 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Latents Know More Than They Say: Unsilencing Latent Reasoning in MLLMs
May 04, 2026Continuous latent-space reasoning offers a compact alternative to textual chain-of-thought for multimodal models, enabling high-dimensional visual evidence to be integrated without explicit reasoning tokens. However, we identify a previously overlooked optimization pathology in existing latent visual reasoning methods: although visual latents become semantically enriched during training, their contribution to final answer prediction is systematically suppressed. Within the shared parameter space, the autoregressive objective favors shortcut reliance on direct visual input, driving latent tokens toward transition-like states rather than informative reasoning content. We term this phenomenon Silenced Visual Latents. To address it, we disentangle the two conflicting objectives by directly optimizing the latent reasoning at inference time, keeping backbone parameters frozen. In Stage I, visual latents are warmed up via query-guided contrastive latent--visual alignment, improving semantic quality while preventing latent collapse. In Stage II, the latent reasoning is further optimized via a confidence-progression reward, which incentivizes predicted token distributions along the latent span to become progressively more concentrated, routing predictions through the latent reasoning rather than bypassing it. Experiments across eight benchmarks and four model backbones show that inference-time latent optimization, without any parameter updates, effectively unleashes the suppressed reasoning capacity of visual latents.
Prompt-Driven Lightweight Foundation Model for Instance Segmentation-Based Fault Detection in Freight Trains
Mar 13, 2026Accurate visual fault detection in freight trains remains a critical challenge for intelligent transportation system maintenance, due to complex operational environments, structurally repetitive components, and frequent occlusions or contaminations in safety-critical regions. Conventional instance segmentation methods based on convolutional neural networks and Transformers often suffer from poor generalization and limited boundary accuracy under such conditions. To address these challenges, we propose a lightweight self-prompted instance segmentation framework tailored for freight train fault detection. Our method leverages the Segment Anything Model by introducing a self-prompt generation module that automatically produces task-specific prompts, enabling effective knowledge transfer from foundation models to domain-specific inspection tasks. In addition, we adopt a Tiny Vision Transformer backbone to reduce computational cost, making the framework suitable for real-time deployment on edge devices in railway monitoring systems. We construct a domain-specific dataset collected from real-world freight inspection stations and conduct extensive evaluations. Experimental results show that our method achieves 74.6 $AP^{\text{box}}$ and 74.2 $AP^{\text{mask}}$ on the dataset, outperforming existing state-of-the-art methods in both accuracy and robustness while maintaining low computational overhead. This work offers a deployable and efficient vision solution for automated freight train inspection, demonstrating the potential of foundation model adaptation in industrial-scale fault diagnosis scenarios. Project page: https://github.com/MVME-HBUT/SAM_FTI-FDet.git
HAMMER: Harnessing MLLM via Cross-Modal Integration for Intention-Driven 3D Affordance Grounding
Mar 02, 2026Humans commonly identify 3D object affordance through observed interactions in images or videos, and once formed, such knowledge can be generically generalized to novel objects. Inspired by this principle, we advocate for a novel framework that leverages emerging multimodal large language models (MLLMs) for interaction intention-driven 3D affordance grounding, namely HAMMER. Instead of generating explicit object attribute descriptions or relying on off-the-shelf 2D segmenters, we alternatively aggregate the interaction intention depicted in the image into a contact-aware embedding and guide the model to infer textual affordance labels, ensuring it thoroughly excavates object semantics and contextual cues. We further devise a hierarchical cross-modal integration mechanism to fully exploit the complementary information from the MLLM for 3D representation refinement and introduce a multi-granular geometry lifting module that infuses spatial characteristics into the extracted intention embedding, thus facilitating accurate 3D affordance localization. Extensive experiments on public datasets and our newly constructed corrupted benchmark demonstrate the superiority and robustness of HAMMER compared to existing approaches. All code and weights are publicly available.
LaSSM: Efficient Semantic-Spatial Query Decoding via Local Aggregation and State Space Models for 3D Instance Segmentation
Feb 11, 2026Query-based 3D scene instance segmentation from point clouds has attained notable performance. However, existing methods suffer from the query initialization dilemma due to the sparse nature of point clouds and rely on computationally intensive attention mechanisms in query decoders. We accordingly introduce LaSSM, prioritizing simplicity and efficiency while maintaining competitive performance. Specifically, we propose a hierarchical semantic-spatial query initializer to derive the query set from superpoints by considering both semantic cues and spatial distribution, achieving comprehensive scene coverage and accelerated convergence. We further present a coordinate-guided state space model (SSM) decoder that progressively refines queries. The novel decoder features a local aggregation scheme that restricts the model to focus on geometrically coherent regions and a spatial dual-path SSM block to capture underlying dependencies within the query set by integrating associated coordinates information. Our design enables efficient instance prediction, avoiding the incorporation of noisy information and reducing redundant computation. LaSSM ranks first place on the latest ScanNet++ V2 leaderboard, outperforming the previous best method by 2.5% mAP with only 1/3 FLOPs, demonstrating its superiority in challenging large-scale scene instance segmentation. LaSSM also achieves competitive performance on ScanNet, ScanNet200, S3DIS and ScanNet++ V1 benchmarks with less computational cost. Extensive ablation studies and qualitative results validate the effectiveness of our design. The code and weights are available at https://github.com/RayYoh/LaSSM.
SGIFormer: Semantic-guided and Geometric-enhanced Interleaving Transformer for 3D Instance Segmentation
Jul 16, 2024In recent years, transformer-based models have exhibited considerable potential in point cloud instance segmentation. Despite the promising performance achieved by existing methods, they encounter challenges such as instance query initialization problems and excessive reliance on stacked layers, rendering them incompatible with large-scale 3D scenes. This paper introduces a novel method, named SGIFormer, for 3D instance segmentation, which is composed of the Semantic-guided Mix Query (SMQ) initialization and the Geometric-enhanced Interleaving Transformer (GIT) decoder. Specifically, the principle of our SMQ initialization scheme is to leverage the predicted voxel-wise semantic information to implicitly generate the scene-aware query, yielding adequate scene prior and compensating for the learnable query set. Subsequently, we feed the formed overall query into our GIT decoder to alternately refine instance query and global scene features for further capturing fine-grained information and reducing complex design intricacies simultaneously. To emphasize geometric property, we consider bias estimation as an auxiliary task and progressively integrate shifted point coordinates embedding to reinforce instance localization. SGIFormer attains state-of-the-art performance on ScanNet V2, ScanNet200 datasets, and the challenging high-fidelity ScanNet++ benchmark, striking a balance between accuracy and efficiency. The code, weights, and demo videos are publicly available at https://rayyoh.github.io/sgiformer.
Multiple Prior Representation Learning for Self-Supervised Monocular Depth Estimation via Hybrid Transformer
Jun 13, 2024



Self-supervised monocular depth estimation aims to infer depth information without relying on labeled data. However, the lack of labeled information poses a significant challenge to the model's representation, limiting its ability to capture the intricate details of the scene accurately. Prior information can potentially mitigate this issue, enhancing the model's understanding of scene structure and texture. Nevertheless, solely relying on a single type of prior information often falls short when dealing with complex scenes, necessitating improvements in generalization performance. To address these challenges, we introduce a novel self-supervised monocular depth estimation model that leverages multiple priors to bolster representation capabilities across spatial, context, and semantic dimensions. Specifically, we employ a hybrid transformer and a lightweight pose network to obtain long-range spatial priors in the spatial dimension. Then, the context prior attention is designed to improve generalization, particularly in complex structures or untextured areas. In addition, semantic priors are introduced by leveraging semantic boundary loss, and semantic prior attention is supplemented, further refining the semantic features extracted by the decoder. Experiments on three diverse datasets demonstrate the effectiveness of the proposed model. It integrates multiple priors to comprehensively enhance the representation ability, improving the accuracy and reliability of depth estimation. Codes are available at: \url{https://github.com/MVME-HBUT/MPRLNet}
A Concise but Effective Network for Image Guided Depth Completion in Autonomous Driving
Jan 29, 2024



Depth completion is a crucial task in autonomous driving, aiming to convert a sparse depth map into a dense depth prediction. Due to its potentially rich semantic information, RGB image is commonly fused to enhance the completion effect. Image-guided depth completion involves three key challenges: 1) how to effectively fuse the two modalities; 2) how to better recover depth information; and 3) how to achieve real-time prediction for practical autonomous driving. To solve the above problems, we propose a concise but effective network, named CENet, to achieve high-performance depth completion with a simple and elegant structure. Firstly, we use a fast guidance module to fuse the two sensor features, utilizing abundant auxiliary features extracted from the color space. Unlike other commonly used complicated guidance modules, our approach is intuitive and low-cost. In addition, we find and analyze the optimization inconsistency problem for observed and unobserved positions, and a decoupled depth prediction head is proposed to alleviate the issue. The proposed decoupled head can better output the depth of valid and invalid positions with very few extra inference time. Based on the simple structure of dual-encoder and single-decoder, our CENet can achieve superior balance between accuracy and efficiency. In the KITTI depth completion benchmark, our CENet attains competitive performance and inference speed compared with the state-of-the-art methods. To validate the generalization of our method, we also evaluate on indoor NYUv2 dataset, and our CENet still achieve impressive results. The code of this work will be available at https://github.com/lmomoy/CENet.
GEM: Boost Simple Network for Glass Surface Segmentation via Segment Anything Model and Data Synthesis
Jan 27, 2024Detecting glass regions is a challenging task due to the ambiguity of their transparency and reflection properties. These transparent glasses share the visual appearance of both transmitted arbitrary background scenes and reflected objects, thus having no fixed patterns.Recent visual foundation models, which are trained on vast amounts of data, have manifested stunning performance in terms of image perception and image generation. To segment glass surfaces with higher accuracy, we make full use of two visual foundation models: Segment Anything (SAM) and Stable Diffusion.Specifically, we devise a simple glass surface segmentor named GEM, which only consists of a SAM backbone, a simple feature pyramid, a discerning query selection module, and a mask decoder. The discerning query selection can adaptively identify glass surface features, assigning them as initialized queries in the mask decoder. We also propose a Synthetic but photorealistic large-scale Glass Surface Detection dataset dubbed S-GSD via diffusion model with four different scales, which contain 1x, 5x, 10x, and 20x of the original real data size. This dataset is a feasible source for transfer learning. The scale of synthetic data has positive impacts on transfer learning, while the improvement will gradually saturate as the amount of data increases. Extensive experiments demonstrate that GEM achieves a new state-of-the-art on the GSD-S validation set (IoU +2.1%). Codes and datasets are available at: https://github.com/isbrycee/GEM-Glass-Segmentor.
A Stronger Stitching Algorithm for Fisheye Images based on Deblurring and Registration
Jul 22, 2023Fisheye lens, which is suitable for panoramic imaging, has the prominent advantage of a large field of view and low cost. However, the fisheye image has a severe geometric distortion which may interfere with the stage of image registration and stitching. Aiming to resolve this drawback, we devise a stronger stitching algorithm for fisheye images by combining the traditional image processing method with deep learning. In the stage of fisheye image correction, we propose the Attention-based Nonlinear Activation Free Network (ANAFNet) to deblur fisheye images corrected by Zhang calibration method. Specifically, ANAFNet adopts the classical single-stage U-shaped architecture based on convolutional neural networks with soft-attention technique and it can restore a sharp image from a blurred image effectively. In the part of image registration, we propose the ORB-FREAK-GMS (OFG), a comprehensive image matching algorithm, to improve the accuracy of image registration. Experimental results demonstrate that panoramic images of superior quality stitching by fisheye images can be obtained through our method.
LF-YOLO: A Lighter and Faster YOLO for Weld Defect Detection of X-ray Image
Nov 18, 2021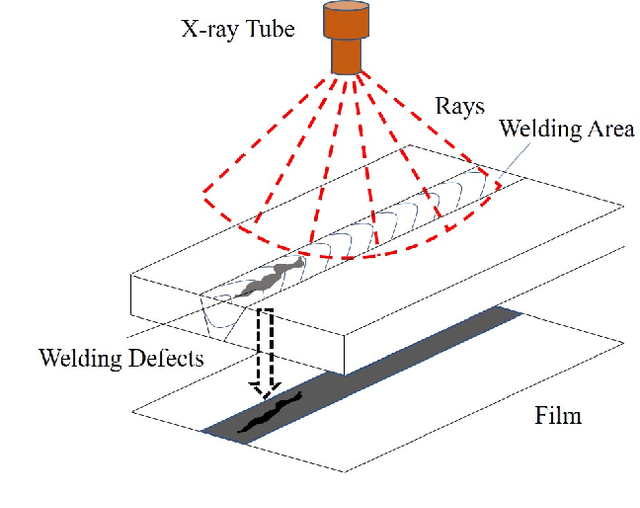

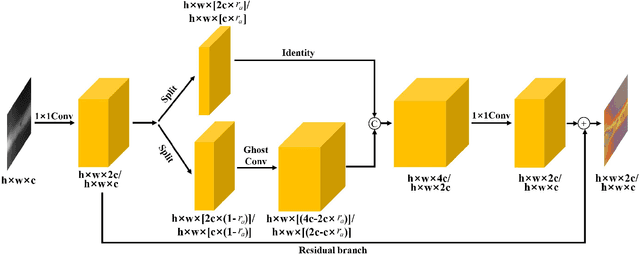
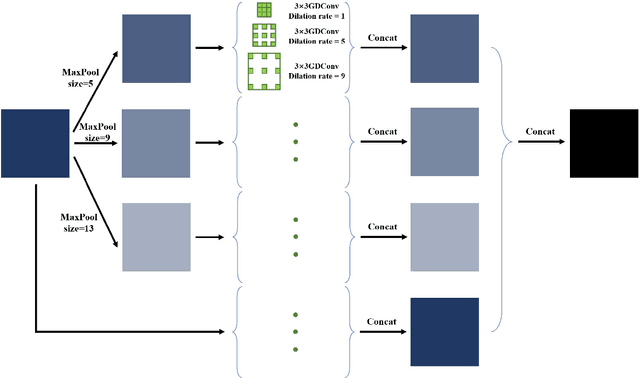
X-ray image plays an important role in manufacturing industry for quality assurance, because it can reflect the internal condition of weld region. However, the shape and scale of different defect types vary greatly, which makes it challenging for model to detect weld defects. In this paper, we propose a weld defect detection method based on convolution neural network, namely Lighter and Faster YOLO (LF-YOLO). In particularly, a reinforced multiscale feature (RMF) module is designed to implement both parameter-based and parameter-free multi-scale information extracting operation. RMF enables the extracted feature map capable to represent more plentiful information, which is achieved by superior hierarchical fusion structure. To improve the performance of detection network, we propose an efficient feature extraction (EFE) module. EFE processes input data with extremely low consumption, and improves the practicability of whole network in actual industry. Experimental results show that our weld defect detection network achieves satisfactory balance between performance and consumption, and reaches 92.9 mean average precision mAP50 with 61.5 frames per second (FPS). To further prove the ability of our method, we test it on public dataset MS COCO, and the results show that our LF-YOLO has a outstanding versatility detection performance. The code is available at https://github.com/lmomoy/LF-YOLO.