 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contextual road lane and symbol generation for autonomous driving
Jan 18, 2022

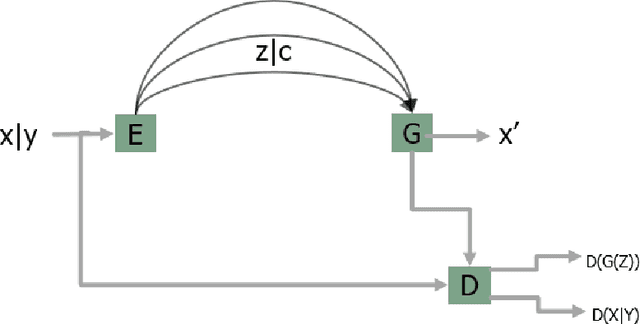
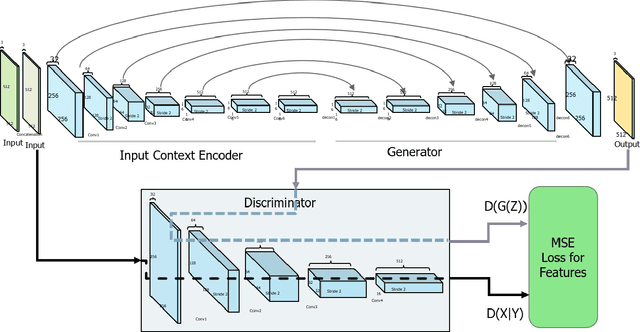

In this paper we present a novel approach for lane detection and segmentation using generative models. Traditionally discriminative models have been employed to classify pixels semantically on a road. We model the probability distribution of lanes and road symbols by training a generative adversarial network. Based on the learned probability distribution, context-aware lanes and road signs are generated for a given image which are further quantized for nearest class label. Proposed method has been tested on BDD100K and Baidu ApolloScape datasets and performs better than state of the art and exhibits robustness to adverse conditions by generating lanes in faded out and occluded scenarios.
Revisiting Deep Semi-supervised Learning: An Empirical Distribution Alignment Framework and Its Generalization Bound
Mar 13, 2022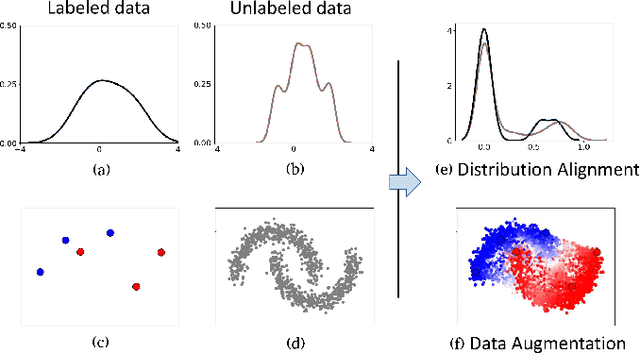
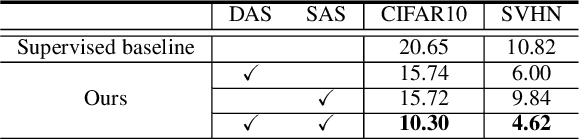
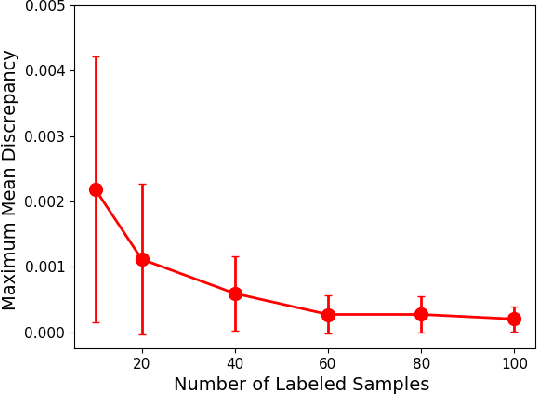
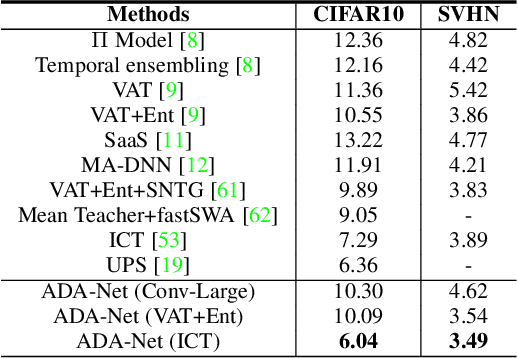
In this work, we revisit the semi-supervised learning (SSL) problem from a new perspective of explicitly reducing empirical distribution mismatch between labeled and unlabeled samples. Benefited from this new perspective, we first propose a new deep semi-supervised learning framework called Semi-supervised Learning by Empirical Distribution Alignment (SLEDA), in which existing technologies from the domain adaptation community can be readily used to address the semi-supervised learning problem through reducing the empirical distribution distance between labeled and unlabeled data. Based on this framework, we also develop a new theoretical generalization bound for the research community to better understand the semi-supervised learning problem, in which we show the generalization error of semi-supervised learning can be effectively bounded by minimizing the training error on labeled data and the empirical distribution distance between labeled and unlabeled data. Building upon our new framework and the theoretical bound, we develop a simple and effective deep semi-supervised learning method called Augmented Distribution Alignment Network (ADA-Net) by simultaneously adopting the well-established adversarial training strategy from the domain adaptation community and a simple sample interpolation strategy for data augmentation. Additionally, we incorporate both strategies in our ADA-Net into two exiting SSL methods to further improve their generalization capability, which indicates that our new framework provides a complementary solution for solving the SSL problem. Our comprehensive experimental results on two benchmark datasets SVHN and CIFAR-10 for the semi-supervised image recognition task and another two benchmark datasets ModelNet40 and ShapeNet55 for the semi-supervised point cloud recognition task demonstrate the effectiveness of our proposed framework for SSL.
Deep Spatial Transformation for Pose-Guided Person Image Generation and Animation
Aug 27, 2020
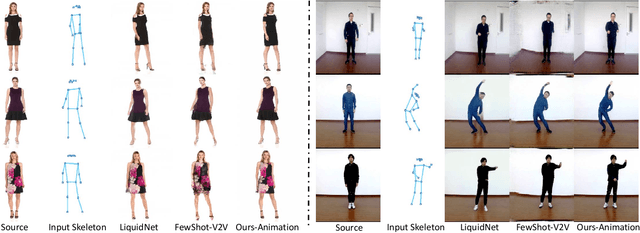


Pose-guided person image generation and animation aim to transform a source person image to target poses. These tasks require spatial manipulation of source data. However, Convolutional Neural Networks are limited by the lack of ability to spatially transform the inputs. In this paper, we propose a differentiable global-flow local-attention framework to reassemble the inputs at the feature level. This framework first estimates global flow fields between sources and targets. Then, corresponding local source feature patches are sampled with content-aware local attention coefficients. We show that our framework can spatially transform the inputs in an efficient manner. Meanwhile, we further model the temporal consistency for the person image animation task to generate coherent videos. The experiment results of both image generation and animation tasks demonstrate the superiority of our model. Besides, additional results of novel view synthesis and face image animation show that our model is applicable to other tasks requiring spatial transformation. The source code of our project is available at https://github.com/RenYurui/Global-Flow-Local-Attention.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
CLAWS: Contrastive Learning with hard Attention and Weak Supervision
Dec 01, 2021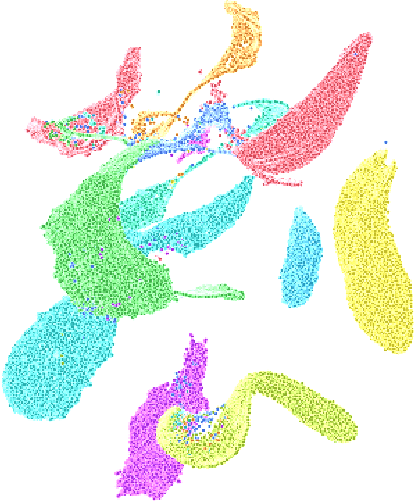
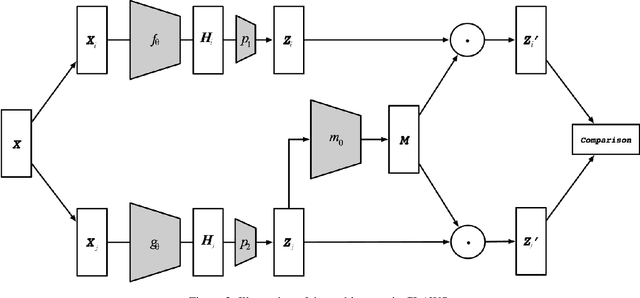
Learning effective visual representations without human supervision is a long-standing problem in computer vision. Recent advances in self-supervised learning algorithms have utilized contrastive learning, with methods such as SimCLR, which applies a composition of augmentations to an image, and minimizes a contrastive loss between the two augmented images. In this paper, we present CLAWS, an annotation-efficient learning framework, addressing the problem of manually labeling large-scale agricultural datasets along with potential applications such as anomaly detection and plant growth analytics. CLAWS uses a network backbone inspired by SimCLR and weak supervision to investigate the effect of contrastive learning within class clusters. In addition, we inject a hard attention mask to the cropped input image before maximizing agreement between the image pairs using a contrastive loss function. This mask forces the network to focus on pertinent object features and ignore background features. We compare results between a supervised SimCLR and CLAWS using an agricultural dataset with 227,060 samples consisting of 11 different crop classes. Our experiments and extensive evaluations show that CLAWS achieves a competitive NMI score of 0.7325. Furthermore, CLAWS engenders the creation of low dimensional representations of very large datasets with minimal parameter tuning and forming well-defined clusters, which lends themselves to using efficient, transparent, and highly interpretable clustering methods such as Gaussian Mixture Models.
SimPatch: A Nearest Neighbor Similarity Match between Image Patches
Aug 07, 2020
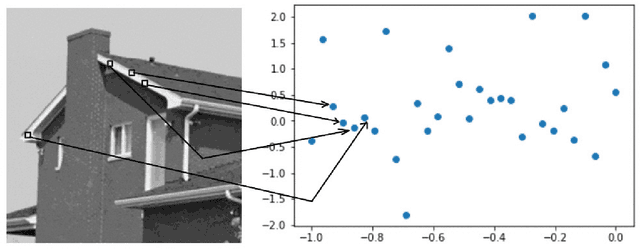


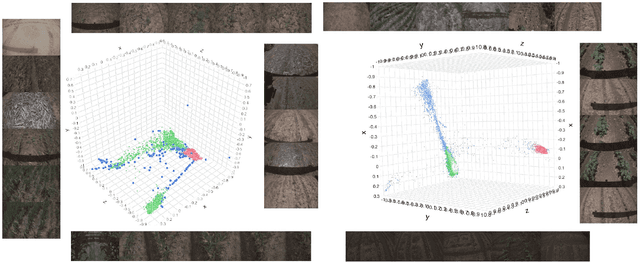
Measuring the similarity between patches in images is a fundamental building block in various tasks. Naturally, the patch-size has a major impact on the matching quality, and on the consequent application performance. We try to use large patches instead of relatively small patches so that each patch contains more information. We use different feature extraction mechanisms to extract the features of each individual image patches which forms a feature matrix and find out the nearest neighbor patches in the image. The nearest patches are calculated using two different nearest neighbor algorithms in this paper for a query patch for a given image and the results have been demonstrated in this paper.
Comparative Fault Location Estimation by Using Image Processing in Mixed Transmission Lines
Feb 22, 2021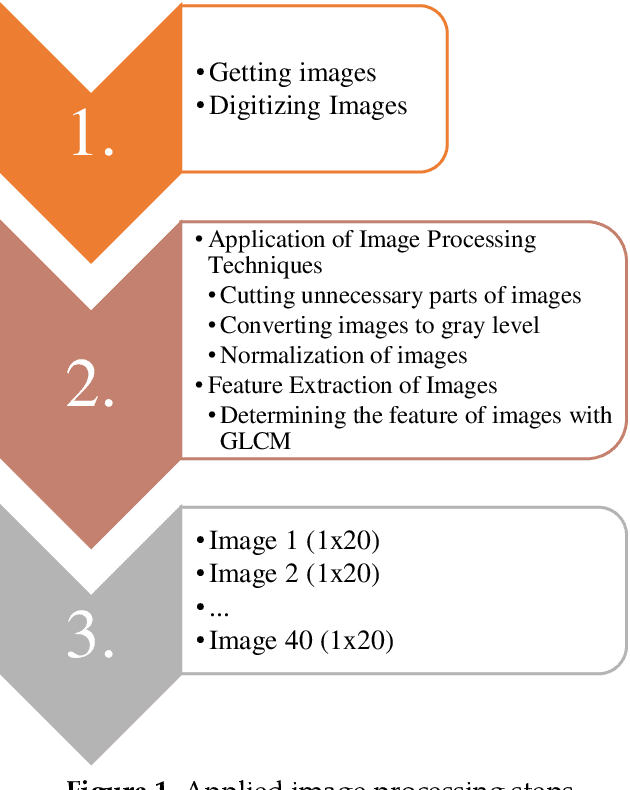
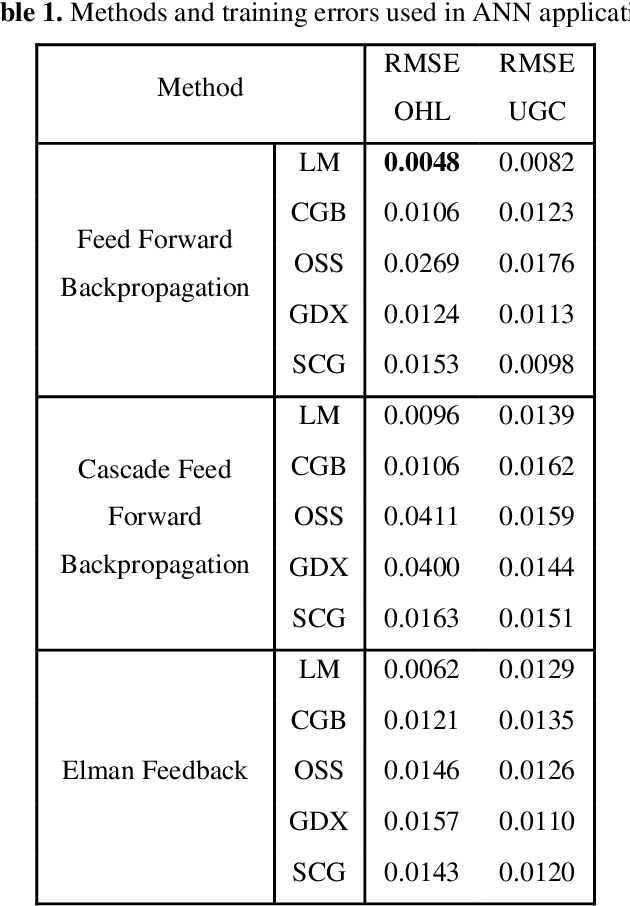
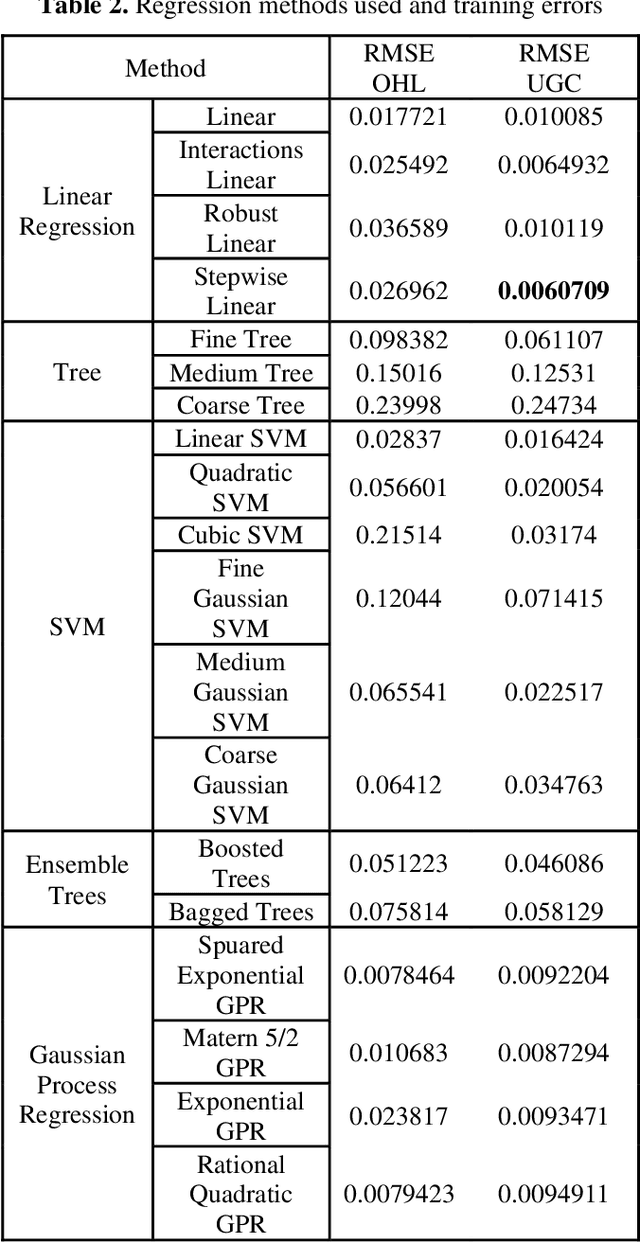
The distance protection relays are used to determine the impedance based fault location according to the current and voltage magnitudes in the transmission lines. However, the fault location cannot be correctly detected in mixed transmission lines due to different characteristic impedance per unit length because the characteristic impedance of high voltage cable line is significantly different from overhead line. Thus, determinations of the fault section and location with the distance protection relays are difficult in the mixed transmission lines. In this study, 154 kV overhead transmission line and underground cable line are examined as the mixed transmission line for the distance protection relays. Phase to ground faults are created in the mixed transmission line. overhead line section and underground cable section are simulated by using PSCAD-EMTDC.The short circuit fault images are generated in the distance protection relay for the overhead transmission line and underground cable transmission line faults. The images include the R-X impedance diagram of the fault, and the R-X impedance diagram have been detected by applying image processing steps. Artificial neural network (ANN) and the regression methods are used for prediction of the fault location, and the results of image processing are used as the input parameters for the training process of ANN and the regression methods. The results of ANN and regression methods are compared to select the most suitable method at the end of this study for forecasting of the fault location in transmission lines.
* arXiv admin note: substantial text overlap with arXiv:2011.03238
Location Sensitive Image Retrieval and Tagging
Jul 07, 2020
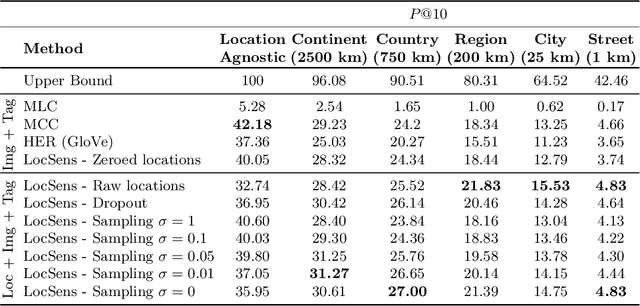

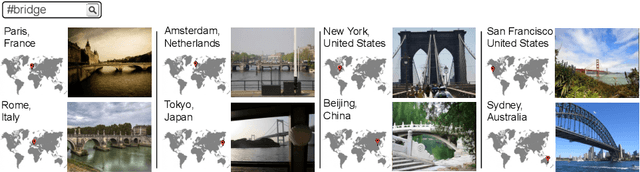
People from different parts of the globe describe objects and concepts in distinct manners. Visual appearance can thus vary across different geographic locations, which makes location a relevant contextual information when analysing visual data. In this work, we address the task of image retrieval related to a given tag conditioned on a certain location on Earth. We present LocSens, a model that learns to rank triplets of images, tags and coordinates by plausibility, and two training strategies to balance the location influence in the final ranking. LocSens learns to fuse textual and location information of multimodal queries to retrieve related images at different levels of location granularity, and successfully utilizes location information to improve image tagging.
Data-efficient learning of object-centric grasp preferences
Mar 01, 2022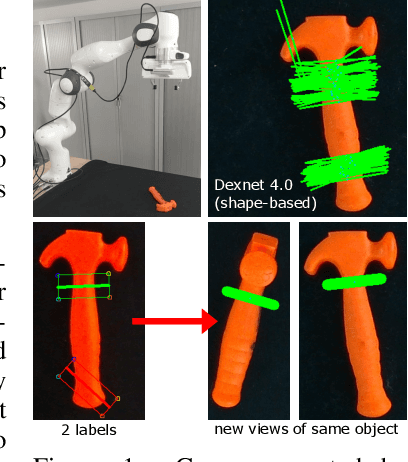
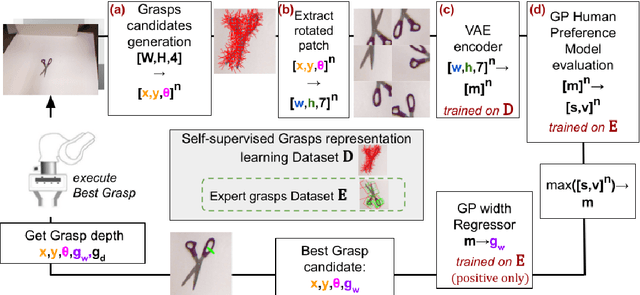
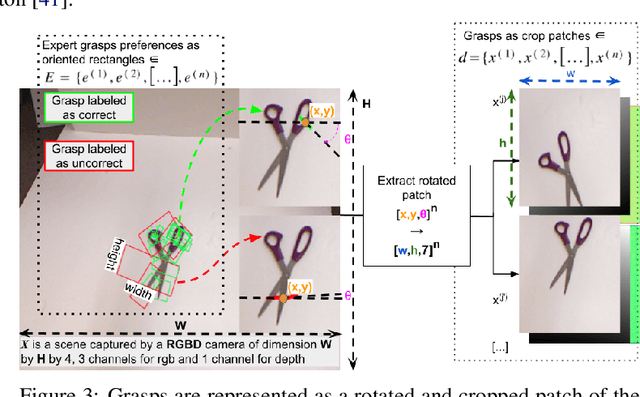

Grasping made impressive progress during the last few years thanks to deep learning. However, there are many objects for which it is not possible to choose a grasp by only looking at an RGB-D image, might it be for physical reasons (e.g., a hammer with uneven mass distribution) or task constraints (e.g., food that should not be spoiled). In such situations, the preferences of experts need to be taken into account. In this paper, we introduce a data-efficient grasping pipeline (Latent Space GP Selector -- LGPS) that learns grasp preferences with only a few labels per object (typically 1 to 4) and generalizes to new views of this object. Our pipeline is based on learning a latent space of grasps with a dataset generated with any state-of-the-art grasp generator (e.g., Dex-Net). This latent space is then used as a low-dimensional input for a Gaussian process classifier that selects the preferred grasp among those proposed by the generator. The results show that our method outperforms both GR-ConvNet and GG-CNN (two state-of-the-art methods that are also based on labeled grasps) on the Cornell dataset, especially when only a few labels are used: only 80 labels are enough to correctly choose 80% of the grasps (885 scenes, 244 objects). Results are similar on our dataset (91 scenes, 28 objects).
Complementary Time-Frequency Domain Networks for Dynamic Parallel MR Image Reconstruction
Dec 22, 2020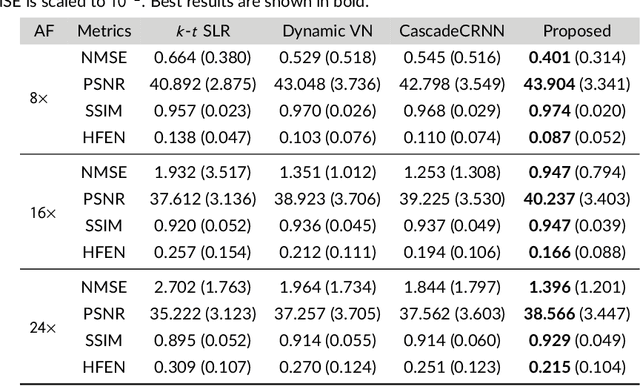
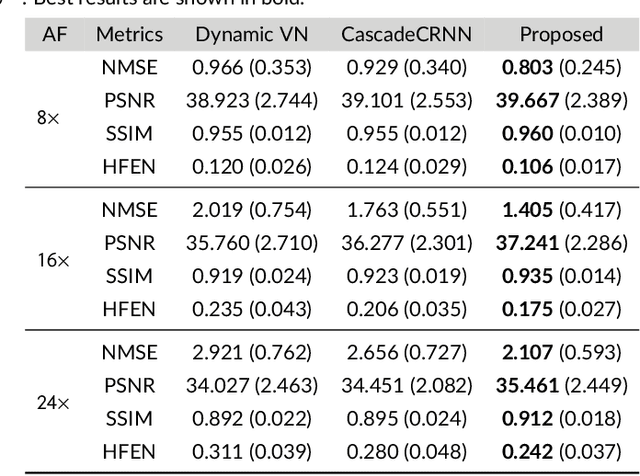
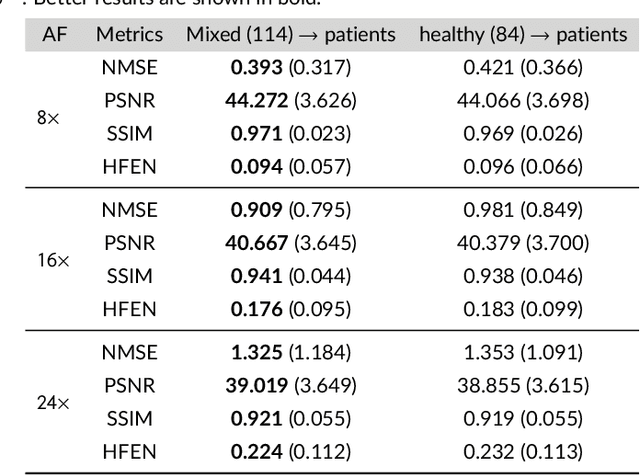
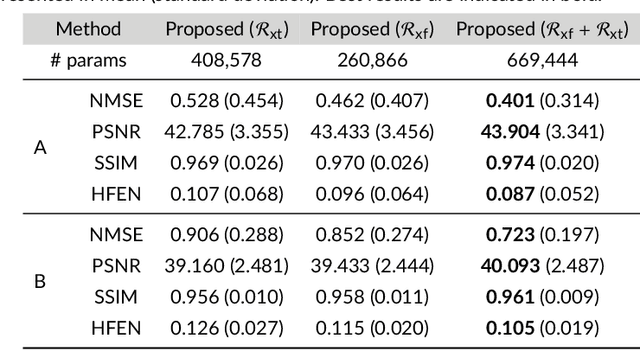
Purpose: To introduce a novel deep learning based approach for fast and high-quality dynamic multi-coil MR reconstruction by learning a complementary time-frequency domain network that exploits spatio-temporal correlations simultaneously from complementary domains. Theory and Methods: Dynamic parallel MR image reconstruction is formulated as a multi-variable minimisation problem, where the data is regularised in combined temporal Fourier and spatial (x-f) domain as well as in spatio-temporal image (x-t) domain. An iterative algorithm based on variable splitting technique is derived, which alternates among signal de-aliasing steps in x-f and x-t spaces, a closed-form point-wise data consistency step and a weighted coupling step. The iterative model is embedded into a deep recurrent neural network which learns to recover the image via exploiting spatio-temporal redundancies in complementary domains. Results: Experiments were performed on two datasets of highly undersampled multi-coil short-axis cardiac cine MRI scans. Results demonstrate that our proposed method outperforms the current state-of-the-art approaches both quantitatively and qualitatively. The proposed model can also generalise well to data acquired from a different scanner and data with pathologies that were not seen in the training set. Conclusion: The work shows the benefit of reconstructing dynamic parallel MRI in complementary time-frequency domains with deep neural networks. The method can effectively and robustly reconstruct high-quality images from highly undersampled dynamic multi-coil data ($16 \times$ and $24 \times$ yielding 15s and 10s scan times respectively) with fast reconstruction speed (2.8s). This could potentially facilitate achieving fast single-breath-hold clinical 2D cardiac cine imaging.