 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALMUBench: A Benchmark for Sensitive Association-Level Multimodal Unlearning
Mar 27, 2026As multimodal models like CLIP become integral to downstream systems, the need to remove sensitive information is critical. However, machine unlearning for contrastively-trained encoders remains underexplored, and existing evaluations fail to diagnose fine-grained, association-level forgetting. We introduce SALMUBench (Sensitive Association-Level Multimodal Unlearning), a benchmark built upon a synthetic dataset of 60K persona-attribute associations and two foundational models: a Compromised model polluted with this data, and a Clean model without it. To isolate unlearning effects, both are trained from scratch on the same 400M-pair retain base, with the Compromised model additionally trained on the sensitive set. We propose a novel evaluation protocol with structured holdout sets (holdout identity, holdout association) to precisely measure unlearning efficacy and collateral damage. Our benchmark reveals that while utility-efficient deletion is feasible, current methods exhibit distinct failure modes: they either fail to forget effectively or over-generalize by erasing more than intended. SALMUBench sets a new standard for comprehensive unlearning evaluation, and we publicly release our dataset, models, evaluation scripts, and leaderboards to foster future research.
Preserving Privacy Without Compromising Accuracy: Machine Unlearning for Handwritten Text Recognition
Apr 11, 2025



Handwritten Text Recognition (HTR) is essential for document analysis and digitization. However, handwritten data often contains user-identifiable information, such as unique handwriting styles and personal lexicon choices, which can compromise privacy and erode trust in AI services. Legislation like the ``right to be forgotten'' underscores the necessity for methods that can expunge sensitive information from trained models. Machine unlearning addresses this by selectively removing specific data from models without necessitating complete retraining. Yet, it frequently encounters a privacy-accuracy tradeoff, where safeguarding privacy leads to diminished model performance. In this paper, we introduce a novel two-stage unlearning strategy for a multi-head transformer-based HTR model, integrating pruning and random labeling. Our proposed method utilizes a writer classification head both as an indicator and a trigger for unlearning, while maintaining the efficacy of the recognition head. To our knowledge, this represents the first comprehensive exploration of machine unlearning within HTR tasks. We further employ Membership Inference Attacks (MIA) to evaluate the effectiveness of unlearning user-identifiable information. Extensive experiments demonstrate that our approach effectively preserves privacy while maintaining model accuracy, paving the way for new research directions in the document analysis community. Our code will be publicly available upon acceptance.
Transductive Learning for Near-Duplicate Image Detection in Scanned Photo Collections
Oct 25, 2024This paper presents a comparative study of near-duplicate image detection techniques in a real-world use case scenario, where a document management company is commissioned to manually annotate a collection of scanned photographs. Detecting duplicate and near-duplicate photographs can reduce the time spent on manual annotation by archivists. This real use case differs from laboratory settings as the deployment dataset is available in advance, allowing the use of transductive learning. We propose a transductive learning approach that leverages state-of-the-art deep learning architectures such as convolutional neural networks (CNNs) and Vision Transformers (ViTs). Our approach involves pre-training a deep neural network on a large dataset and then fine-tuning the network on the unlabeled target collection with self-supervised learning. The results show that the proposed approach outperforms the baseline methods in the task of near-duplicate image detection in the UKBench and an in-house private dataset.
EUFCC-CIR: a Composed Image Retrieval Dataset for GLAM Collections
Oct 02, 2024



The intersection of Artificial Intelligence and Digital Humanities enables researchers to explore cultural heritage collections with greater depth and scale. In this paper, we present EUFCC-CIR, a dataset designed for Composed Image Retrieval (CIR) within Galleries, Libraries, Archives, and Museums (GLAM) collections. Our dataset is built on top of the EUFCC-340K image labeling dataset and contains over 180K annotated CIR triplets. Each triplet is composed of a multi-modal query (an input image plus a short text describing the desired attribute manipulations) and a set of relevant target images. The EUFCC-CIR dataset fills an existing gap in CIR-specific resources for Digital Humanities. We demonstrate the value of the EUFCC-CIR dataset by highlighting its unique qualities in comparison to other existing CIR datasets and evaluating the performance of several zero-shot CIR baselines.
GRIF-DM: Generation of Rich Impression Fonts using Diffusion Models
Aug 14, 2024



Fonts are integral to creative endeavors, design processes, and artistic productions. The appropriate selection of a font can significantly enhance artwork and endow advertisements with a higher level of expressivity. Despite the availability of numerous diverse font designs online, traditional retrieval-based methods for font selection are increasingly being supplanted by generation-based approaches. These newer methods offer enhanced flexibility, catering to specific user preferences and capturing unique stylistic impressions. However, current impression font techniques based on Generative Adversarial Networks (GANs) necessitate the utilization of multiple auxiliary losses to provide guidance during generation. Furthermore, these methods commonly employ weighted summation for the fusion of impression-related keywords. This leads to generic vectors with the addition of more impression keywords, ultimately lacking in detail generation capacity. In this paper, we introduce a diffusion-based method, termed \ourmethod, to generate fonts that vividly embody specific impressions, utilizing an input consisting of a single letter and a set of descriptive impression keywords. The core innovation of \ourmethod lies in the development of dual cross-attention modules, which process the characteristics of the letters and impression keywords independently but synergistically, ensuring effective integration of both types of information. Our experimental results, conducted on the MyFonts dataset, affirm that this method is capable of producing realistic, vibrant, and high-fidelity fonts that are closely aligned with user specifications. This confirms the potential of our approach to revolutionize font generation by accommodating a broad spectrum of user-driven design requirements. Our code is publicly available at \url{https://github.com/leitro/GRIF-DM}.
EUFCC-340K: A Faceted Hierarchical Dataset for Metadata Annotation in GLAM Collections
Jun 04, 2024



In this paper, we address the challenges of automatic metadata annotation in the domain of Galleries, Libraries, Archives, and Museums (GLAMs) by introducing a novel dataset, EUFCC340K, collected from the Europeana portal. Comprising over 340,000 images, the EUFCC340K dataset is organized across multiple facets: Materials, Object Types, Disciplines, and Subjects, following a hierarchical structure based on the Art & Architecture Thesaurus (AAT). We developed several baseline models, incorporating multiple heads on a ConvNeXT backbone for multi-label image tagging on these facets, and fine-tuning a CLIP model with our image text pairs. Our experiments to evaluate model robustness and generalization capabilities in two different test scenarios demonstrate the utility of the dataset in improving multi-label classification tools that have the potential to alleviate cataloging tasks in the cultural heritage sector.
Machine Unlearning for Document Classification
Apr 29, 2024



Document understanding models have recently demonstrated remarkable performance by leveraging extensive collections of user documents. However, since documents often contain large amounts of personal data, their usage can pose a threat to user privacy and weaken the bonds of trust between humans and AI services. In response to these concerns, legislation advocating ``the right to be forgotten" has recently been proposed, allowing users to request the removal of private information from computer systems and neural network models. A novel approach, known as machine unlearning, has emerged to make AI models forget about a particular class of data. In our research, we explore machine unlearning for document classification problems, representing, to the best of our knowledge, the first investigation into this area. Specifically, we consider a realistic scenario where a remote server houses a well-trained model and possesses only a small portion of training data. This setup is designed for efficient forgetting manipulation. This work represents a pioneering step towards the development of machine unlearning methods aimed at addressing privacy concerns in document analysis applications. Our code is publicly available at \url{https://github.com/leitro/MachineUnlearning-DocClassification}.
Show, Interpret and Tell: Entity-aware Contextualised Image Captioning in Wikipedia
Sep 21, 2022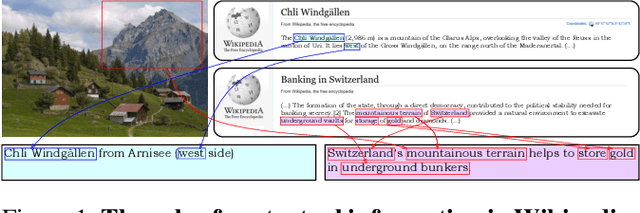
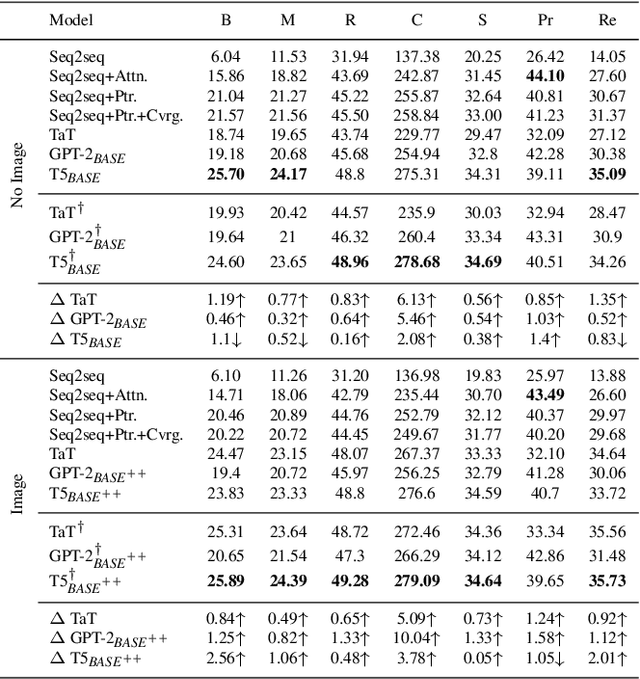
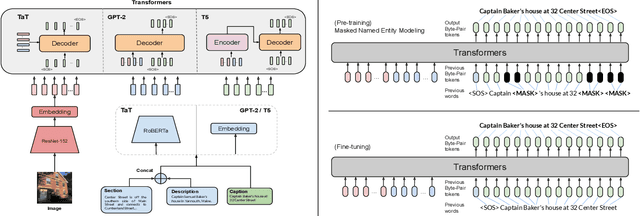
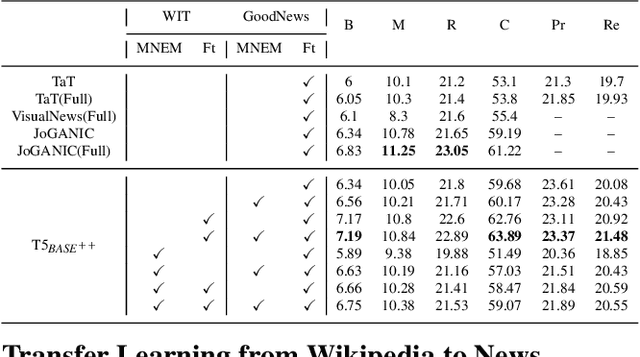
Humans exploit prior knowledge to describe images, and are able to adapt their explanation to specific contextual information, even to the extent of inventing plausible explanations when contextual information and images do not match. In this work, we propose the novel task of captioning Wikipedia images by integrating contextual knowledge. Specifically, we produce models that jointly reason over Wikipedia articles, Wikimedia images and their associated descriptions to produce contextualized captions. Particularly, a similar Wikimedia image can be used to illustrate different articles, and the produced caption needs to be adapted to a specific context, therefore allowing us to explore the limits of a model to adjust captions to different contextual information. A particular challenging task in this domain is dealing with out-of-dictionary words and Named Entities. To address this, we propose a pre-training objective, Masked Named Entity Modeling (MNEM), and show that this pretext task yields an improvement compared to baseline models. Furthermore, we verify that a model pre-trained with the MNEM objective in Wikipedia generalizes well to a News Captioning dataset. Additionally, we define two different test splits according to the difficulty of the captioning task. We offer insights on the role and the importance of each modality and highlight the limitations of our model. The code, models and data splits are publicly available at Upon acceptance.
MUST-VQA: MUltilingual Scene-text VQA
Sep 14, 2022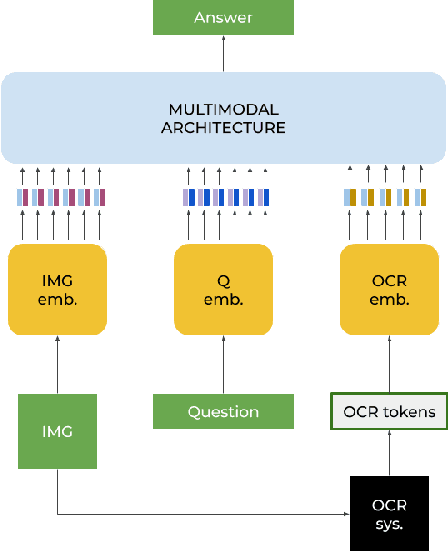
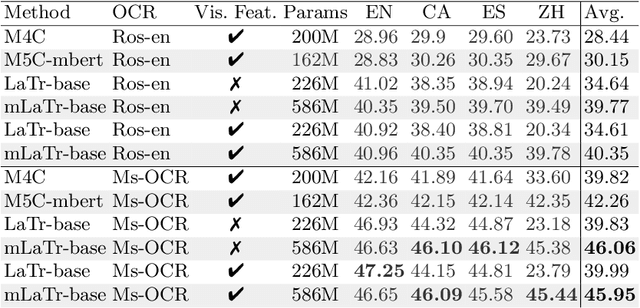
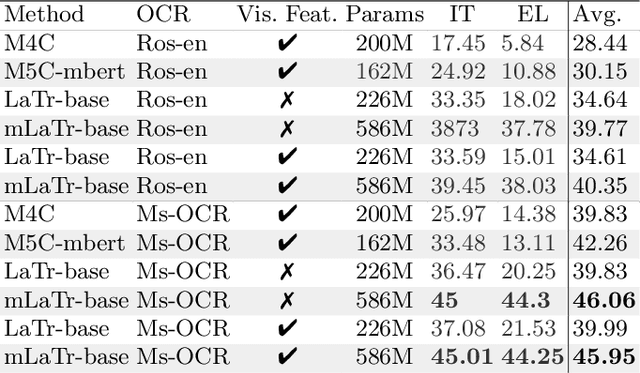
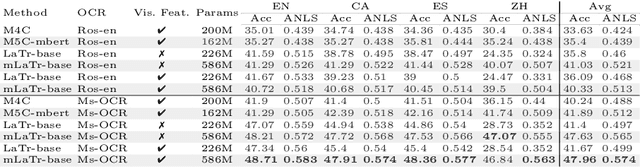
In this paper, we present a framework for Multilingual Scene Text Visual Question Answering that deals with new languages in a zero-shot fashion. Specifically, we consider the task of Scene Text Visual Question Answering (STVQA) in which the question can be asked in different languages and it is not necessarily aligned to the scene text language. Thus, we first introduce a natural step towards a more generalized version of STVQA: MUST-VQA. Accounting for this, we discuss two evaluation scenarios in the constrained setting, namely IID and zero-shot and we demonstrate that the models can perform on a par on a zero-shot setting. We further provide extensive experimentation and show the effectiveness of adapting multilingual language models into STVQA tasks.
A Generic Image Retrieval Method for Date Estimation of Historical Document Collections
Apr 08, 2022



Date estimation of historical document images is a challenging problem, with several contributions in the literature that lack of the ability to generalize from one dataset to others. This paper presents a robust date estimation system based in a retrieval approach that generalizes well in front of heterogeneous collections. we use a ranking loss function named smooth-nDCG to train a Convolutional Neural Network that learns an ordination of documents for each problem. One of the main usages of the presented approach is as a tool for historical contextual retrieval. It means that scholars could perform comparative analysis of historical images from big datasets in terms of the period where they were produced. We provide experimental evaluation on different types of documents from real datasets of manuscript and newspaper images.