 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Source Visual and Target Language Domains for Unpaired Video Captioning
Nov 22, 2022Training supervised video captioning model requires coupled video-caption pairs. However, for many targeted languages, sufficient paired data are not available. To this end, we introduce the unpaired video captioning task aiming to train models without coupled video-caption pairs in target language. To solve the task, a natural choice is to employ a two-step pipeline system: first utilizing video-to-pivot captioning model to generate captions in pivot language and then utilizing pivot-to-target translation model to translate the pivot captions to the target language. However, in such a pipeline system, 1) visual information cannot reach the translation model, generating visual irrelevant target captions; 2) the errors in the generated pivot captions will be propagated to the translation model, resulting in disfluent target captions. To address these problems, we propose the Unpaired Video Captioning with Visual Injection system (UVC-VI). UVC-VI first introduces the Visual Injection Module (VIM), which aligns source visual and target language domains to inject the source visual information into the target language domain. Meanwhile, VIM directly connects the encoder of the video-to-pivot model and the decoder of the pivot-to-target model, allowing end-to-end inference by completely skipping the generation of pivot captions. To enhance the cross-modality injection of the VIM, UVC-VI further introduces a pluggable video encoder, i.e., Multimodal Collaborative Encoder (MCE). The experiments show that UVC-VI outperforms pipeline systems and exceeds several supervised systems. Furthermore, equipping existing supervised systems with our MCE can achieve 4% and 7% relative margins on the CIDEr scores to current state-of-the-art models on the benchmark MSVD and MSR-VTT datasets, respectively.
Expectation-Maximization Contrastive Learning for Compact Video-and-Language Representations
Nov 21, 2022Most video-and-language representation learning approaches employ contrastive learning, e.g., CLIP, to project the video and text features into a common latent space according to the semantic similarities of text-video pairs. However, such learned shared latent spaces are not often optimal, and the modality gap between visual and textual representation can not be fully eliminated. In this paper, we propose Expectation-Maximization Contrastive Learning (EMCL) to learn compact video-and-language representations. Specifically, we use the Expectation-Maximization algorithm to find a compact set of bases for the latent space, where the features could be concisely represented as the linear combinations of these bases. Such feature decomposition of video-and-language representations reduces the rank of the latent space, resulting in increased representing power for the semantics. Extensive experiments on three benchmark text-video retrieval datasets prove that our EMCL can learn more discriminative video-and-language representations than previous methods, and significantly outperform previous state-of-the-art methods across all metrics. More encouragingly, the proposed method can be applied to boost the performance of existing approaches either as a jointly training layer or an out-of-the-box inference module with no extra training, making it easy to be incorporated into any existing methods.
DiMBERT: Learning Vision-Language Grounded Representations with Disentangled Multimodal-Attention
Oct 28, 2022



Vision-and-language (V-L) tasks require the system to understand both vision content and natural language, thus learning fine-grained joint representations of vision and language (a.k.a. V-L representations) is of paramount importance. Recently, various pre-trained V-L models are proposed to learn V-L representations and achieve improved results in many tasks. However, the mainstream models process both vision and language inputs with the same set of attention matrices. As a result, the generated V-L representations are entangled in one common latent space. To tackle this problem, we propose DiMBERT (short for Disentangled Multimodal-Attention BERT), which is a novel framework that applies separated attention spaces for vision and language, and the representations of multi-modalities can thus be disentangled explicitly. To enhance the correlation between vision and language in disentangled spaces, we introduce the visual concepts to DiMBERT which represent visual information in textual format. In this manner, visual concepts help to bridge the gap between the two modalities. We pre-train DiMBERT on a large amount of image-sentence pairs on two tasks: bidirectional language modeling and sequence-to-sequence language modeling. After pre-train, DiMBERT is further fine-tuned for the downstream tasks. Experiments show that DiMBERT sets new state-of-the-art performance on three tasks (over four datasets), including both generation tasks (image captioning and visual storytelling) and classification tasks (referring expressions). The proposed DiM (short for Disentangled Multimodal-Attention) module can be easily incorporated into existing pre-trained V-L models to boost their performance, up to a 5% increase on the representative task. Finally, we conduct a systematic analysis and demonstrate the effectiveness of our DiM and the introduced visual concepts.
Retrieve, Reason, and Refine: Generating Accurate and Faithful Patient Instructions
Oct 23, 2022



The "Patient Instruction" (PI), which contains critical instructional information provided both to carers and to the patient at the time of discharge, is essential for the patient to manage their condition outside hospital. An accurate and easy-to-follow PI can improve the self-management of patients which can in turn reduce hospital readmission rates. However, writing an appropriate PI can be extremely time-consuming for physicians, and is subject to being incomplete or error-prone for (potentially overworked) physicians. Therefore, we propose a new task that can provide an objective means of avoiding incompleteness, while reducing clinical workload: the automatic generation of the PI, which is imagined as being a document that the clinician can review, modify, and approve as necessary (rather than taking the human "out of the loop"). We build a benchmark clinical dataset and propose the Re3Writer, which imitates the working patterns of physicians to first retrieve related working experience from historical PIs written by physicians, then reason related medical knowledge. Finally, it refines the retrieved working experience and reasoned medical knowledge to extract useful information, which is used to generate the PI for previously-unseen patient according to their health records during hospitalization. Our experiments show that, using our method, the performance of five different models can be substantially boosted across all metrics, with up to 20%, 11%, and 19% relative improvements in BLEU-4, ROUGE-L, and METEOR, respectively. Meanwhile, we show results from human evaluations to measure the effectiveness in terms of its usefulness for clinical practice. The code is available at https://github.com/AI-in-Hospitals/Patient-Instructions
Competence-based Multimodal Curriculum Learning for Medical Report Generation
Jun 24, 2022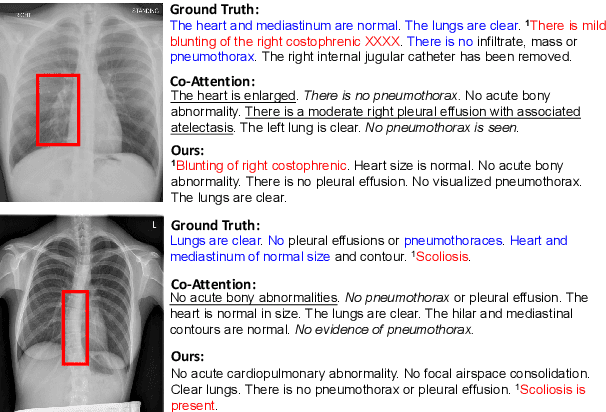
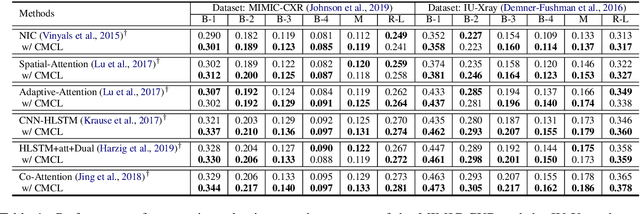
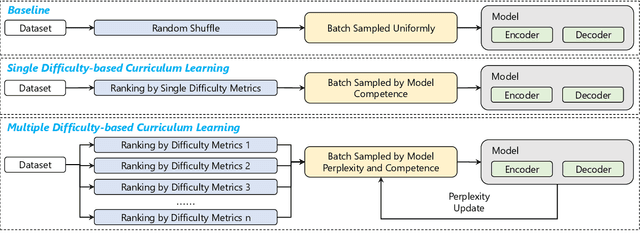
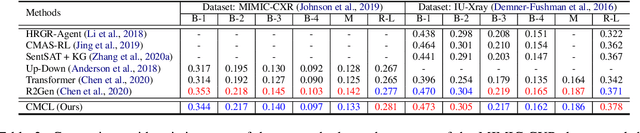
Medical report generation task, which targets to produce long and coherent descriptions of medical images, has attracted growing research interests recently. Different from the general image captioning tasks, medical report generation is more challenging for data-driven neural models. This is mainly due to 1) the serious data bias and 2) the limited medical data. To alleviate the data bias and make best use of available data, we propose a Competence-based Multimodal Curriculum Learning framework (CMCL). Specifically, CMCL simulates the learning process of radiologists and optimizes the model in a step by step manner. Firstly, CMCL estimates the difficulty of each training instance and evaluates the competence of current model; Secondly, CMCL selects the most suitable batch of training instances considering current model competence. By iterating above two steps, CMCL can gradually improve the model's performance. The experiments on the public IU-Xray and MIMIC-CXR datasets show that CMCL can be incorporated into existing models to improve their performance.
Graph-in-Graph Network for Automatic Gene Ontology Description Generation
Jun 10, 2022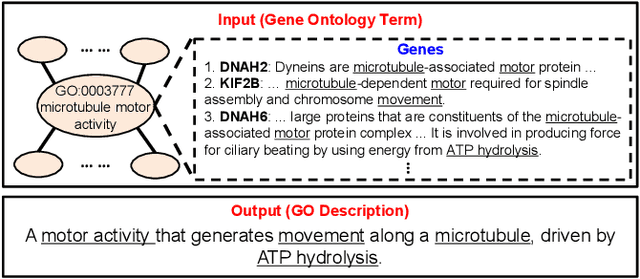
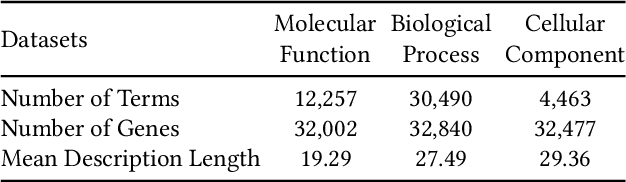
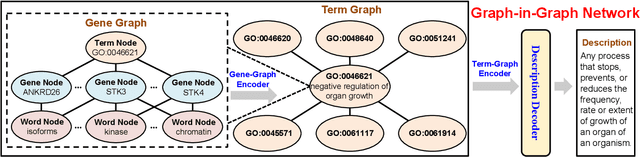
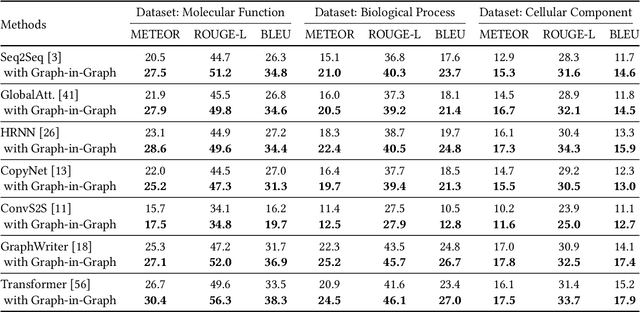
Gene Ontology (GO) is the primary gene function knowledge base that enables computational tasks in biomedicine. The basic element of GO is a term, which includes a set of genes with the same function. Existing research efforts of GO mainly focus on predicting gene term associations. Other tasks, such as generating descriptions of new terms, are rarely pursued. In this paper, we propose a novel task: GO term description generation. This task aims to automatically generate a sentence that describes the function of a GO term belonging to one of the three categories, i.e., molecular function, biological process, and cellular component. To address this task, we propose a Graph-in-Graph network that can efficiently leverage the structural information of GO. The proposed network introduces a two-layer graph: the first layer is a graph of GO terms where each node is also a graph (gene graph). Such a Graph-in-Graph network can derive the biological functions of GO terms and generate proper descriptions. To validate the effectiveness of the proposed network, we build three large-scale benchmark datasets. By incorporating the proposed Graph-in-Graph network, the performances of seven different sequence-to-sequence models can be substantially boosted across all evaluation metrics, with up to 34.7%, 14.5%, and 39.1% relative improvements in BLEU, ROUGE-L, and METEOR, respectively.
End-to-end Spoken Conversational Question Answering: Task, Dataset and Model
Apr 29, 2022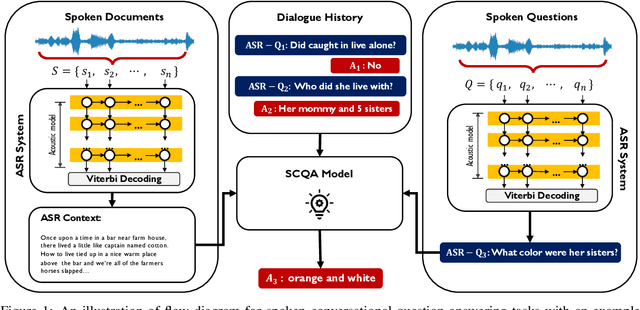

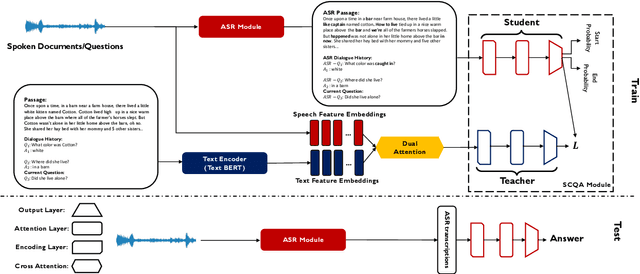

In spoken question answering, the systems are designed to answer questions from contiguous text spans within the related speech transcripts. However, the most natural way that human seek or test their knowledge is via human conversations. Therefore, we propose a new Spoken Conversational Question Answering task (SCQA), aiming at enabling the systems to model complex dialogue flows given the speech documents. In this task, our main objective is to build the system to deal with conversational questions based on the audio recordings, and to explore the plausibility of providing more cues from different modalities with systems in information gathering. To this end, instead of directly adopting automatically generated speech transcripts with highly noisy data, we propose a novel unified data distillation approach, DDNet, which effectively ingests cross-modal information to achieve fine-grained representations of the speech and language modalities. Moreover, we propose a simple and novel mechanism, termed Dual Attention, by encouraging better alignments between audio and text to ease the process of knowledge transfer. To evaluate the capacity of SCQA systems in a dialogue-style interaction, we assemble a Spoken Conversational Question Answering (Spoken-CoQA) dataset with more than 40k question-answer pairs from 4k conversations. The performance of the existing state-of-the-art methods significantly degrade on our dataset, hence demonstrating the necessity of cross-modal information integration. Our experimental results demonstrate that our proposed method achieves superior performance in spoken conversational question answering tasks.
Hazard Detection And Avoidance For The Nova-C Lander
Apr 01, 2022
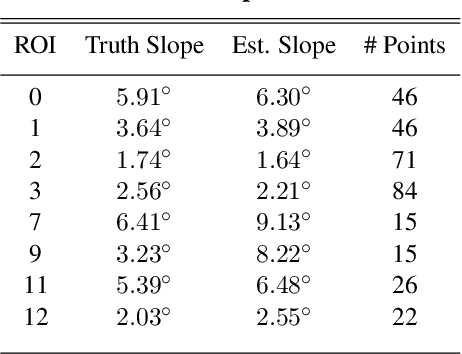


In early 2022, Intuitive Machines' NOVA-C Lander will touch down on the lunar surface becoming the first commercial endeavor to visit a celestial body. NOVA-C will deliver six payloads to the lunar surface with various scientific and engineering objectives, ushering in a new era of commercial space exploration and utilization. However, to safely accomplish the mission, the NOVA-C lander must ensure its landing site is free of hazards larger than 30 cm and the slope of local terrain at touchdown is less than 10 degrees off vertical. To accomplish this, NOVA-C utilizes Intuitive Machines' precision navigation system, coupled with machine vision algorithms for scene reduction and landing site characterization. A unique aspect to the NOVA-C approach is the real-time nature of the hazard detection and avoidance algorithms--which are performed 400 meters above and down range of the intended landing site and completed within 15 seconds. In this paper, we review the theoretical foundations for the hazard detection and avoidance algorithms, describe the practical challenges of implementation on the NOVA-C flight computer, and present test and analysis results.
AlignTransformer: Hierarchical Alignment of Visual Regions and Disease Tags for Medical Report Generation
Mar 18, 2022
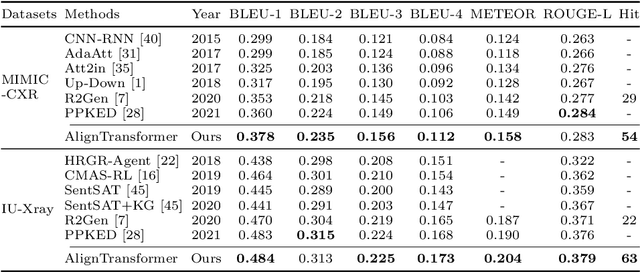
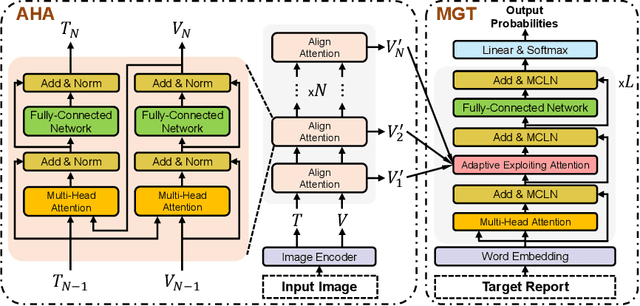
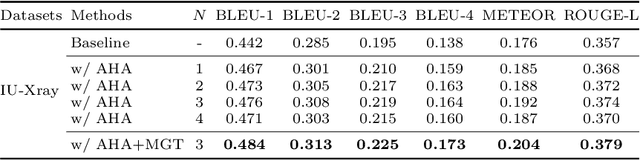
Recently, medical report generation, which aims to automatically generate a long and coherent descriptive paragraph of a given medical image, has received growing research interests. Different from the general image captioning tasks, medical report generation is more challenging for data-driven neural models. This is mainly due to 1) the serious data bias: the normal visual regions dominate the dataset over the abnormal visual regions, and 2) the very long sequence. To alleviate above two problems, we propose an AlignTransformer framework, which includes the Align Hierarchical Attention (AHA) and the Multi-Grained Transformer (MGT) modules: 1) AHA module first predicts the disease tags from the input image and then learns the multi-grained visual features by hierarchically aligning the visual regions and disease tags. The acquired disease-grounded visual features can better represent the abnormal regions of the input image, which could alleviate data bias problem; 2) MGT module effectively uses the multi-grained features and Transformer framework to generate the long medical report. The experiments on the public IU-Xray and MIMIC-CXR datasets show that the AlignTransformer can achieve results competitive with state-of-the-art methods on the two datasets. Moreover, the human evaluation conducted by professional radiologists further proves the effectiveness of our approach.
Radiology Report Generation with a Learned Knowledge Base and Multi-modal Alignment
Dec 30, 2021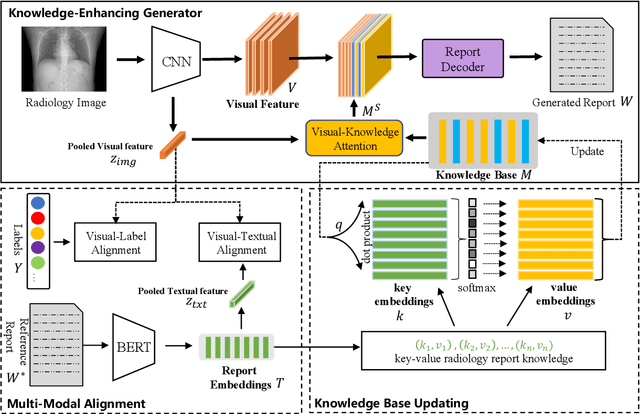
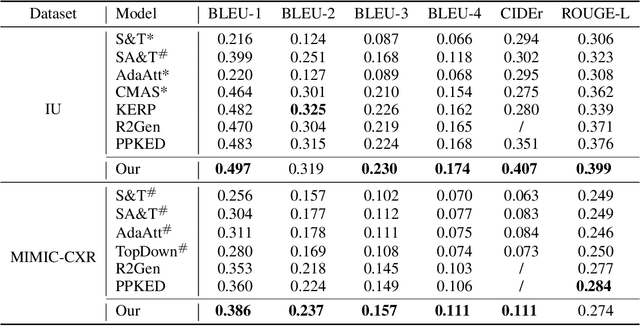
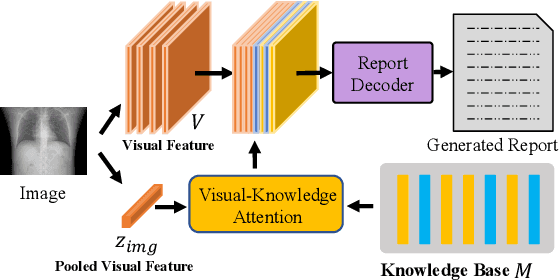
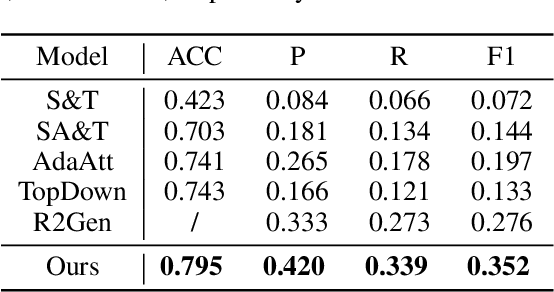
In clinics, a radiology report is crucial for guiding a patient's treatment. Unfortunately, report writing imposes a heavy burden on radiologists. To effectively reduce such a burden, we hereby present an automatic, multi-modal approach for report generation from chest x-ray. Our approach, motivated by the observation that the descriptions in radiology reports are highly correlated with the x-ray images, features two distinct modules: (i) Learned knowledge base. To absorb the knowledge embedded in the above-mentioned correlation, we automatically build a knowledge base based on textual embedding. (ii) Multi-modal alignment. To promote the semantic alignment among reports, disease labels and images, we explicitly utilize textual embedding to guide the learning of the visual feature space. We evaluate the performance of the proposed model using metrics from both natural language generation and clinic efficacy on the public IU and MIMIC-CXR datasets. Our ablation study shows that each module contributes to improving the quality of generated reports. Furthermore, with the aid of both modules, our approach clearly outperforms state-of-the-art methods.