 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Techniques for MRI Data Processing at Expanding Scale
Apr 22, 2024Imaging sites around the world generate growing amounts of medical scan data with ever more versatile and affordable technology. Large-scale studies acquire MRI for tens of thousands of participants, together with metadata ranging from lifestyle questionnaires to biochemical assays, genetic analyses and more. These large datasets encode substantial information about human health and hold considerable potential for machine learning training and analysis. This chapter examines ongoing large-scale studies and the challenge of distribution shifts between them. Transfer learning for overcoming such shifts is discussed, together with federated learning for safe access to distributed training data securely held at multiple institutions. Finally, representation learning is reviewed as a methodology for encoding embeddings that express abstract relationships in multi-modal input formats.
MIMIR: Deep Regression for Automated Analysis of UK Biobank Body MRI
Jun 22, 2021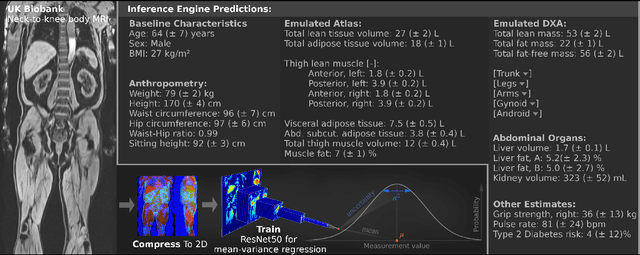
UK Biobank (UKB) is conducting a large-scale study of more than half a million volunteers, collecting health-related information on genetics, lifestyle, blood biochemistry, and more. Medical imaging furthermore targets 100,000 subjects, with 70,000 follow-up sessions, enabling measurements of organs, muscle, and body composition. With up to 170,000 mounting MR images, various methodologies are accordingly engaged in large-scale image analysis. This work presents an experimental inference engine that can automatically predict a comprehensive profile of subject metadata from UKB neck-to-knee body MRI. In cross-validation, it accurately inferred baseline characteristics such as age, height, weight, and sex, but also emulated measurements of body composition by DXA, organ volumes, and abstract properties like grip strength, pulse rate, and type 2 diabetic status (AUC: 0.866). The proposed system can automatically analyze thousands of subjects within hours and provide individual confidence intervals. The underlying methodology is based on convolutional neural networks for image-based mean-variance regression on two-dimensional representations of the MRI data. This work aims to make the proposed system available for free to researchers, who can use it to obtain fast and fully-automated estimates of 72 different measurements immediately upon release of new UK Biobank image data.
Deep regression for uncertainty-aware and interpretable analysis of large-scale body MRI
May 17, 2021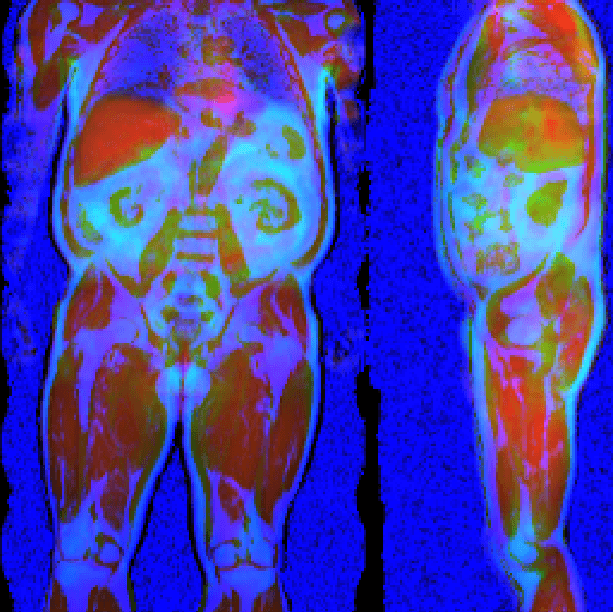
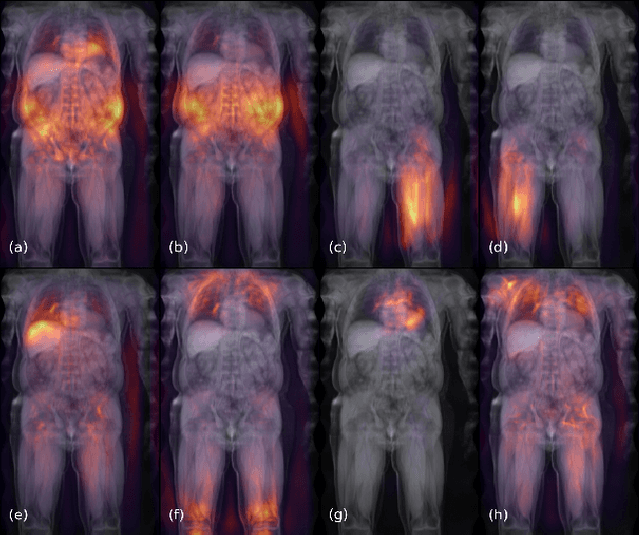
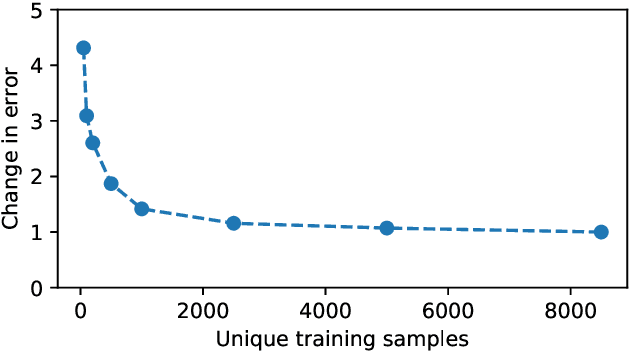
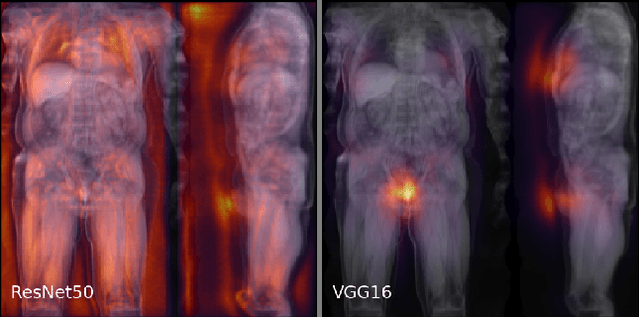
Large-scale medical studies such as the UK Biobank examine thousands of volunteer participants with medical imaging techniques. Combined with the vast amount of collected metadata, anatomical information from these images has the potential for medical analyses at unprecedented scale. However, their evaluation often requires manual input and long processing times, limiting the amount of reference values for biomarkers and other measurements available for research. Recent approaches with convolutional neural networks for regression can perform these evaluations automatically. On magnetic resonance imaging (MRI) data of more than 40,000 UK Biobank subjects, these systems can estimate human age, body composition and more. This style of analysis is almost entirely data-driven and no manual intervention or guidance with manually segmented ground truth images is required. The networks often closely emulate the reference method that provided their training data and can reach levels of agreement comparable to the expected variability between established medical gold standard techniques. The risk of silent failure can be individually quantified by predictive uncertainty obtained from a mean-variance criterion and ensembling. Saliency analysis furthermore enables an interpretation of the underlying relevant image features and showed that the networks learned to correctly target specific organs, limbs, and regions of interest.
Uncertainty-Aware Body Composition Analysis with Deep Regression Ensembles on UK Biobank MRI
Jan 18, 2021
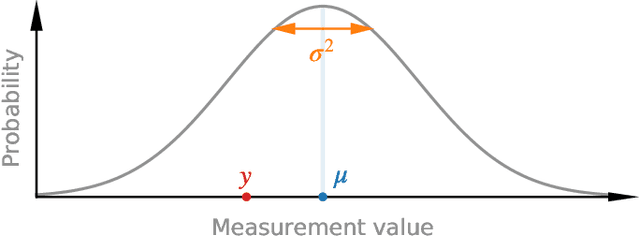
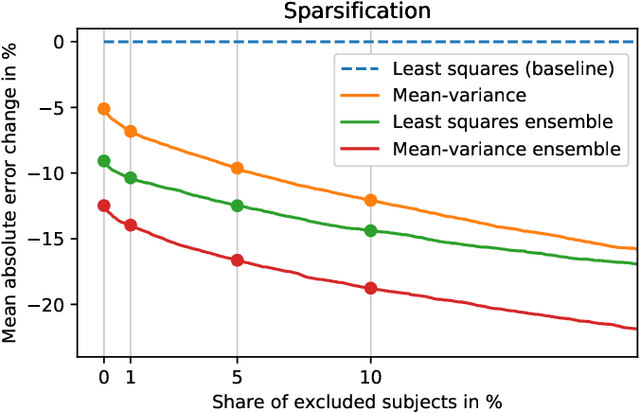
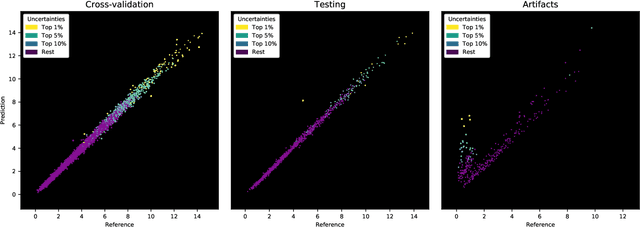
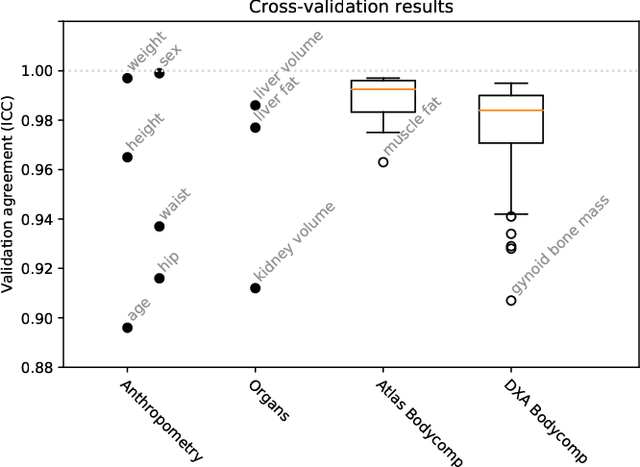
Purpose: To enable fast and automated analysis of body composition from UK Biobank MRI with accurate estimates of individual measurement errors. Methods: In an ongoing large-scale imaging study the UK Biobank has acquired MRI of over 40,000 men and women aged 44-82. Phenotypes derived from these images, such as body composition, can reveal new links between genetics, cardiovascular disease, and metabolic conditions. In this retrospective study, neural networks were trained to provide six measurements of body composition from UK Biobank neck-to-knee body MRI. A ResNet50 architecture can automatically predict these values by image-based regression, but may also produce erroneous outliers. Predictive uncertainty, which could identify these failure cases, was therefore modeled with a mean-variance loss and ensembling. Its estimates of individual prediction errors were evaluated in cross-validation on over 8,000 subjects, tested on another 1,000 cases, and finally applied for inference. Results: Relative measurement errors below 5\% were achieved on all but one target, for intra-class correlation coefficients (ICC) above 0.97 both in validation and testing. Both mean-variance loss and ensembling yielded improvements and provided uncertainty estimates that highlighted some of the worst outlier predictions. Combined, they reached the highest quality, but also exhibited a consistent bias towards high uncertainty in heavyweight subjects. Conclusion: Mean-variance regression and ensembling provided complementary benefits for automated body composition measurements from UK Biobank MRI, reaching high speed and accuracy. These values were inferred for the entire cohort, with uncertainty estimates that can approximate the measurement errors and identify some of the worst outliers automatically.
Large-scale inference of liver fat with neural networks on UK Biobank body MRI
Jun 30, 2020

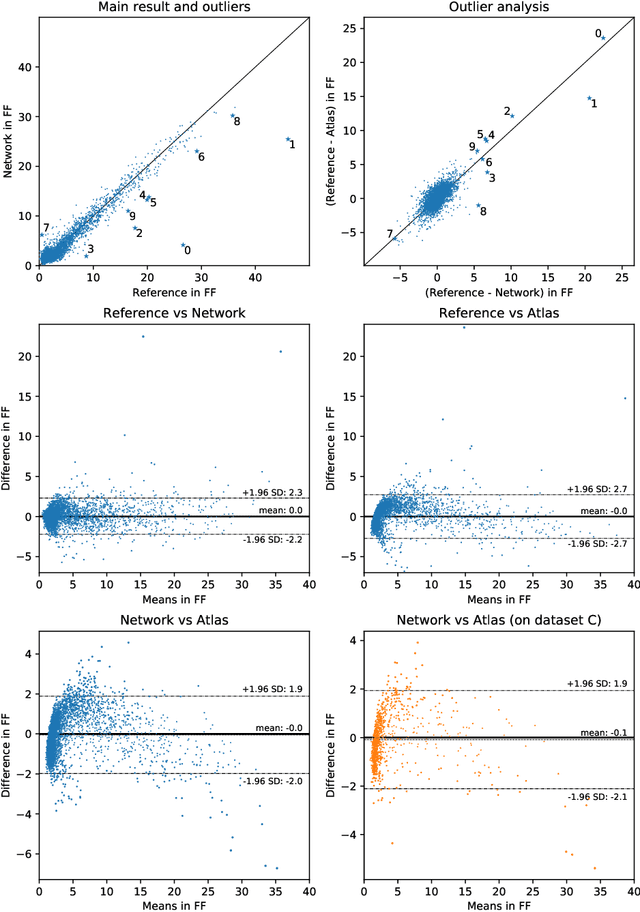
The UK Biobank Imaging Study has acquired medical scans of more than 40,000 volunteer participants. The resulting wealth of anatomical information has been made available for research, together with extensive metadata including measurements of liver fat. These values play an important role in metabolic disease, but are only available for a minority of imaged subjects as their collection requires the careful work of image analysts on dedicated liver MRI. Another UK Biobank protocol is neck-to-knee body MRI for analysis of body composition. The resulting volumes can also quantify fat fractions, even though they were reconstructed with a two- instead of a three-point Dixon technique. In this work, a novel framework for automated inference of liver fat from UK Biobank neck-to-knee body MRI is proposed. A ResNet50 was trained for regression on two-dimensional slices from these scans and the reference values as target, without any need for ground truth segmentations. Once trained, it performs fast, objective, and fully automated predictions that require no manual intervention. On the given data, it closely emulates the reference method, reaching a level of agreement comparable to different gold standard techniques. The network learned to rectify non-linearities in the fat fraction values and identified several outliers in the reference. It outperformed a multi-atlas segmentation baseline and inferred new estimates for all imaged subjects lacking reference values, expanding the total number of liver fat measurements by factor six.
Kidney segmentation in neck-to-knee body MRI of 40,000 UK Biobank participants
Jun 12, 2020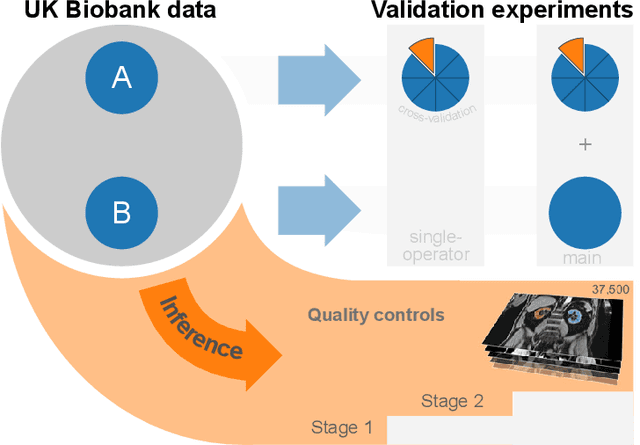

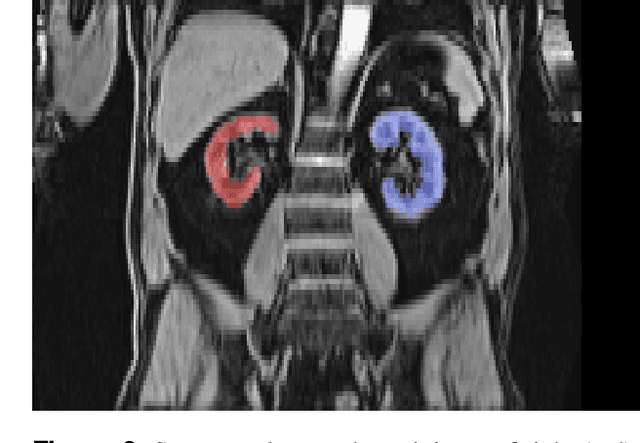
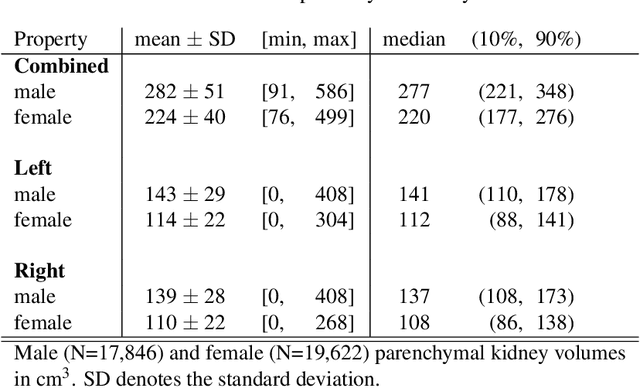
The UK Biobank is collecting extensive data on health-related characteristics of over half a million volunteers. The biological samples of blood and urine can provide valuable insight on kidney function, with important links to cardiovascular and metabolic health. Further information on kidney anatomy could be obtained by medical imaging. In contrast to the brain, heart, liver, and pancreas, no dedicated Magnetic Resonance Imaging (MRI) is planned for the kidneys. An image-based assessment is nonetheless feasible in the neck-to-knee body MRI intended for abdominal body composition analysis, which also covers the kidneys. In this work, a pipeline for automated segmentation of parenchymal kidney volume in UK Biobank neck-to-knee body MRI is proposed. The underlying neural network reaches a relative error of 3.8%, with Dice score 0.956 in validation on 64 subjects, close to the 2.6% and Dice score 0.962 for repeated segmentation by one human operator. The released MRI of about 40,000 subjects can be processed within two days, yielding volume measurements of left and right kidney. Algorithmic quality ratings enabled the exclusion of outliers and potential failure cases. The resulting measurements can be studied and shared for large-scale investigation of associations and longitudinal changes in parenchymal kidney volume.
Large-scale biometry with interpretable neural network regression on UK Biobank body MRI
Mar 10, 2020

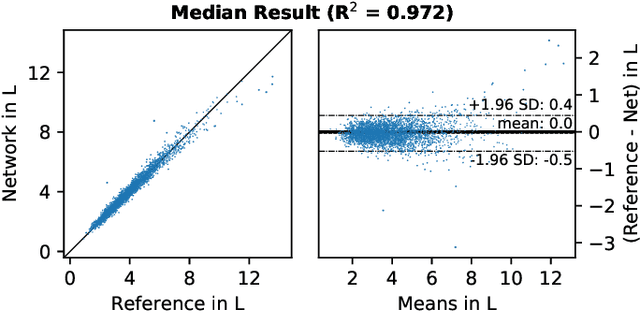
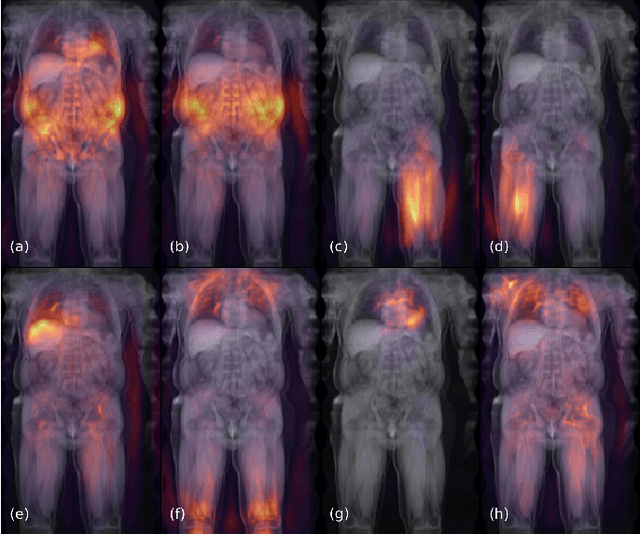
Objective: Automated analysis of MRI with deep regression has the potential to provide medical research with a wide range of biological metrics, inferred at high speed and accuracy. Methods: The UK Biobank study has successfully imaged more than 32,000 volunteer participants with neck-to-knee body MRI. Each scan is linked to extensive metadata, providing a comprehensive survey of imaged anatomy and related health states. Despite its potential for research, this vast amount of data presents a challenge to established methods of evaluation, which often rely on manual input. In this work, neural networks were trained for regression to infer various biological metrics from the neck-to-knee body MRI automatically, with a ResNet50 in 7-fold cross-validation. No manual intervention or ground truth segmentations are required for training. The examined fields span 64 variables derived from anthropometric measurements, dual-energy X-ray absorptiometry (DXA), atlas-based segmentations, and dedicated liver scans. Results: The standardized framework achieved a close fit to the target values (median R^2 > 0.97). Interpretation of aggregated saliency maps indicates that the network correctly targets specific body regions and limbs, and learned to emulate different modalities. On several body composition metrics, the quality of the predictions is within the range of variability observed between established gold standard techniques. Conclusion and Significance: The deep regression framework robustly inferred a wide range of medically relevant metrics from the image data. In practice, this technique could provide accurate, image-based measurements for medical research months or years before the more established reference methods have been fully applied.
Fully Convolutional Networks for Automated Segmentation of Abdominal Adipose Tissue Depots in Multicenter Water-Fat MRI
Nov 01, 2018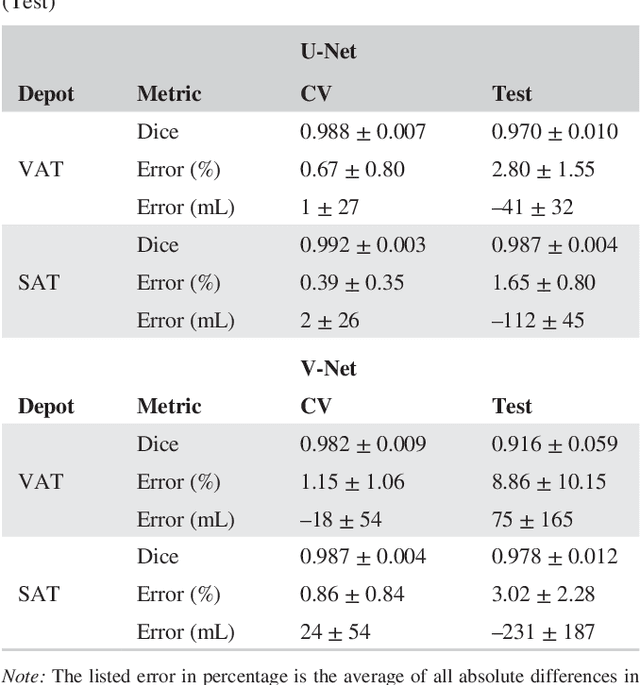
Purpose: An approach for the automated segmentation of visceral adipose tissue (VAT) and subcutaneous adipose tissue (SAT) in multicenter water-fat MRI scans of the abdomen was investigated, using two different neural network architectures. Methods: The two fully convolutional network architectures U-Net and V-Net were trained, evaluated and compared on the water-fat MRI data. Data of the study Tellus with 90 scans from a single center was used for a 10-fold cross-validation in which the most successful configuration for both networks was determined. These configurations were then tested on 20 scans of the multicenter study beta-cell function in JUvenile Diabetes and Obesity (BetaJudo), which involved a different study population and scanning device. Results: The U-Net outperformed the used implementation of the V-Net in both cross-validation and testing. In cross-validation, the U-Net reached average dice scores of 0.988 (VAT) and 0.992 (SAT). The average of the absolute quantification errors amount to 0.67% (VAT) and 0.39% (SAT). On the multi-center test data, the U-Net performs only slightly worse, with average dice scores of 0.970 (VAT) and 0.987 (SAT) and quantification errors of 2.80% (VAT) and 1.65% (SAT). Conclusion: The segmentations generated by the U-Net allow for reliable quantification and could therefore be viable for high-quality automated measurements of VAT and SAT in large-scale studies with minimal need for human intervention. The high performance on the multicenter test data furthermore shows the robustness of this approach for data of different patient demographics and imaging centers, as long as a consistent imaging protocol is used.
* Key words: deep learning, fully convolutional networks, segmentation, water-fat MRI, adipose tissue, abdominal