 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Tokens: A Systematic Study of Latent Action Supervision for Vision-Language-Action Models
May 06, 2026Latent actions serve as an intermediate representation that enables consistent modeling of vision-language-action (VLA) models across heterogeneous datasets. However, approaches to supervising VLAs with latent actions are fragmented and lack a systematic comparison. This work structures the study of latent action supervision from two perspectives: (i) regularizing the trajectory via image-based latent actions, and (ii) unifying the target space with action-based latent actions. Under a unified VLA baseline, we instantiate and compare four representative integration strategies. Our results reveal a formulation-task correspondence: image-based latent actions benefit long-horizon reasoning and scene-level generalization, whereas action-based latent actions excel at complex motor coordination. Furthermore, we find that directly supervising the VLM with discrete latent action tokens yields the most effective performance. Finally, our experiments offer initial insights into the benefits of latent action supervision in mixed-data, suggesting a promising direction for VLA training. Code is available at https://github.com/RUCKBReasoning/From_Pixels_to_Tokens.
Spatio-Temporal Difference Guided Motion Deblurring with the Complementary Vision Sensor
Apr 12, 2026Motion blur arises when rapid scene changes occur during the exposure period, collapsing rich intra-exposure motion into a single RGB frame. Without explicit structural or temporal cues, RGB-only deblurring is highly ill-posed and often fails under extreme motion. Inspired by the human visual system, brain-inspired vision sensors introduce temporally dense information to alleviate this problem. However, event cameras still suffer from event rate saturation under rapid motion, while the event modality entangles edge features and motion cues, which limits their effectiveness. As a recent breakthrough, the complementary vision sensor (CVS), Tianmouc, captures synchronized RGB frames together with high-frame-rate, multi-bit spatial difference (SD, encoding structural edges) and temporal difference (TD, encoding motion cues) data within a single RGB exposure, offering a promising solution for RGB deblurring under extreme dynamic scenes. To fully leverage these complementary modalities, we propose Spatio-Temporal Difference Guided Deblur Net (STGDNet), which adopts a recurrent multi-branch architecture that iteratively encodes and fuses SD and TD sequences to restore structure and color details lost in blurry RGB inputs. Our method outperforms current RGB or event-based approaches in both synthetic CVS dataset and real-world evaluations. Moreover, STGDNet exhibits strong generalization capability across over 100 extreme real-world scenarios. Project page: https://tmcDeblur.github.io/
Advancing LLM-Based Security Automation with Customized Group Relative Policy Optimization for Zero-Touch Networks
Dec 10, 2025Zero-Touch Networks (ZTNs) represent a transformative paradigm toward fully automated and intelligent network management, providing the scalability and adaptability required for the complexity of sixth-generation (6G) networks. However, the distributed architecture, high openness, and deep heterogeneity of 6G networks expand the attack surface and pose unprecedented security challenges. To address this, security automation aims to enable intelligent security management across dynamic and complex environments, serving as a key capability for securing 6G ZTNs. Despite its promise, implementing security automation in 6G ZTNs presents two primary challenges: 1) automating the lifecycle from security strategy generation to validation and update under real-world, parallel, and adversarial conditions, and 2) adapting security strategies to evolving threats and dynamic environments. This motivates us to propose SecLoop and SA-GRPO. SecLoop constitutes the first fully automated framework that integrates large language models (LLMs) across the entire lifecycle of security strategy generation, orchestration, response, and feedback, enabling intelligent and adaptive defenses in dynamic network environments, thus tackling the first challenge. Furthermore, we propose SA-GRPO, a novel security-aware group relative policy optimization algorithm that iteratively refines security strategies by contrasting group feedback collected from parallel SecLoop executions, thereby addressing the second challenge. Extensive real-world experiments on five benchmarks, including 11 MITRE ATT&CK processes and over 20 types of attacks, demonstrate the superiority of the proposed SecLoop and SA-GRPO. We will release our platform to the community, facilitating the advancement of security automation towards next generation communications.
Quantitative evaluation of brain-inspired vision sensors in high-speed robotic perception
Apr 27, 2025Perception systems in robotics encounter significant challenges in high-speed and dynamic conditions when relying on traditional cameras, where motion blur can compromise spatial feature integrity and task performance. Brain-inspired vision sensors (BVS) have recently gained attention as an alternative, offering high temporal resolution with reduced bandwidth and power requirements. Here, we present the first quantitative evaluation framework for two representative classes of BVSs in variable-speed robotic sensing, including event-based vision sensors (EVS) that detect asynchronous temporal contrasts, and the primitive-based sensor Tianmouc that employs a complementary mechanism to encode both spatiotemporal changes and intensity. A unified testing protocol is established, including crosssensor calibrations, standardized testing platforms, and quality metrics to address differences in data modality. From an imaging standpoint, we evaluate the effects of sensor non-idealities, such as motion-induced distortion, on the capture of structural information. For functional benchmarking, we examine task performance in corner detection and motion estimation under different rotational speeds. Results indicate that EVS performs well in highspeed, sparse scenarios and in modestly fast, complex scenes, but exhibits performance limitations in high-speed, cluttered settings due to pixel-level bandwidth variations and event rate saturation. In comparison, Tianmouc demonstrates consistent performance across sparse and complex scenarios at various speeds, supported by its global, precise, high-speed spatiotemporal gradient samplings. These findings offer valuable insights into the applicationdependent suitability of BVS technologies and support further advancement in this area.
A Case Study Exploring the Current Landscape of Synthetic Medical Record Generation with Commercial LLMs
Apr 20, 2025Synthetic Electronic Health Records (EHRs) offer a valuable opportunity to create privacy preserving and harmonized structured data, supporting numerous applications in healthcare. Key benefits of synthetic data include precise control over the data schema, improved fairness and representation of patient populations, and the ability to share datasets without concerns about compromising real individuals privacy. Consequently, the AI community has increasingly turned to Large Language Models (LLMs) to generate synthetic data across various domains. However, a significant challenge in healthcare is ensuring that synthetic health records reliably generalize across different hospitals, a long standing issue in the field. In this work, we evaluate the current state of commercial LLMs for generating synthetic data and investigate multiple aspects of the generation process to identify areas where these models excel and where they fall short. Our main finding from this work is that while LLMs can reliably generate synthetic health records for smaller subsets of features, they struggle to preserve realistic distributions and correlations as the dimensionality of the data increases, ultimately limiting their ability to generalize across diverse hospital settings.
Technical report of a DMD-based Characterization Method for Vision Sensors
Mar 04, 2025

This technical report presents a novel DMD-based characterization method for vision sensors, particularly neuromorphic sensors such as event-based vision sensors (EVS) and Tianmouc, a complementary vision sensor. Traditional image sensor characterization standards, such as EMVA1288, are unsuitable for BVS due to their dynamic response characteristics. To address this, we propose a high-speed, high-precision testing system using a Digital Micromirror Device (DMD) to modulate spatial and temporal light intensity. This approach enables quantitative analysis of key parameters such as event latency, signal-to-noise ratio (SNR), and dynamic range (DR) under controlled conditions. Our method provides a standardized and reproducible testing framework, overcoming the limitations of existing evaluation techniques for neuromorphic sensors. Furthermore, we discuss the potential of this method for large-scale BVS dataset generation and conversion, paving the way for more consistent benchmarking of bio-inspired vision technologies.
MMBind: Unleashing the Potential of Distributed and Heterogeneous Data for Multimodal Learning in IoT
Nov 18, 2024



Multimodal sensing systems are increasingly prevalent in various real-world applications. Most existing multimodal learning approaches heavily rely on training with a large amount of complete multimodal data. However, such a setting is impractical in real-world IoT sensing applications where data is typically collected by distributed nodes with heterogeneous data modalities, and is also rarely labeled. In this paper, we propose MMBind, a new framework for multimodal learning on distributed and heterogeneous IoT data. The key idea of MMBind is to construct a pseudo-paired multimodal dataset for model training by binding data from disparate sources and incomplete modalities through a sufficiently descriptive shared modality. We demonstrate that data of different modalities observing similar events, even captured at different times and locations, can be effectively used for multimodal training. Moreover, we propose an adaptive multimodal learning architecture capable of training models with heterogeneous modality combinations, coupled with a weighted contrastive learning approach to handle domain shifts among disparate data. Evaluations on ten real-world multimodal datasets highlight that MMBind outperforms state-of-the-art baselines under varying data incompleteness and domain shift, and holds promise for advancing multimodal foundation model training in IoT applications.
CycleGAN with Better Cycles
Aug 27, 2024CycleGAN provides a framework to train image-to-image translation with unpaired datasets using cycle consistency loss [4]. While results are great in many applications, the pixel level cycle consistency can potentially be problematic and causes unrealistic images in certain cases. In this project, we propose three simple modifications to cycle consistency, and show that such an approach achieves better results with fewer artifacts.
Rethinking Pretraining as a Bridge from ANNs to SNNs
Mar 04, 2022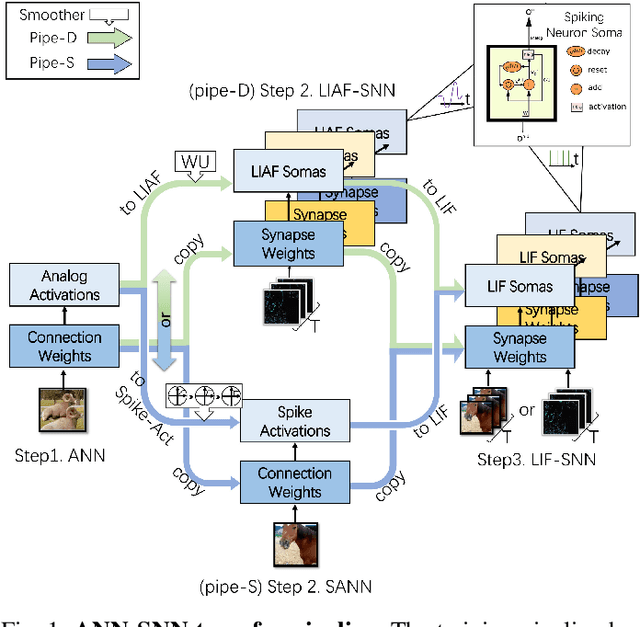
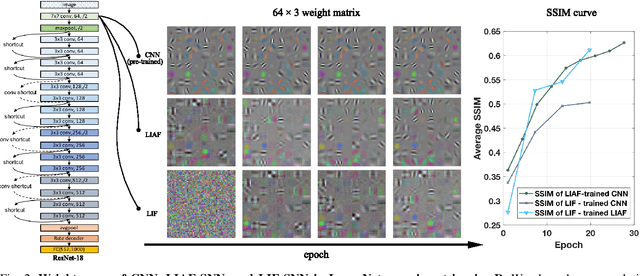
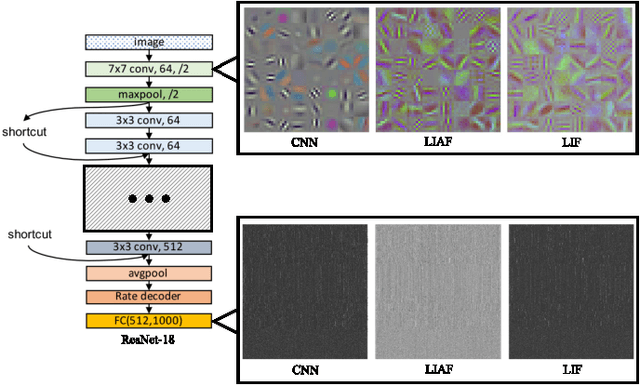
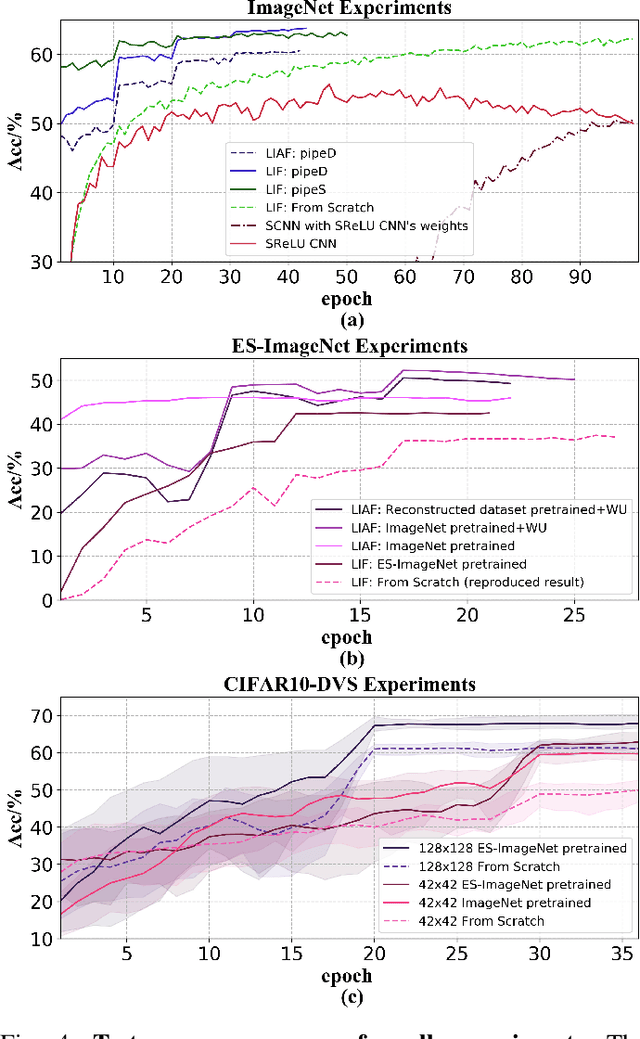
Spiking neural networks (SNNs) are known as a typical kind of brain-inspired models with their unique features of rich neuronal dynamics, diverse coding schemes and low power consumption properties. How to obtain a high-accuracy model has always been the main challenge in the field of SNN. Currently, there are two mainstream methods, i.e., obtaining a converted SNN through converting a well-trained Artificial Neural Network (ANN) to its SNN counterpart or training an SNN directly. However, the inference time of a converted SNN is too long, while SNN training is generally very costly and inefficient. In this work, a new SNN training paradigm is proposed by combining the concepts of the two different training methods with the help of the pretrain technique and BP-based deep SNN training mechanism. We believe that the proposed paradigm is a more efficient pipeline for training SNNs. The pipeline includes pipeS for static data transfer tasks and pipeD for dynamic data transfer tasks. SOTA results are obtained in a large-scale event-driven dataset ES-ImageNet. For training acceleration, we achieve the same (or higher) best accuracy as similar LIF-SNNs using 1/10 training time on ImageNet-1K and 2/5 training time on ES-ImageNet and also provide a time-accuracy benchmark for a new dataset ES-UCF101. These experimental results reveal the similarity of the functions of parameters between ANNs and SNNs and also demonstrate the various potential applications of this SNN training pipeline.
ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks
Oct 23, 2021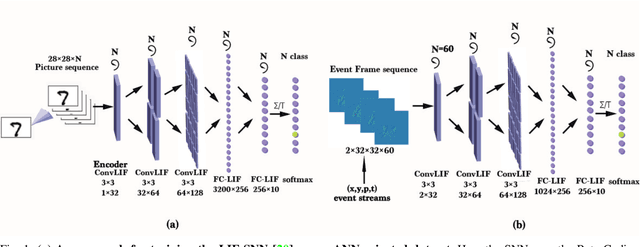
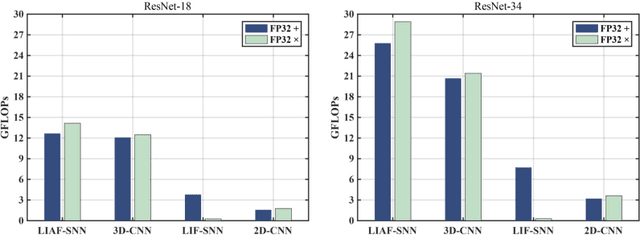
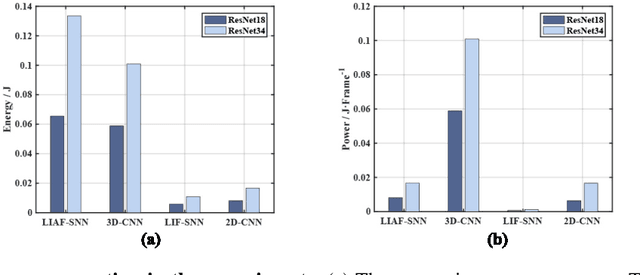
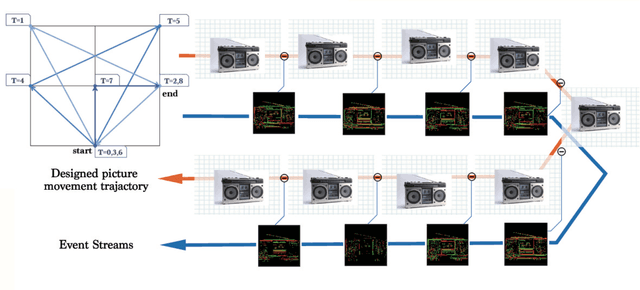
With event-driven algorithms, especially the spiking neural networks (SNNs), achieving continuous improvement in neuromorphic vision processing, a more challenging event-stream-dataset is urgently needed. However, it is well known that creating an ES-dataset is a time-consuming and costly task with neuromorphic cameras like dynamic vision sensors (DVS). In this work, we propose a fast and effective algorithm termed Omnidirectional Discrete Gradient (ODG) to convert the popular computer vision dataset ILSVRC2012 into its event-stream (ES) version, generating about 1,300,000 frame-based images into ES-samples in 1000 categories. In this way, we propose an ES-dataset called ES-ImageNet, which is dozens of times larger than other neuromorphic classification datasets at present and completely generated by the software. The ODG algorithm implements an image motion to generate local value changes with discrete gradient information in different directions, providing a low-cost and high-speed way for converting frame-based images into event streams, along with Edge-Integral to reconstruct the high-quality images from event streams. Furthermore, we analyze the statistics of the ES-ImageNet in multiple ways, and a performance benchmark of the dataset is also provided using both famous deep neural network algorithms and spiking neural network algorithms. We believe that this work shall provide a new large-scale benchmark dataset for SNNs and neuromorphic vision.