes the under-specified intent. We present AnchorRoute, a sparse-anchor motion synthesis framework that uses anchors as a shared scaffold for both generation and refinement. Before generation, AnchorRoute converts sparse anchors into anchor-condition features and injects the resulting condition memory into a frozen Transition Masked Diffusion prior through AnchorKV and dual-context conditioning. This preserves the generation quality of the pretrained text-to-motion prior while learning sparse spatial control. After generation, the same anchors are evaluated as residuals: their timestamps define refinement intervals, and their residuals determine where correction should be concentrated. RouteSolver then refines the motion by projecting soft-token updates onto anchor-defined piecewise-affine interval bases. This couples generation-time anchor conditioning with residual-routed refinement under one anchor scaffold. AnchorRoute supports root-3D, planar-root, and body-point control within the same formulation. In benchmark evaluations, AnchorRoute outperforms prior sparse-control methods under the sparse keyjoint protocol and consistently improves anchor adherence across control families. The results show that the learned anchor-conditioned generator and RouteSolver refinement are complementary: the generator preserves text-motion quality, while RouteSolver provides a controllable path toward stronger anchor adherence.
UMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
May 14, 2026Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
BrepGaussian: CAD reconstruction from Multi-View Images with Gaussian Splatting
Feb 24, 2026The boundary representation (B-rep) models a 3D solid as its explicit boundaries: trimmed corners, edges, and faces. Recovering B-rep representation from unstructured data is a challenging and valuable task of computer vision and graphics. Recent advances in deep learning have greatly improved the recovery of 3D shape geometry, but still depend on dense and clean point clouds and struggle to generalize to novel shapes. We propose B-rep Gaussian Splatting (BrepGaussian), a novel framework that learns 3D parametric representations from 2D images. We employ a Gaussian Splatting renderer with learnable features, followed by a specific fitting strategy. To disentangle geometry reconstruction and feature learning, we introduce a two-stage learning framework that first captures geometry and edges and then refines patch features to achieve clean geometry and coherent instance representations. Extensive experiments demonstrate the superior performance of our approach to state-of-the-art methods. We will release our code and datasets upon acceptance.
Flatten The Complex: Joint B-Rep Generation via Compositional $k$-Cell Particles
Jan 25, 2026Boundary Representation (B-Rep) is the widely adopted standard in Computer-Aided Design (CAD) and manufacturing. However, generative modeling of B-Reps remains a formidable challenge due to their inherent heterogeneity as geometric cell complexes, which entangles topology with geometry across cells of varying orders (i.e., $k$-cells such as vertices, edges, faces). Previous methods typically rely on cascaded sequences to handle this hierarchy, which fails to fully exploit the geometric relationships between cells, such as adjacency and sharing, limiting context awareness and error recovery. To fill this gap, we introduce a novel paradigm that reformulates B-Reps into sets of compositional $k$-cell particles. Our approach encodes each topological entity as a composition of particles, where adjacent cells share identical latents at their interfaces, thereby promoting geometric coupling along shared boundaries. By decoupling the rigid hierarchy, our representation unifies vertices, edges, and faces, enabling the joint generation of topology and geometry with global context awareness. We synthesize these particle sets using a multi-modal flow matching framework to handle unconditional generation as well as precise conditional tasks, such as 3D reconstruction from single-view or point cloud. Furthermore, the explicit and localized nature of our representation naturally extends to downstream tasks like local in-painting and enables the direct synthesis of non-manifold structures (e.g., wireframes). Extensive experiments demonstrate that our method produces high-fidelity CAD models with superior validity and editability compared to state-of-the-art methods.
LoG3D: Ultra-High-Resolution 3D Shape Modeling via Local-to-Global Partitioning
Nov 18, 2025



Generating high-fidelity 3D contents remains a fundamental challenge due to the complexity of representing arbitrary topologies-such as open surfaces and intricate internal structures-while preserving geometric details. Prevailing methods based on signed distance fields (SDFs) are hampered by costly watertight preprocessing and struggle with non-manifold geometries, while point-cloud representations often suffer from sampling artifacts and surface discontinuities. To overcome these limitations, we propose a novel 3D variational autoencoder (VAE) framework built upon unsigned distance fields (UDFs)-a more robust and computationally efficient representation that naturally handles complex and incomplete shapes. Our core innovation is a local-to-global (LoG) architecture that processes the UDF by partitioning it into uniform subvolumes, termed UBlocks. This architecture couples 3D convolutions for capturing local detail with sparse transformers for enforcing global coherence. A Pad-Average strategy further ensures smooth transitions at subvolume boundaries during reconstruction. This modular design enables seamless scaling to ultra-high resolutions up to $2048^3$-a regime previously unattainable for 3D VAEs. Experiments demonstrate state-of-the-art performance in both reconstruction accuracy and generative quality, yielding superior surface smoothness and geometric flexibility.
StableIntrinsic: Detail-preserving One-step Diffusion Model for Multi-view Material Estimation
Aug 27, 2025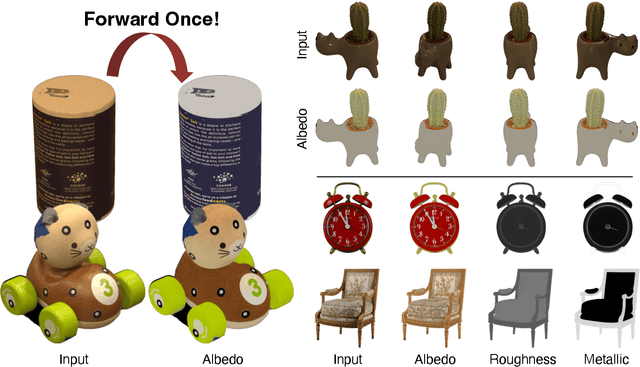



Recovering material information from images has been extensively studied in computer graphics and vision. Recent works in material estimation leverage diffusion model showing promising results. However, these diffusion-based methods adopt a multi-step denoising strategy, which is time-consuming for each estimation. Such stochastic inference also conflicts with the deterministic material estimation task, leading to a high variance estimated results. In this paper, we introduce StableIntrinsic, a one-step diffusion model for multi-view material estimation that can produce high-quality material parameters with low variance. To address the overly-smoothing problem in one-step diffusion, StableIntrinsic applies losses in pixel space, with each loss designed based on the properties of the material. Additionally, StableIntrinsic introduces a Detail Injection Network (DIN) to eliminate the detail loss caused by VAE encoding, while further enhancing the sharpness of material prediction results. The experimental results indicate that our method surpasses the current state-of-the-art techniques by achieving a $9.9\%$ improvement in the Peak Signal-to-Noise Ratio (PSNR) of albedo, and by reducing the Mean Square Error (MSE) for metallic and roughness by $44.4\%$ and $60.0\%$, respectively.
GaRe: Relightable 3D Gaussian Splatting for Outdoor Scenes from Unconstrained Photo Collections
Jul 28, 2025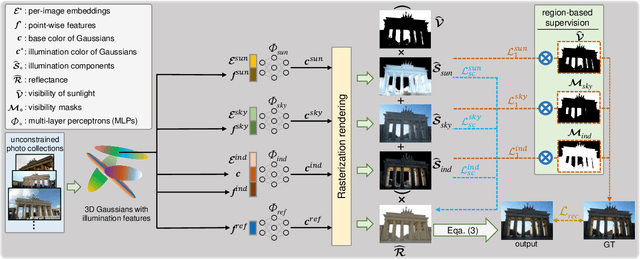

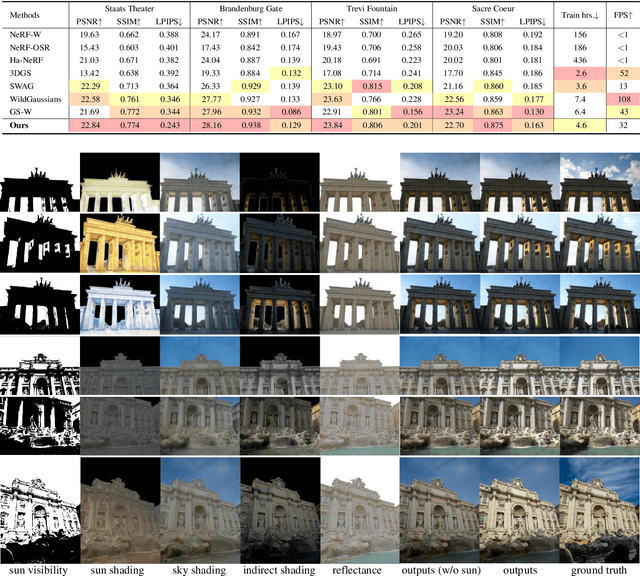

We propose a 3D Gaussian splatting-based framework for outdoor relighting that leverages intrinsic image decomposition to precisely integrate sunlight, sky radiance, and indirect lighting from unconstrained photo collections. Unlike prior methods that compress the per-image global illumination into a single latent vector, our approach enables simultaneously diverse shading manipulation and the generation of dynamic shadow effects. This is achieved through three key innovations: (1) a residual-based sun visibility extraction method to accurately separate direct sunlight effects, (2) a region-based supervision framework with a structural consistency loss for physically interpretable and coherent illumination decomposition, and (3) a ray-tracing-based technique for realistic shadow simulation. Extensive experiments demonstrate that our framework synthesizes novel views with competitive fidelity against state-of-the-art relighting solutions and produces more natural and multifaceted illumination and shadow effects.
Test-Time-Matching: Decouple Personality, Memory, and Linguistic Style in LLM-based Role-Playing Language Agent
Jul 23, 2025



The rapid advancement of large language models (LLMs) has enabled role-playing language agents to demonstrate significant potential in various applications. However, relying solely on prompts and contextual inputs often proves insufficient for achieving deep immersion in specific roles, particularly well-known fictional or public figures. On the other hand, fine-tuning-based approaches face limitations due to the challenges associated with data collection and the computational resources required for training, thereby restricting their broader applicability. To address these issues, we propose Test-Time-Matching (TTM), a training-free role-playing framework through test-time scaling and context engineering. TTM uses LLM agents to automatically decouple a character's features into personality, memory, and linguistic style. Our framework involves a structured, three-stage generation pipeline that utilizes these features for controlled role-playing. It achieves high-fidelity role-playing performance, also enables seamless combinations across diverse linguistic styles and even variations in personality and memory. We evaluate our framework through human assessment, and the results demonstrate that our method achieves the outstanding performance in generating expressive and stylistically consistent character dialogues.
TransparentGS: Fast Inverse Rendering of Transparent Objects with Gaussians
May 01, 2025



The emergence of neural and Gaussian-based radiance field methods has led to considerable advancements in novel view synthesis and 3D object reconstruction. Nonetheless, specular reflection and refraction continue to pose significant challenges due to the instability and incorrect overfitting of radiance fields to high-frequency light variations. Currently, even 3D Gaussian Splatting (3D-GS), as a powerful and efficient tool, falls short in recovering transparent objects with nearby contents due to the existence of apparent secondary ray effects. To address this issue, we propose TransparentGS, a fast inverse rendering pipeline for transparent objects based on 3D-GS. The main contributions are three-fold. Firstly, an efficient representation of transparent objects, transparent Gaussian primitives, is designed to enable specular refraction through a deferred refraction strategy. Secondly, we leverage Gaussian light field probes (GaussProbe) to encode both ambient light and nearby contents in a unified framework. Thirdly, a depth-based iterative probes query (IterQuery) algorithm is proposed to reduce the parallax errors in our probe-based framework. Experiments demonstrate the speed and accuracy of our approach in recovering transparent objects from complex environments, as well as several applications in computer graphics and vision.