 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuron Populations Exhibit Divergent Selectivity with Scale
Jun 02, 2026We investigate whether neuron populations within neural networks evolve predictably with scale, extending scaling laws beyond macroscopic observables such as loss. To probe this question, we study Rosetta Neurons, a previously characterized class of neurons whose activation patterns are similar across independently trained models (Dravid et al., 2023). In separate analyses of language models up to 30B parameters and vision models up to 5B parameters, we observe that the population of Rosetta Neurons follows a sublinear power law in model size, growing in absolute number but occupying a shrinking fraction of the total neuron count. We further observe a Neuron Polarization Effect: Rosetta Neurons become more selective and increasingly monosemantic with scale, separating from a growing non-Rosetta population that remains less selective. An analytical model balancing feature utility against limited neuron capacity explains the sublinear power-law scaling and this polarization effect. Finally, we find that Rosetta Neurons become more domain-specialized with scale and illustrate their selectivity through a targeted data-filtering case study for continued pretraining. Our results point to a scaling law for interpretable, shared neuron-level structure, linking model size to systematic changes in neuron universality, selectivity, and specialization.
The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering
Mar 18, 2026We present a training-free framework for continuous and controllable image editing at test time for text-conditioned generative models. In contrast to prior approaches that rely on additional training or manual user intervention, we find that a simple steering in the text-embedding space is sufficient to produce smooth edit control. Given a target concept (e.g., enhancing photorealism or changing facial expression), we use a large language model to automatically construct a small set of debiased contrastive prompt pairs, from which we compute a steering vector in the generator's text-encoder space. We then add this vector directly to the input prompt representation to control generation along the desired semantic axis. To obtain a continuous control, we propose an elastic range search procedure that automatically identifies an effective interval of steering magnitudes, avoiding both under-steering (no-edit) and over-steering (changing other attributes). Adding the scaled versions of the same vector within this interval yields smooth and continuous edits. Since our method modifies only textual representations, it naturally generalizes across text-conditioned modalities, including image and video generation. To quantify the steering continuity, we introduce a new evaluation metric that measures the uniformity of semantic change across edit strengths. We compare the continuous editing behavior across methods and find that, despite its simplicity and lightweight design, our approach is comparable to training-based alternatives, outperforming other training-free methods.
Same Task, Different Circuits: Disentangling Modality-Specific Mechanisms in VLMs
Jun 11, 2025



Vision-Language models (VLMs) show impressive abilities to answer questions on visual inputs (e.g., counting objects in an image), yet demonstrate higher accuracies when performing an analogous task on text (e.g., counting words in a text). We investigate this accuracy gap by identifying and comparing the \textit{circuits} - the task-specific computational sub-graphs - in different modalities. We show that while circuits are largely disjoint between modalities, they implement relatively similar functionalities: the differences lie primarily in processing modality-specific data positions (an image or a text sequence). Zooming in on the image data representations, we observe they become aligned with the higher-performing analogous textual representations only towards later layers, too late in processing to effectively influence subsequent positions. To overcome this, we patch the representations of visual data tokens from later layers back into earlier layers. In experiments with multiple tasks and models, this simple intervention closes a third of the performance gap between the modalities, on average. Our analysis sheds light on the multi-modal performance gap in VLMs and suggests a training-free approach for reducing it.
Vision Transformers Don't Need Trained Registers
Jun 09, 2025



We investigate the mechanism underlying a previously identified phenomenon in Vision Transformers -- the emergence of high-norm tokens that lead to noisy attention maps. We observe that in multiple models (e.g., CLIP, DINOv2), a sparse set of neurons is responsible for concentrating high-norm activations on outlier tokens, leading to irregular attention patterns and degrading downstream visual processing. While the existing solution for removing these outliers involves retraining models from scratch with additional learned register tokens, we use our findings to create a training-free approach to mitigate these artifacts. By shifting the high-norm activations from our discovered register neurons into an additional untrained token, we can mimic the effect of register tokens on a model already trained without registers. We demonstrate that our method produces cleaner attention and feature maps, enhances performance over base models across multiple downstream visual tasks, and achieves results comparable to models explicitly trained with register tokens. We then extend test-time registers to off-the-shelf vision-language models to improve their interpretability. Our results suggest that test-time registers effectively take on the role of register tokens at test-time, offering a training-free solution for any pre-trained model released without them.
Steering CLIP's vision transformer with sparse autoencoders
Apr 11, 2025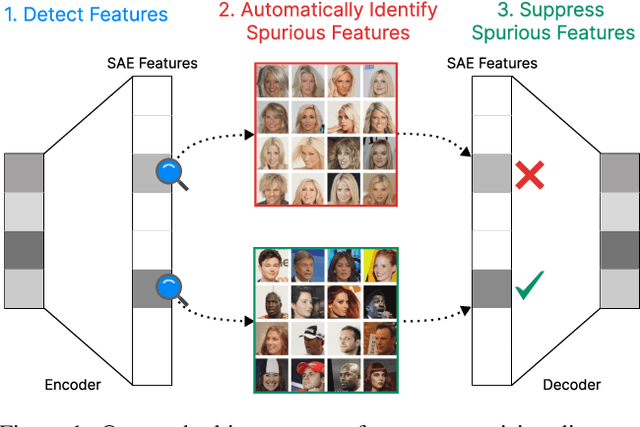
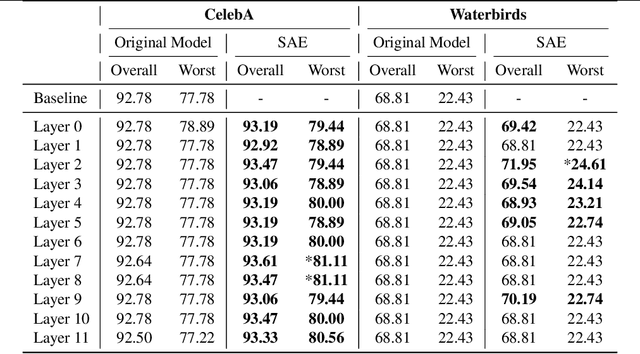

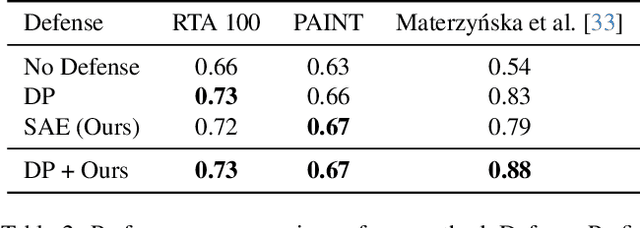
While vision models are highly capable, their internal mechanisms remain poorly understood -- a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP's vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP's vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model's output. We find that 10-15\% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.
Teaching Humans Subtle Differences with DIFFusion
Apr 10, 2025



Human expertise depends on the ability to recognize subtle visual differences, such as distinguishing diseases, species, or celestial phenomena. We propose a new method to teach novices how to differentiate between nuanced categories in specialized domains. Our method uses generative models to visualize the minimal change in features to transition between classes, i.e., counterfactuals, and performs well even in domains where data is sparse, examples are unpaired, and category boundaries are not easily explained by text. By manipulating the conditioning space of diffusion models, our proposed method DIFFusion disentangles category structure from instance identity, enabling high-fidelity synthesis even in challenging domains. Experiments across six domains show accurate transitions even with limited and unpaired examples across categories. User studies confirm that our generated counterfactuals outperform unpaired examples in teaching perceptual expertise, showing the potential of generative models for specialized visual learning.
Interpreting the Repeated Token Phenomenon in Large Language Models
Mar 11, 2025



Large Language Models (LLMs), despite their impressive capabilities, often fail to accurately repeat a single word when prompted to, and instead output unrelated text. This unexplained failure mode represents a vulnerability, allowing even end-users to diverge models away from their intended behavior. We aim to explain the causes for this phenomenon and link it to the concept of ``attention sinks'', an emergent LLM behavior crucial for fluency, in which the initial token receives disproportionately high attention scores. Our investigation identifies the neural circuit responsible for attention sinks and shows how long repetitions disrupt this circuit. We extend this finding to other non-repeating sequences that exhibit similar circuit disruptions. To address this, we propose a targeted patch that effectively resolves the issue without negatively impacting the model's overall performance. This study provides a mechanistic explanation for an LLM vulnerability, demonstrating how interpretability can diagnose and address issues, and offering insights that pave the way for more secure and reliable models.
LLMs can see and hear without any training
Jan 30, 2025



We present MILS: Multimodal Iterative LLM Solver, a surprisingly simple, training-free approach, to imbue multimodal capabilities into your favorite LLM. Leveraging their innate ability to perform multi-step reasoning, MILS prompts the LLM to generate candidate outputs, each of which are scored and fed back iteratively, eventually generating a solution to the task. This enables various applications that typically require training specialized models on task-specific data. In particular, we establish a new state-of-the-art on emergent zero-shot image, video and audio captioning. MILS seamlessly applies to media generation as well, discovering prompt rewrites to improve text-to-image generation, and even edit prompts for style transfer! Finally, being a gradient-free optimization approach, MILS can invert multimodal embeddings into text, enabling applications like cross-modal arithmetic.
An Empirical Study of Autoregressive Pre-training from Videos
Jan 09, 2025



We empirically study autoregressive pre-training from videos. To perform our study, we construct a series of autoregressive video models, called Toto. We treat videos as sequences of visual tokens and train transformer models to autoregressively predict future tokens. Our models are pre-trained on a diverse dataset of videos and images comprising over 1 trillion visual tokens. We explore different architectural, training, and inference design choices. We evaluate the learned visual representations on a range of downstream tasks including image recognition, video classification, object tracking, and robotics. Our results demonstrate that, despite minimal inductive biases, autoregressive pre-training leads to competitive performance across all benchmarks. Finally, we find that scaling our video models results in similar scaling curves to those seen in language models, albeit with a different rate. More details at https://brjathu.github.io/toto/
Learning Video Representations without Natural Videos
Oct 31, 2024



In this paper, we show that useful video representations can be learned from synthetic videos and natural images, without incorporating natural videos in the training. We propose a progression of video datasets synthesized by simple generative processes, that model a growing set of natural video properties (e.g. motion, acceleration, and shape transformations). The downstream performance of video models pre-trained on these generated datasets gradually increases with the dataset progression. A VideoMAE model pre-trained on our synthetic videos closes 97.2% of the performance gap on UCF101 action classification between training from scratch and self-supervised pre-training from natural videos, and outperforms the pre-trained model on HMDB51. Introducing crops of static images to the pre-training stage results in similar performance to UCF101 pre-training and outperforms the UCF101 pre-trained model on 11 out of 14 out-of-distribution datasets of UCF101-P. Analyzing the low-level properties of the datasets, we identify correlations between frame diversity, frame similarity to natural data, and downstream performance. Our approach provides a more controllable and transparent alternative to video data curation processes for pre-training.