 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Guided Unsupervised Multi-domain Image-to-Image Translation
Aug 11, 2020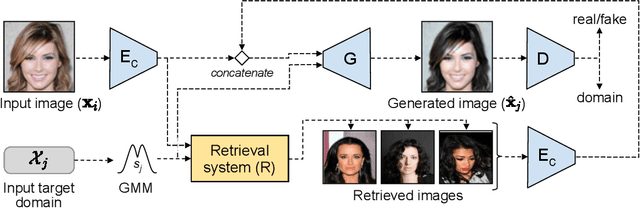
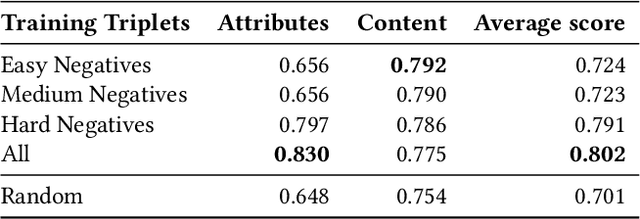
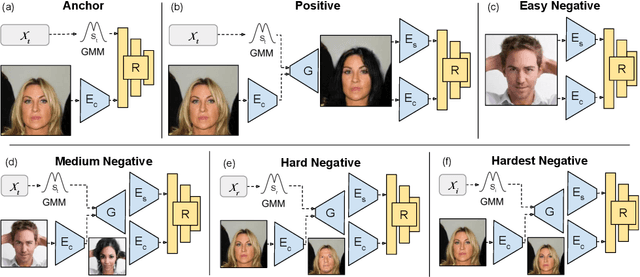
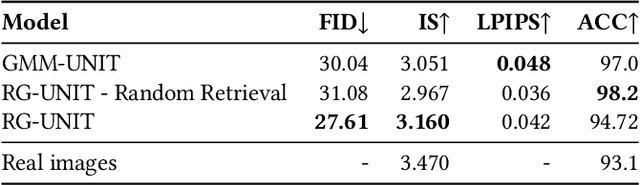
Image to image translation aims to learn a mapping that transforms an image from one visual domain to another. Recent works assume that images descriptors can be disentangled into a domain-invariant content representation and a domain-specific style representation. Thus, translation models seek to preserve the content of source images while changing the style to a target visual domain. However, synthesizing new images is extremely challenging especially in multi-domain translations, as the network has to compose content and style to generate reliable and diverse images in multiple domains. In this paper we propose the use of an image retrieval system to assist the image-to-image translation task. First, we train an image-to-image translation model to map images to multiple domains. Then, we train an image retrieval model using real and generated images to find images similar to a query one in content but in a different domain. Finally, we exploit the image retrieval system to fine-tune the image-to-image translation model and generate higher quality images. Our experiments show the effectiveness of the proposed solution and highlight the contribution of the retrieval network, which can benefit from additional unlabeled data and help image-to-image translation models in the presence of scarce data.
Location Sensitive Image Retrieval and Tagging
Jul 07, 2020
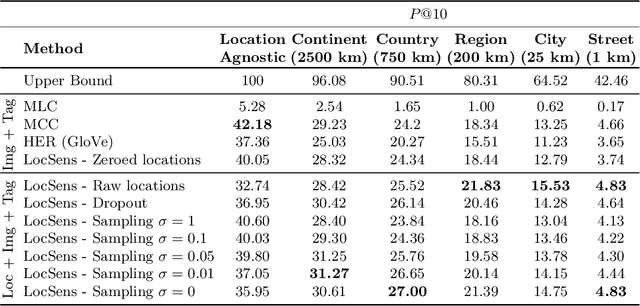

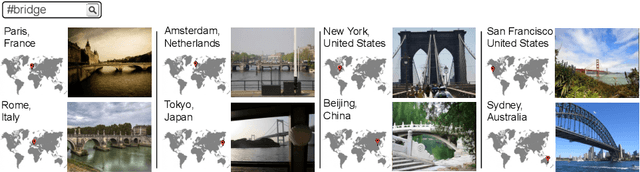
People from different parts of the globe describe objects and concepts in distinct manners. Visual appearance can thus vary across different geographic locations, which makes location a relevant contextual information when analysing visual data. In this work, we address the task of image retrieval related to a given tag conditioned on a certain location on Earth. We present LocSens, a model that learns to rank triplets of images, tags and coordinates by plausibility, and two training strategies to balance the location influence in the final ranking. LocSens learns to fuse textual and location information of multimodal queries to retrieve related images at different levels of location granularity, and successfully utilizes location information to improve image tagging.
Exploring Hate Speech Detection in Multimodal Publications
Oct 09, 2019
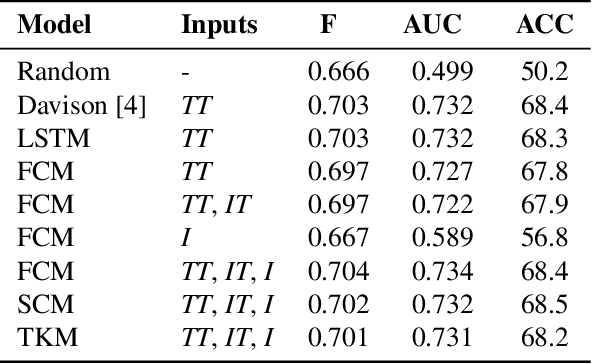
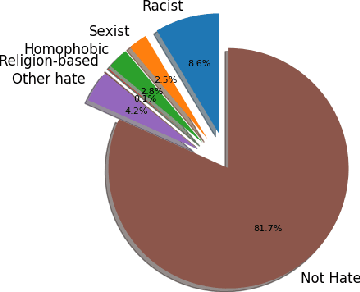
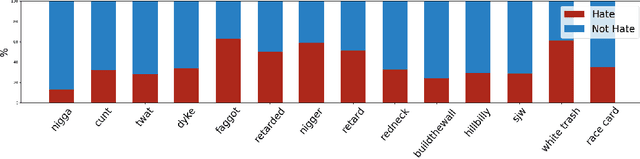
In this work we target the problem of hate speech detection in multimodal publications formed by a text and an image. We gather and annotate a large scale dataset from Twitter, MMHS150K, and propose different models that jointly analyze textual and visual information for hate speech detection, comparing them with unimodal detection. We provide quantitative and qualitative results and analyze the challenges of the proposed task. We find that, even though images are useful for the hate speech detection task, current multimodal models cannot outperform models analyzing only text. We discuss why and open the field and the dataset for further research.
Selective Style Transfer for Text
Jun 04, 2019

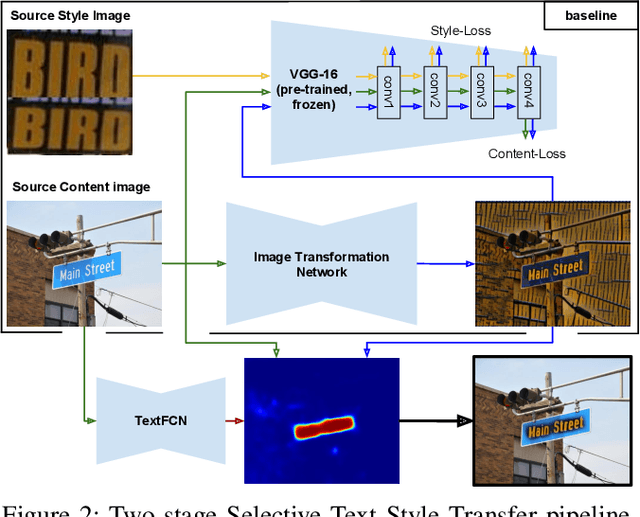
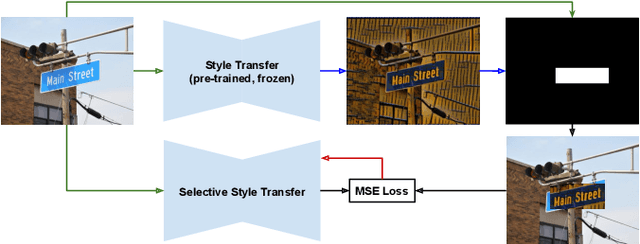
This paper explores the possibilities of image style transfer applied to text maintaining the original transcriptions. Results on different text domains (scene text, machine printed text and handwritten text) and cross modal results demonstrate that this is feasible, and open different research lines. Furthermore, two architectures for selective style transfer, which means transferring style to only desired image pixels, are proposed. Finally, scene text selective style transfer is evaluated as a data augmentation technique to expand scene text detection datasets, resulting in a boost of text detectors performance. Our implementation of the described models is publicly available.
Self-Supervised Learning from Web Data for Multimodal Retrieval
Jan 07, 2019

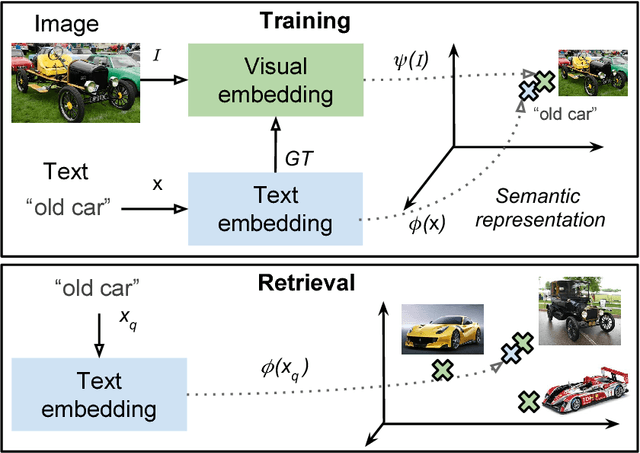
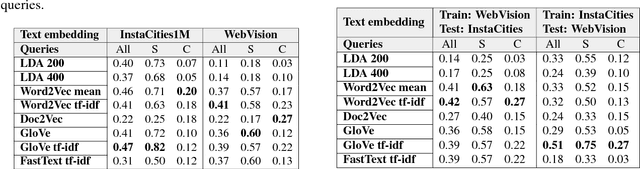
Self-Supervised learning from multimodal image and text data allows deep neural networks to learn powerful features with no need of human annotated data. Web and Social Media platforms provide a virtually unlimited amount of this multimodal data. In this work we propose to exploit this free available data to learn a multimodal image and text embedding, aiming to leverage the semantic knowledge learnt in the text domain and transfer it to a visual model for semantic image retrieval. We demonstrate that the proposed pipeline can learn from images with associated textwithout supervision and analyze the semantic structure of the learnt joint image and text embedding space. We perform a thorough analysis and performance comparison of five different state of the art text embeddings in three different benchmarks. We show that the embeddings learnt with Web and Social Media data have competitive performances over supervised methods in the text based image retrieval task, and we clearly outperform state of the art in the MIRFlickr dataset when training in the target data. Further, we demonstrate how semantic multimodal image retrieval can be performed using the learnt embeddings, going beyond classical instance-level retrieval problems. Finally, we present a new dataset, InstaCities1M, composed by Instagram images and their associated texts that can be used for fair comparison of image-text embeddings.
Learning from #Barcelona Instagram data what Locals and Tourists post about its Neighbourhoods
Aug 20, 2018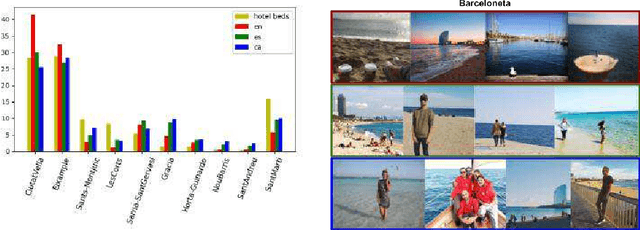

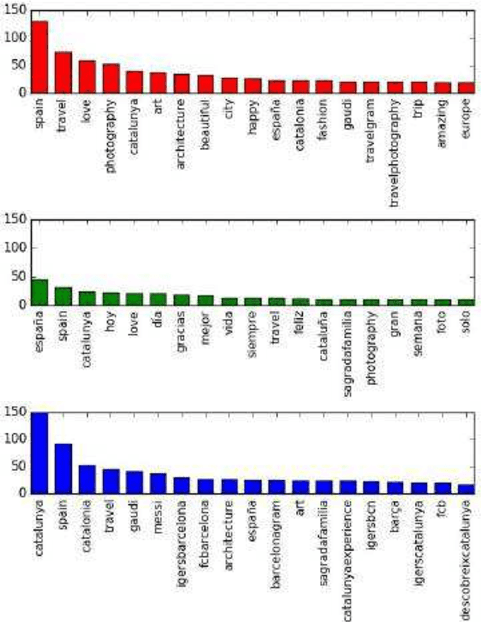
Massive tourism is becoming a big problem for some cities, such as Barcelona, due to its concentration in some neighborhoods. In this work we gather Instagram data related to Barcelona consisting on images-captions pairs and, using the text as a supervisory signal, we learn relations between images, words and neighborhoods. Our goal is to learn which visual elements appear in photos when people is posting about each neighborhood. We perform a language separate treatment of the data and show that it can be extrapolated to a tourists and locals separate analysis, and that tourism is reflected in Social Media at a neighborhood level. The presented pipeline allows analyzing the differences between the images that tourists and locals associate to the different neighborhoods. The proposed method, which can be extended to other cities or subjects, proves that Instagram data can be used to train multi-modal (image and text) machine learning models that are useful to analyze publications about a city at a neighborhood level. We publish the collected dataset, InstaBarcelona and the code used in the analysis.
Learning to Learn from Web Data through Deep Semantic Embeddings
Aug 20, 2018
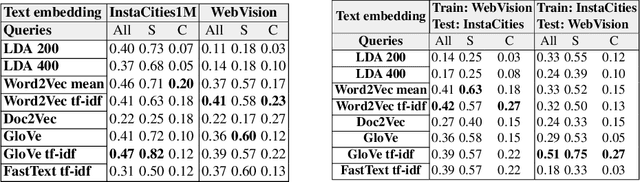
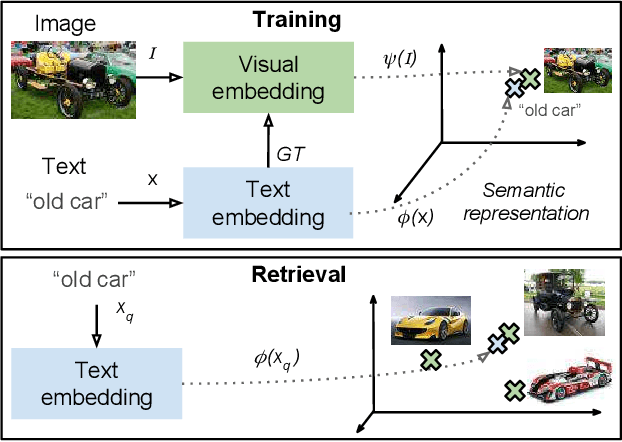

In this paper we propose to learn a multimodal image and text embedding from Web and Social Media data, aiming to leverage the semantic knowledge learnt in the text domain and transfer it to a visual model for semantic image retrieval. We demonstrate that the pipeline can learn from images with associated text without supervision and perform a thourough analysis of five different text embeddings in three different benchmarks. We show that the embeddings learnt with Web and Social Media data have competitive performances over supervised methods in the text based image retrieval task, and we clearly outperform state of the art in the MIRFlickr dataset when training in the target data. Further we demonstrate how semantic multimodal image retrieval can be performed using the learnt embeddings, going beyond classical instance-level retrieval problems. Finally, we present a new dataset, InstaCities1M, composed by Instagram images and their associated texts that can be used for fair comparison of image-text embeddings.
TextTopicNet - Self-Supervised Learning of Visual Features Through Embedding Images on Semantic Text Spaces
Jul 04, 2018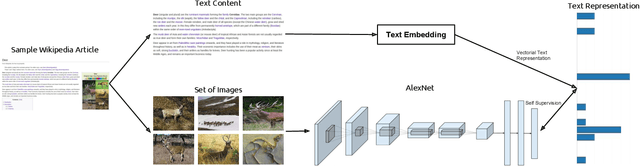
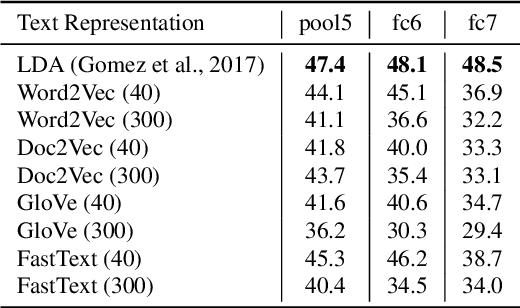

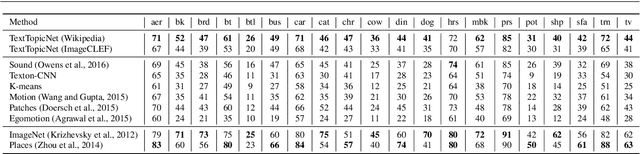
The immense success of deep learning based methods in computer vision heavily relies on large scale training datasets. These richly annotated datasets help the network learn discriminative visual features. Collecting and annotating such datasets requires a tremendous amount of human effort and annotations are limited to popular set of classes. As an alternative, learning visual features by designing auxiliary tasks which make use of freely available self-supervision has become increasingly popular in the computer vision community. In this paper, we put forward an idea to take advantage of multi-modal context to provide self-supervision for the training of computer vision algorithms. We show that adequate visual features can be learned efficiently by training a CNN to predict the semantic textual context in which a particular image is more probable to appear as an illustration. More specifically we use popular text embedding techniques to provide the self-supervision for the training of deep CNN. Our experiments demonstrate state-of-the-art performance in image classification, object detection, and multi-modal retrieval compared to recent self-supervised or naturally-supervised approaches.
Improving Text Proposals for Scene Images with Fully Convolutional Networks
Feb 16, 2017



Text Proposals have emerged as a class-dependent version of object proposals - efficient approaches to reduce the search space of possible text object locations in an image. Combined with strong word classifiers, text proposals currently yield top state of the art results in end-to-end scene text recognition. In this paper we propose an improvement over the original Text Proposals algorithm of Gomez and Karatzas (2016), combining it with Fully Convolutional Networks to improve the ranking of proposals. Results on the ICDAR RRC and the COCO-text datasets show superior performance over current state-of-the-art.