 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prompt Tuning based Adapter for Vision-Language Model Adaption
Mar 24, 2023
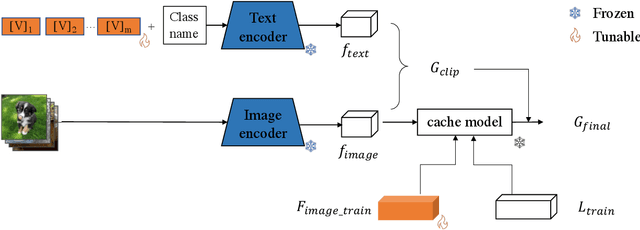
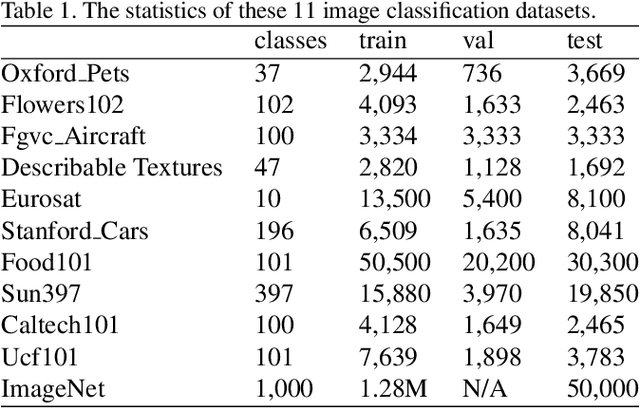

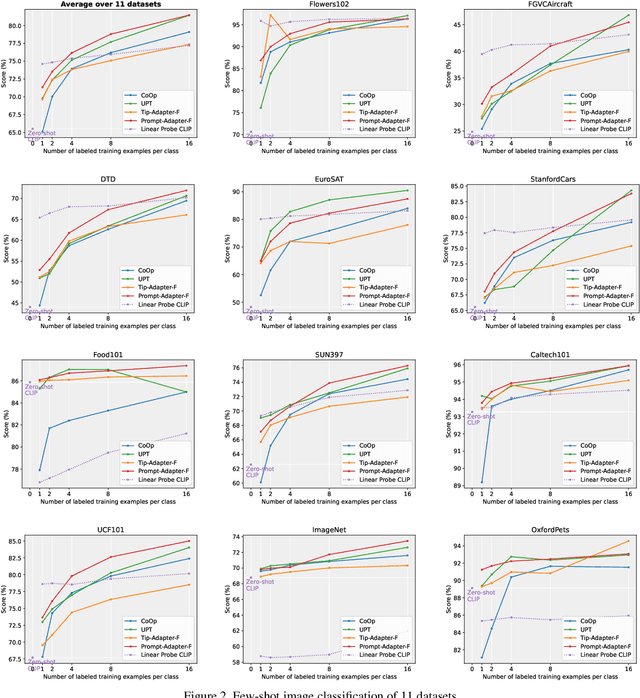
Large pre-trained vision-language (VL) models have shown significant promise in adapting to various downstream tasks. However, fine-tuning the entire network is challenging due to the massive number of model parameters. To address this issue, efficient adaptation methods such as prompt tuning have been proposed. We explore the idea of prompt tuning with multi-task pre-trained initialization and find it can significantly improve model performance. Based on our findings, we introduce a new model, termed Prompt-Adapter, that combines pre-trained prompt tunning with an efficient adaptation network. Our approach beat the state-of-the-art methods in few-shot image classification on the public 11 datasets, especially in settings with limited data instances such as 1 shot, 2 shots, 4 shots, and 8 shots images. Our proposed method demonstrates the promise of combining prompt tuning and parameter-efficient networks for efficient vision-language model adaptation. The code is publicly available at: https://github.com/Jingchensun/prompt_adapter.
Exploring Structured Semantic Prior for Multi Label Recognition with Incomplete Labels
Mar 24, 2023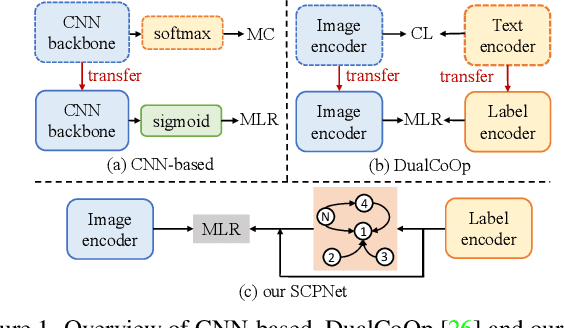
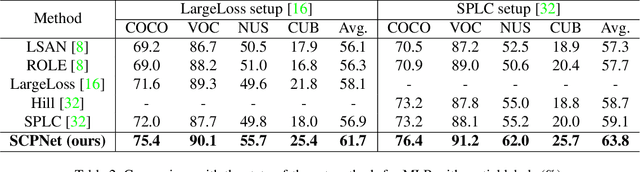
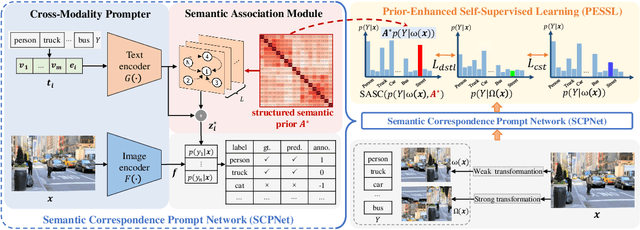
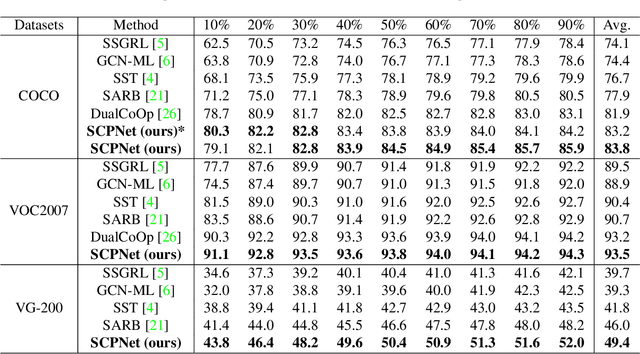
Multi-label recognition (MLR) with incomplete labels is very challenging. Recent works strive to explore the image-to-label correspondence in the vision-language model, \ie, CLIP, to compensate for insufficient annotations. In spite of promising performance, they generally overlook the valuable prior about the label-to-label correspondence. In this paper, we advocate remedying the deficiency of label supervision for the MLR with incomplete labels by deriving a structured semantic prior about the label-to-label correspondence via a semantic prior prompter. We then present a novel Semantic Correspondence Prompt Network (SCPNet), which can thoroughly explore the structured semantic prior. A Prior-Enhanced Self-Supervised Learning method is further introduced to enhance the use of the prior. Comprehensive experiments and analyses on several widely used benchmark datasets show that our method significantly outperforms existing methods on all datasets, well demonstrating the effectiveness and the superiority of our method. Our code will be available at https://github.com/jameslahm/SCPNet.
* Accepted by IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023
VQ3D: Learning a 3D-Aware Generative Model on ImageNet
Feb 14, 2023
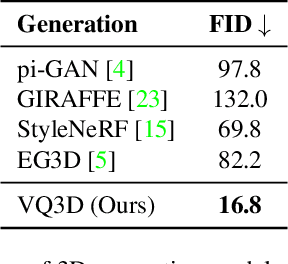
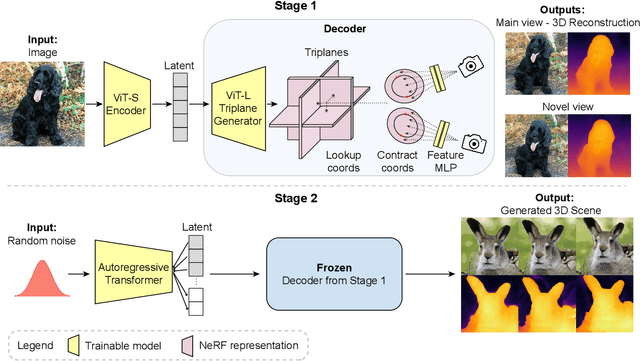
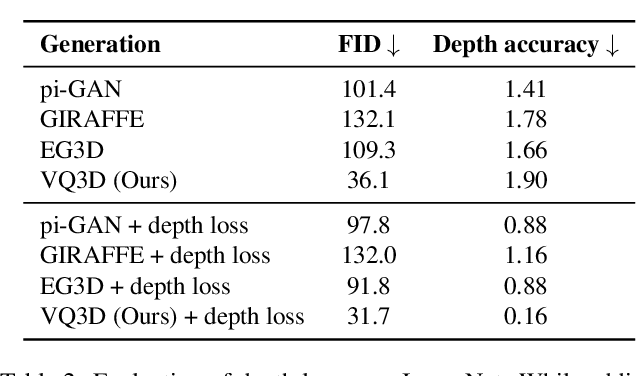
Recent work has shown the possibility of training generative models of 3D content from 2D image collections on small datasets corresponding to a single object class, such as human faces, animal faces, or cars. However, these models struggle on larger, more complex datasets. To model diverse and unconstrained image collections such as ImageNet, we present VQ3D, which introduces a NeRF-based decoder into a two-stage vector-quantized autoencoder. Our Stage 1 allows for the reconstruction of an input image and the ability to change the camera position around the image, and our Stage 2 allows for the generation of new 3D scenes. VQ3D is capable of generating and reconstructing 3D-aware images from the 1000-class ImageNet dataset of 1.2 million training images. We achieve an ImageNet generation FID score of 16.8, compared to 69.8 for the next best baseline method.
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Mar 26, 2023
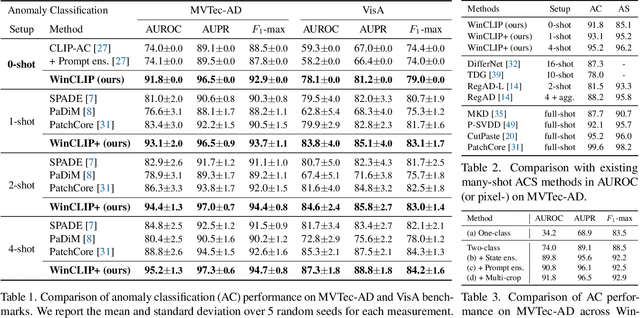

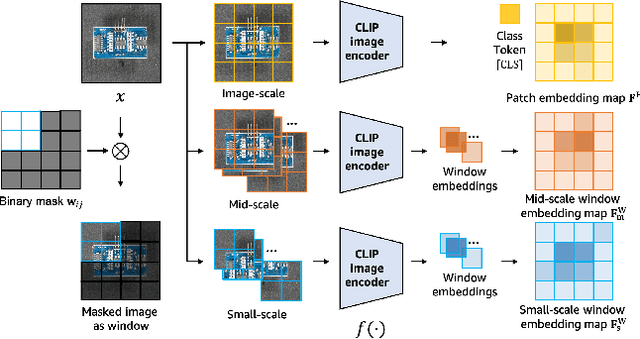
Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero-/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
Exploring Multimodal Sentiment Analysis via CBAM Attention and Double-layer BiLSTM Architecture
Mar 26, 2023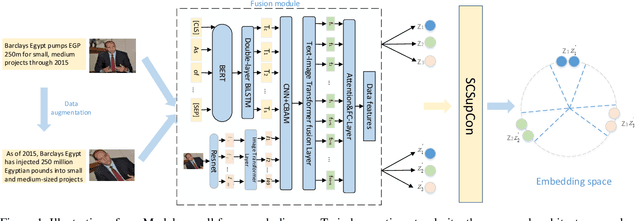
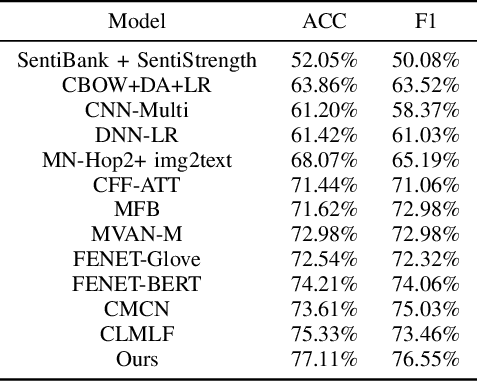
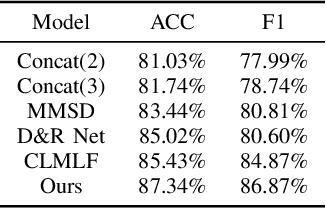
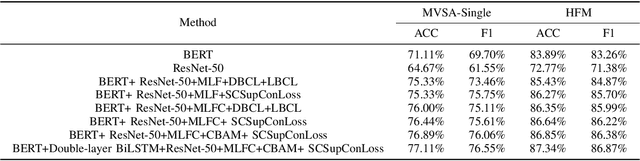
Because multimodal data contains more modal information, multimodal sentiment analysis has become a recent research hotspot. However, redundant information is easily involved in feature fusion after feature extraction, which has a certain impact on the feature representation after fusion. Therefore, in this papaer, we propose a new multimodal sentiment analysis model. In our model, we use BERT + BiLSTM as new feature extractor to capture the long-distance dependencies in sentences and consider the position information of input sequences to obtain richer text features. To remove redundant information and make the network pay more attention to the correlation between image and text features, CNN and CBAM attention are added after splicing text features and picture features, to improve the feature representation ability. On the MVSA-single dataset and HFM dataset, compared with the baseline model, the ACC of our model is improved by 1.78% and 1.91%, and the F1 value is enhanced by 3.09% and 2.0%, respectively. The experimental results show that our model achieves a sound effect, similar to the advanced model.
Geometry-Aware Attenuation Field Learning for Sparse-View CBCT Reconstruction
Mar 26, 2023
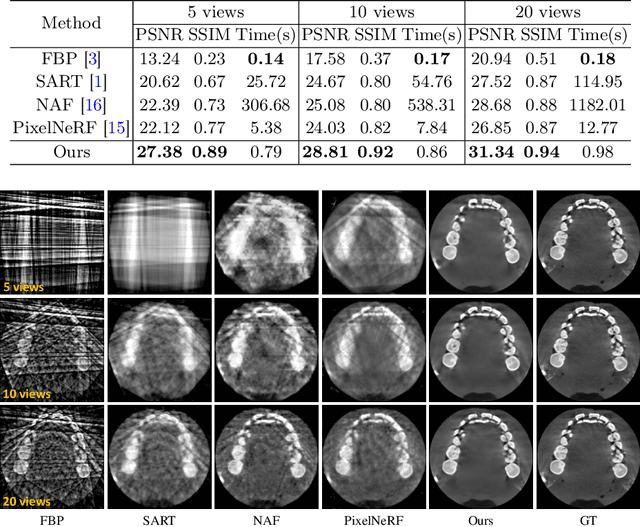
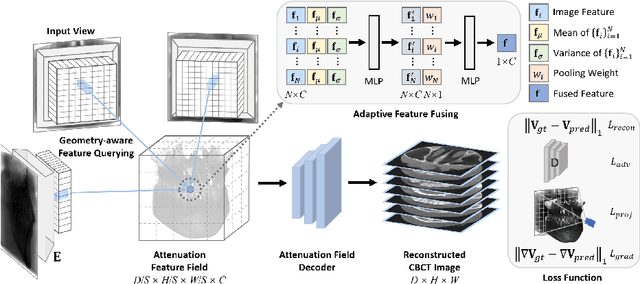
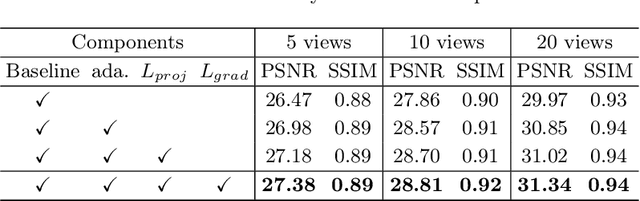
Cone Beam Computed Tomography (CBCT) is the most widely used imaging method in dentistry. As hundreds of X-ray projections are needed to reconstruct a high-quality CBCT image (i.e., the attenuation field) in traditional algorithms, sparse-view CBCT reconstruction has become a main focus to reduce radiation dose. Several attempts have been made to solve it while still suffering from insufficient data or poor generalization ability for novel patients. This paper proposes a novel attenuation field encoder-decoder framework by first encoding the volumetric feature from multi-view X-ray projections, then decoding it into the desired attenuation field. The key insight is when building the volumetric feature, we comply with the multi-view CBCT reconstruction nature and emphasize the view consistency property by geometry-aware spatial feature querying and adaptive feature fusing. Moreover, the prior knowledge information learned from data population guarantees our generalization ability when dealing with sparse view input. Comprehensive evaluations have demonstrated the superiority in terms of reconstruction quality, and the downstream application further validates the feasibility of our method in real-world clinics.
Semantic Neural Decoding via Cross-Modal Generation
Mar 26, 2023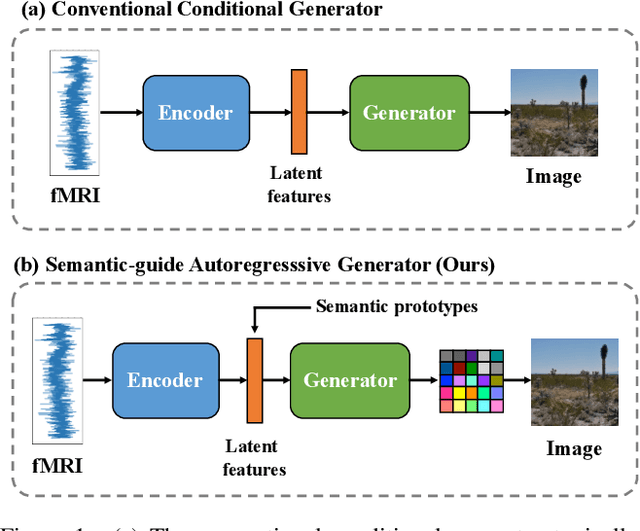

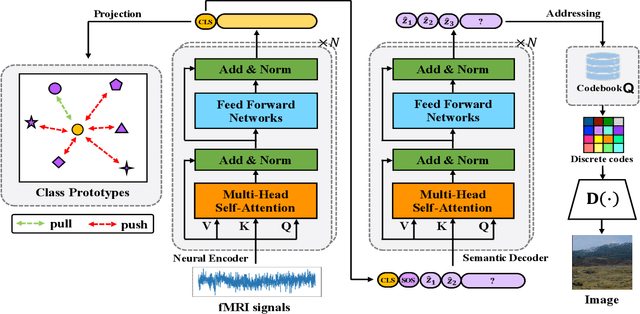
Semantic neural decoding aims to elucidate the cognitive processes of the human brain by reconstructing observed images from brain recordings. Although recent works have utilized deep generative models to generate images conditioned on fMRI signals, achieving high-quality generation with consistent semantics has proven to be a formidable challenge. To address this issue, we propose an end-to-end framework, SemanSig, which directly encodes fMRI signals and extracts semantic information. SemanSig leverages a deep generative model to decode the semantic information into high-quality images. To enhance the effectiveness of our framework, we use the ImageNet class prototype space as the internal representation space of fMRI signals, thereby reducing signal redundancy and learning difficulty. Consequently, this forms a semantic-rich and visually-friendly internal representation for generative models to decode. Notably, SemanSig does not require pre-training on a large fMRI dataset, and performs remarkably well when trained from scratch, even when the fMRI signal is limited. Our experimental results validate the effectiveness of SemanSig in achieving high-quality image generation with consistent semantics.
Visual Prompting via Image Inpainting
Sep 01, 2022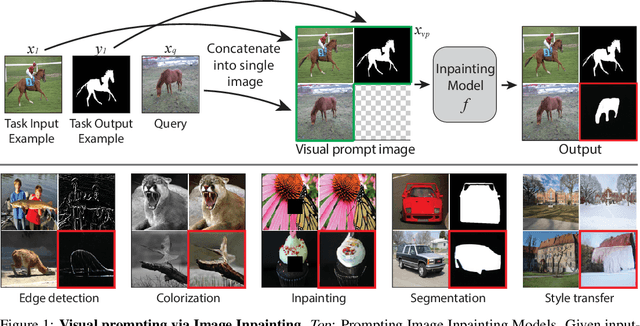
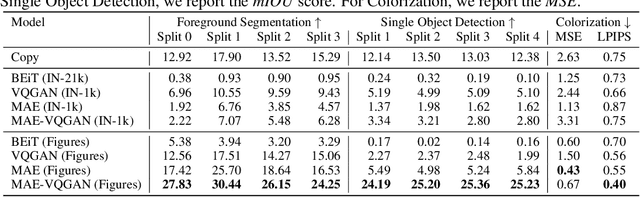
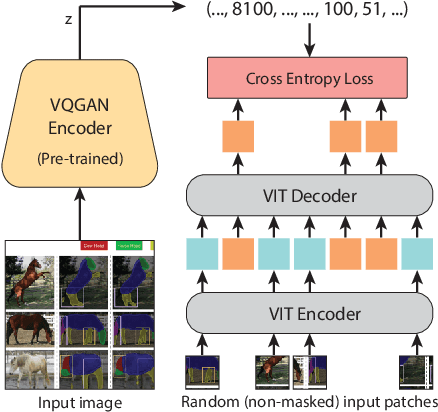
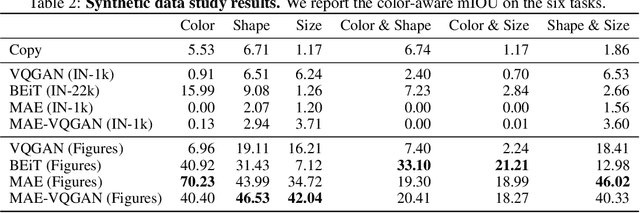
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the output image, consistent with the given examples. We show that posing this problem as simple image inpainting - literally just filling in a hole in a concatenated visual prompt image - turns out to be surprisingly effective, provided that the inpainting algorithm has been trained on the right data. We train masked auto-encoders on a new dataset that we curated - 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream image-to-image tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
Disorder-invariant Implicit Neural Representation
Apr 03, 2023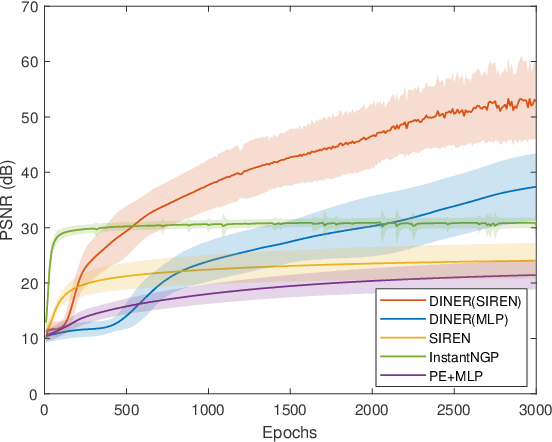
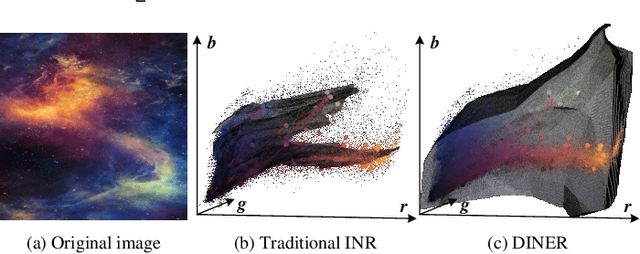
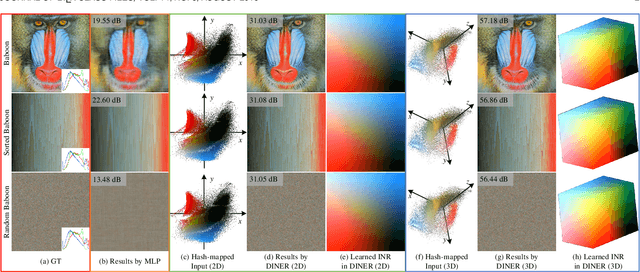
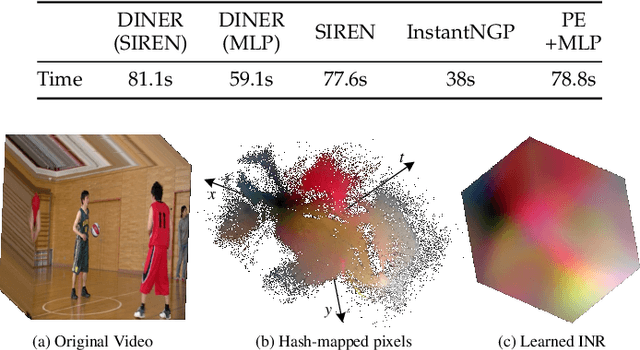
Implicit neural representation (INR) characterizes the attributes of a signal as a function of corresponding coordinates which emerges as a sharp weapon for solving inverse problems. However, the expressive power of INR is limited by the spectral bias in the network training. In this paper, we find that such a frequency-related problem could be greatly solved by re-arranging the coordinates of the input signal, for which we propose the disorder-invariant implicit neural representation (DINER) by augmenting a hash-table to a traditional INR backbone. Given discrete signals sharing the same histogram of attributes and different arrangement orders, the hash-table could project the coordinates into the same distribution for which the mapped signal can be better modeled using the subsequent INR network, leading to significantly alleviated spectral bias. Furthermore, the expressive power of the DINER is determined by the width of the hash-table. Different width corresponds to different geometrical elements in the attribute space, \textit{e.g.}, 1D curve, 2D curved-plane and 3D curved-volume when the width is set as $1$, $2$ and $3$, respectively. More covered areas of the geometrical elements result in stronger expressive power. Experiments not only reveal the generalization of the DINER for different INR backbones (MLP vs. SIREN) and various tasks (image/video representation, phase retrieval, refractive index recovery, and neural radiance field optimization) but also show the superiority over the state-of-the-art algorithms both in quality and speed. \textit{Project page:} \url{https://ezio77.github.io/DINER-website/}
Discovering and Explaining the Non-Causality of Deep Learning in SAR ATR
Apr 03, 2023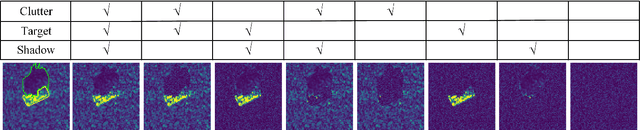
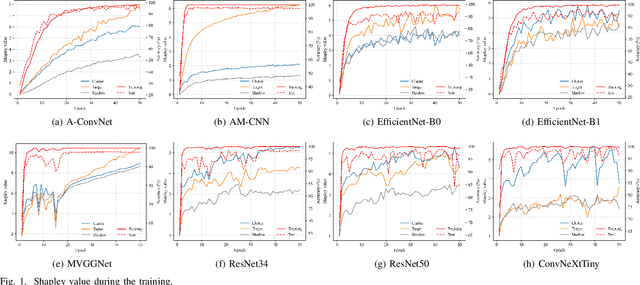
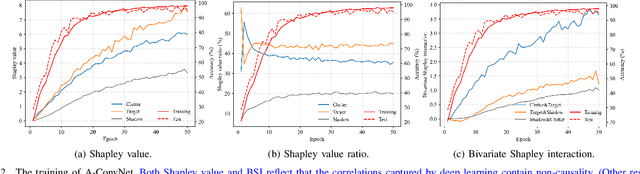
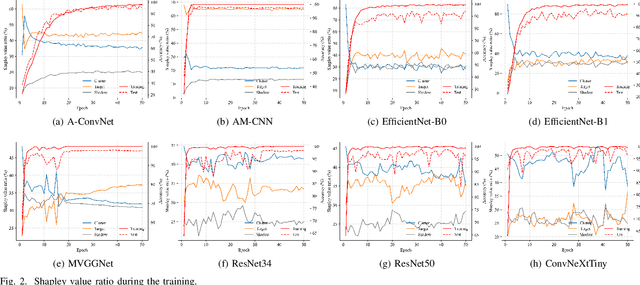
Synthetic aperture radar automatic target recognition (SAR ATR) is one of the critical technologies for SAR image interpretation, which has an important application prospect in military and civilian fields. Deep learning has been widely used in this area and achieved an excellent recognition rate on the benchmark dataset in recent years. However, the benchmark dataset suffers from data selection bias due to a single data collection condition. This data bias enhances deep learning models to overfit non-causal background clutter. Moreover, existing methods qualitatively analyze the model causality and do not deeply analyze this data bias. In this paper, we explicitly show that the data selection bias leads to the non-causality of the model and spurious correlation of clutter. First, we quantify the contribution of the target, clutter, and shadow regions during the training process through the Shapley value. The clutter contribution has a large proportion during the training process. Second, the causes of the non-causality of deep learning in SAR ATR include data selection bias and model texture bias. Data selection bias results in class-related clutter and false feature representation. Furthermore, the spurious correlation of clutter arises from the similar signal-to-clutter ratios (SCR) between the training and test sets. Finally, we propose a random SCR re-weighting method to reduce the overfitting for clutter. However, the model texture bias increases with model complexity after removing data bias. The experimental results of different models under the standard operating condition of the benchmark MSTAR dataset prove the above conclusions.