 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Syntax-guided Post-training for Residential Floor Plan Generation
Feb 26, 2026Pre-trained generative models for residential floor plans are typically optimized to fit large-scale data distributions, which can under-emphasize critical architectural priors such as the configurational dominance and connectivity of domestic public spaces (e.g., living rooms and foyers). This paper proposes Space Syntax-guided Post-training (SSPT), a post-training paradigm that explicitly injects space syntax knowledge into floor plan generation via a non-differentiable oracle. The oracle converts RPLAN-style layouts into rectangle-space graphs through greedy maximal-rectangle decomposition and door-mediated adjacency construction, and then computes integration-based measurements to quantify public space dominance and functional hierarchy. To enable consistent evaluation and diagnosis, we further introduce SSPT-Bench (Eval-8), an out-of-distribution benchmark that post-trains models using conditions capped at $\leq 7$ rooms while evaluating on 8-room programs, together with a unified metric suite for dominance, stability, and profile alignment. SSPT is instantiated with two strategies: (i) iterative retraining via space-syntax filtering and diffusion fine-tuning, and (ii) reinforcement learning via PPO with space-syntax rewards. Experiments show that both strategies improve public-space dominance and restore clearer functional hierarchy compared to distribution-fitted baselines, while PPO achieves stronger gains with substantially higher compute efficiency and reduced variance. SSPT provides a scalable pathway for integrating architectural theory into data-driven plan generation and is compatible with other generative backbones given a post-hoc evaluation oracle.
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Mar 26, 2023Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero-/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation
Jul 28, 2022
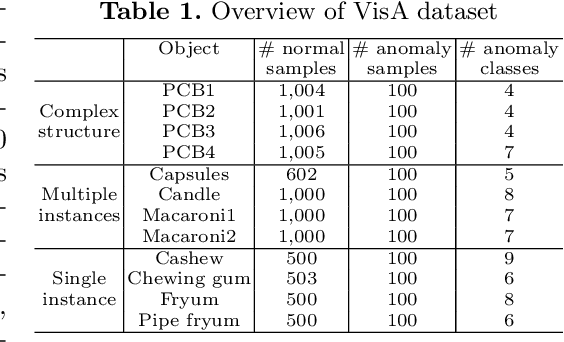
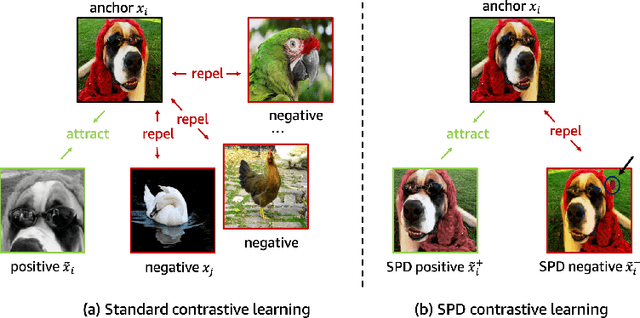
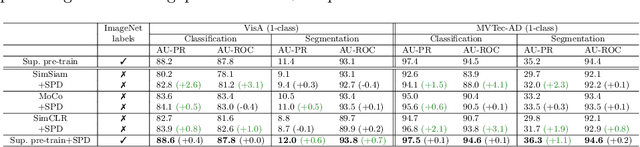
Visual anomaly detection is commonly used in industrial quality inspection. In this paper, we present a new dataset as well as a new self-supervised learning method for ImageNet pre-training to improve anomaly detection and segmentation in 1-class and 2-class 5/10/high-shot training setups. We release the Visual Anomaly (VisA) Dataset consisting of 10,821 high-resolution color images (9,621 normal and 1,200 anomalous samples) covering 12 objects in 3 domains, making it the largest industrial anomaly detection dataset to date. Both image and pixel-level labels are provided. We also propose a new self-supervised framework - SPot-the-difference (SPD) - which can regularize contrastive self-supervised pre-training, such as SimSiam, MoCo and SimCLR, to be more suitable for anomaly detection tasks. Our experiments on VisA and MVTec-AD dataset show that SPD consistently improves these contrastive pre-training baselines and even the supervised pre-training. For example, SPD improves Area Under the Precision-Recall curve (AU-PR) for anomaly segmentation by 5.9% and 6.8% over SimSiam and supervised pre-training respectively in the 2-class high-shot regime. We open-source the project at http://github.com/amazon-research/spot-diff .
Shot Contrastive Self-Supervised Learning for Scene Boundary Detection
Apr 28, 2021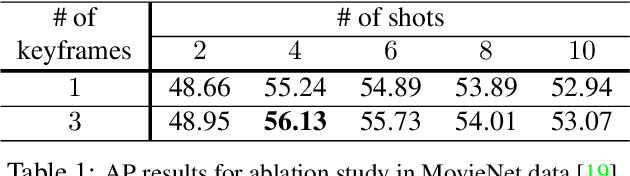
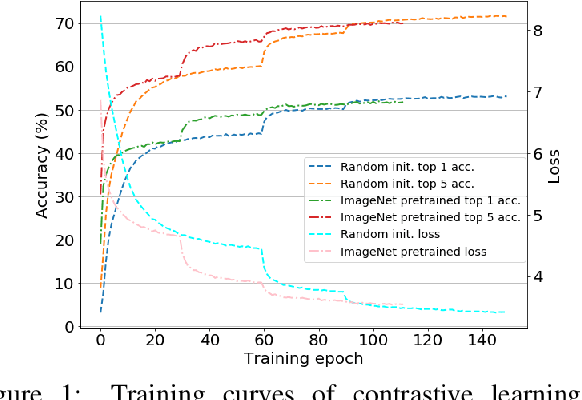

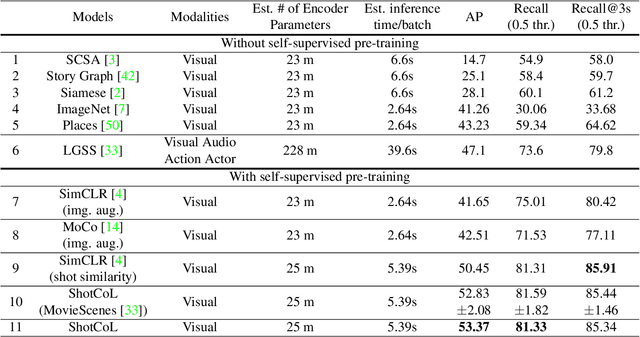
Scenes play a crucial role in breaking the storyline of movies and TV episodes into semantically cohesive parts. However, given their complex temporal structure, finding scene boundaries can be a challenging task requiring large amounts of labeled training data. To address this challenge, we present a self-supervised shot contrastive learning approach (ShotCoL) to learn a shot representation that maximizes the similarity between nearby shots compared to randomly selected shots. We show how to apply our learned shot representation for the task of scene boundary detection to offer state-of-the-art performance on the MovieNet dataset while requiring only ~25% of the training labels, using 9x fewer model parameters and offering 7x faster runtime. To assess the effectiveness of ShotCoL on novel applications of scene boundary detection, we take on the problem of finding timestamps in movies and TV episodes where video-ads can be inserted while offering a minimally disruptive viewing experience. To this end, we collected a new dataset called AdCuepoints with 3,975 movies and TV episodes, 2.2 million shots and 19,119 minimally disruptive ad cue-point labels. We present a thorough empirical analysis on this dataset demonstrating the effectiveness of ShotCoL for ad cue-points detection.
A multi-level convolutional LSTM model for the segmentation of left ventricle myocardium in infarcted porcine cine MR images
Nov 14, 2018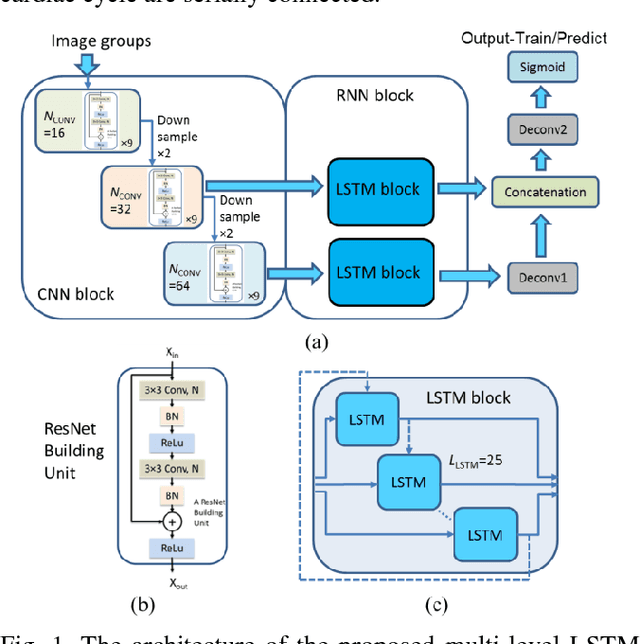
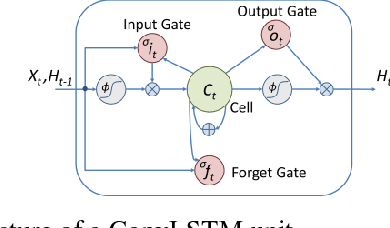
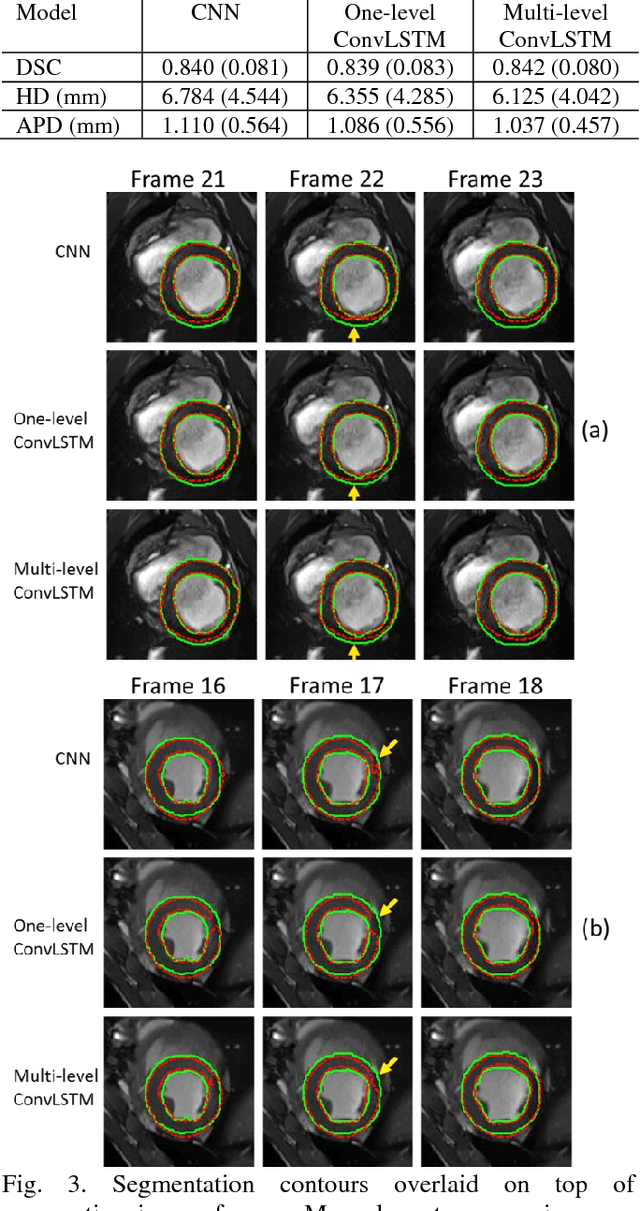
Automatic segmentation of left ventricle (LV) myocardium in cardiac short-axis cine MR images acquired on subjects with myocardial infarction is a challenging task, mainly because of the various types of image inhomogeneity caused by the infarctions. Among the approaches proposed to automate the LV myocardium segmentation task, methods based upon deep convolutional neural networks (CNN) have demonstrated their exceptional accuracy and robustness in recent years. However, most of the CNN-based approaches treat the frames in a cardiac cycle independently, which fails to capture the valuable dynamics of heart motion. Herein, an approach based on recurrent neural network (RNN), specifically a multi-level convolutional long short-term memory (ConvLSTM) model, is proposed to take the motion of the heart into consideration. Based on a ResNet-56 CNN, LV-related image features in consecutive frames of a cardiac cycle are extracted at both the low- and high-resolution levels, which are processed by the corresponding multi-level ConvLSTM models to generate the myocardium segmentations. A leave-one-out experiment was carried out on a set of 3,600 cardiac cine MR slices collected in-house for 8 porcine subjects with surgically induced myocardial infarction. Compared with a solely CNN-based approach, the proposed approach demonstrated its superior robustness against image inhomogeneity by incorporating information from adjacent frames. It also outperformed a one-level ConvLSTM approach thanks to its capabilities to take advantage of image features at multiple resolution levels.
LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks
Jul 26, 2018
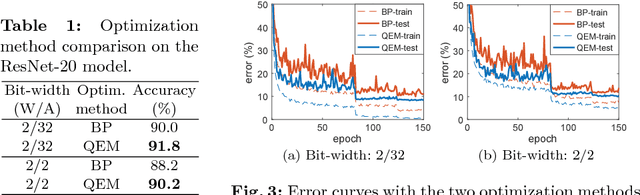
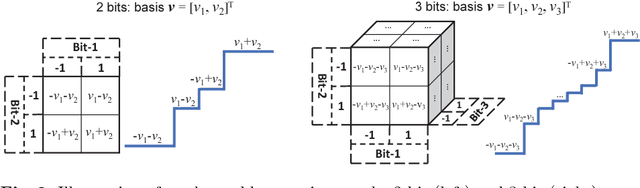
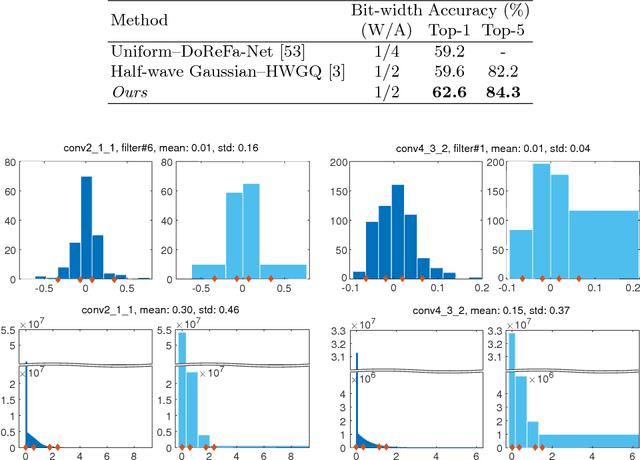
Although weight and activation quantization is an effective approach for Deep Neural Network (DNN) compression and has a lot of potentials to increase inference speed leveraging bit-operations, there is still a noticeable gap in terms of prediction accuracy between the quantized model and the full-precision model. To address this gap, we propose to jointly train a quantized, bit-operation-compatible DNN and its associated quantizers, as opposed to using fixed, handcrafted quantization schemes such as uniform or logarithmic quantization. Our method for learning the quantizers applies to both network weights and activations with arbitrary-bit precision, and our quantizers are easy to train. The comprehensive experiments on CIFAR-10 and ImageNet datasets show that our method works consistently well for various network structures such as AlexNet, VGG-Net, GoogLeNet, ResNet, and DenseNet, surpassing previous quantization methods in terms of accuracy by an appreciable margin. Code available at https://github.com/Microsoft/LQ-Nets
Accurate Detection of Inner Ears in Head CTs Using a Deep Volume-to-Volume Regression Network with False Positive Suppression and a Shape-Based Constraint
Jun 12, 2018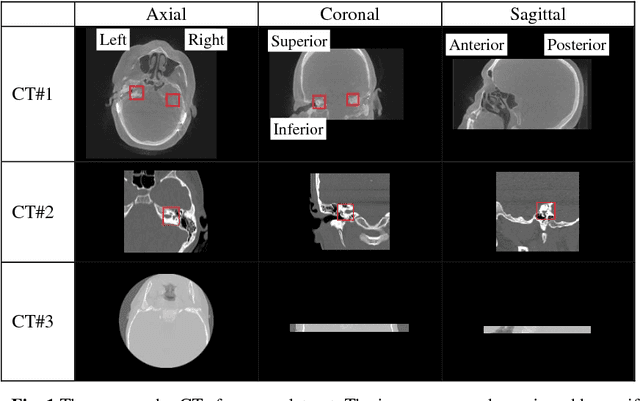
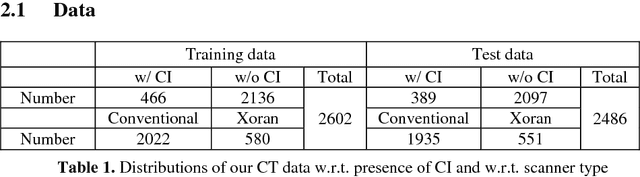
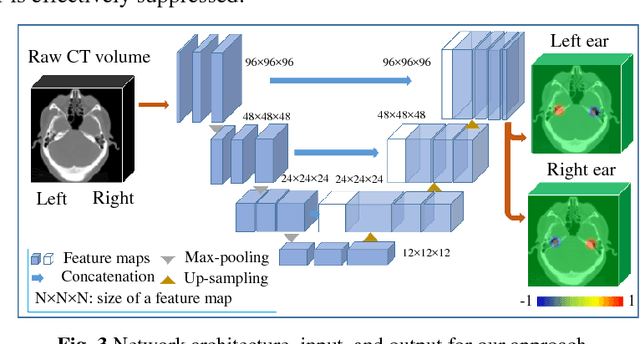
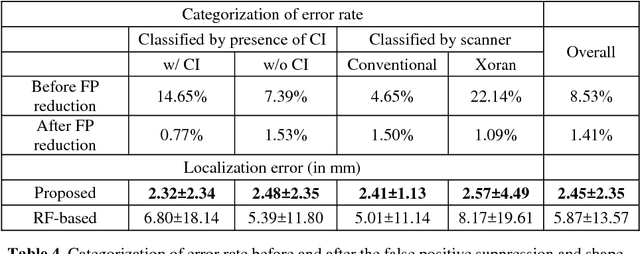
Cochlear implants (CIs) are neural prosthetics which are used to treat patients with hearing loss. CIs use an array of electrodes which are surgically inserted into the cochlea to stimulate the auditory nerve endings. After surgery, CIs need to be programmed. Studies have shown that the spatial relationship between the intra-cochlear anatomy and electrodes derived from medical images can guide CI programming and lead to significant improvement in hearing outcomes. However, clinical head CT images are usually obtained from scanners of different brands with different protocols. The field of view thus varies greatly and visual inspection is needed to document their content prior to applying algorithms for electrode localization and intra-cochlear anatomy segmentation. In this work, to determine the presence/absence of inner ears and to accurately localize them in head CTs, we use a volume-to-volume convolutional neural network which can be trained end-to-end to map a raw CT volume to probability maps which indicate inner ear positions. We incorporate a false positive suppression strategy in training and apply a shape-based constraint. We achieve a labeling accuracy of 98.59% and a localization error of 2.45mm. The localization error is significantly smaller than a random forest-based approach that has been proposed recently to perform the same task.
Neural Aggregation Network for Video Face Recognition
Aug 02, 2017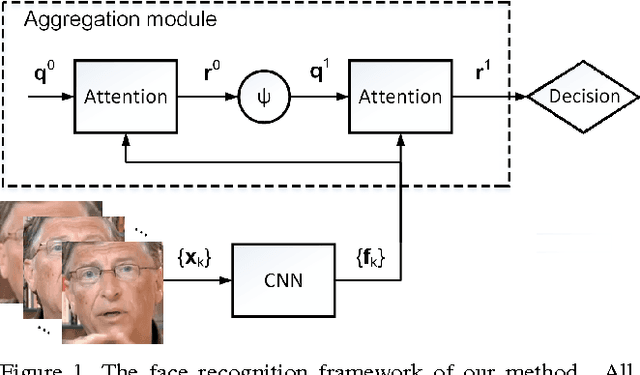
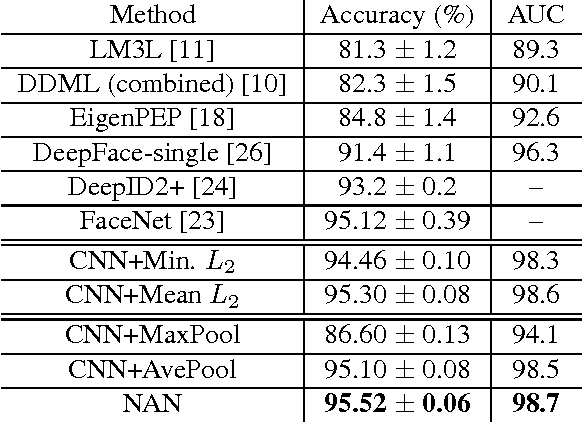
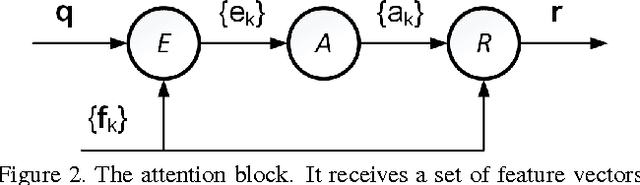
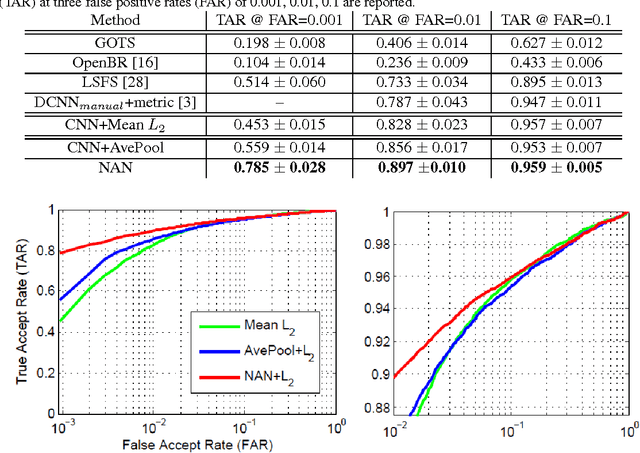
This paper presents a Neural Aggregation Network (NAN) for video face recognition. The network takes a face video or face image set of a person with a variable number of face images as its input, and produces a compact, fixed-dimension feature representation for recognition. The whole network is composed of two modules. The feature embedding module is a deep Convolutional Neural Network (CNN) which maps each face image to a feature vector. The aggregation module consists of two attention blocks which adaptively aggregate the feature vectors to form a single feature inside the convex hull spanned by them. Due to the attention mechanism, the aggregation is invariant to the image order. Our NAN is trained with a standard classification or verification loss without any extra supervision signal, and we found that it automatically learns to advocate high-quality face images while repelling low-quality ones such as blurred, occluded and improperly exposed faces. The experiments on IJB-A, YouTube Face, Celebrity-1000 video face recognition benchmarks show that it consistently outperforms naive aggregation methods and achieves the state-of-the-art accuracy.
Counting Grid Aggregation for Event Retrieval and Recognition
Oct 11, 2016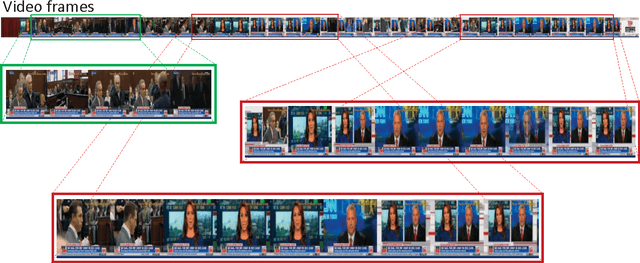

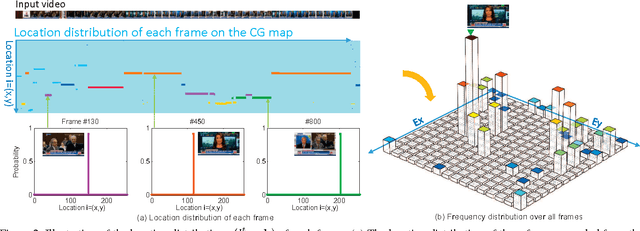
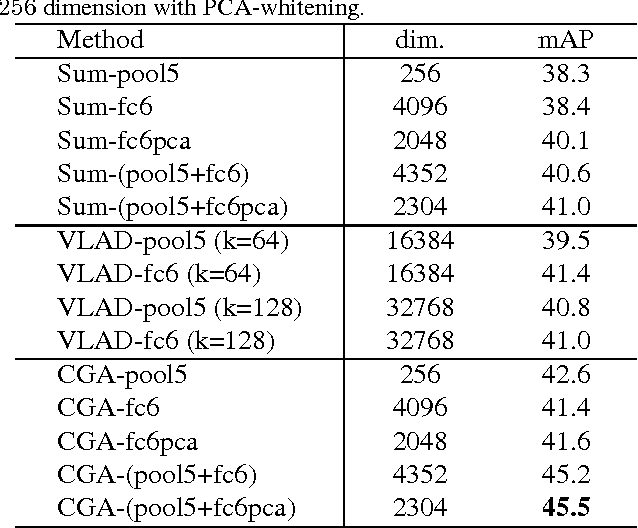
Event retrieval and recognition in a large corpus of videos necessitates a holistic fixed-size visual representation at the video clip level that is comprehensive, compact, and yet discriminative. It shall comprehensively aggregate information across relevant video frames, while suppress redundant information, leading to a compact representation that can effectively differentiate among different visual events. In search for such a representation, we propose to build a spatially consistent counting grid model to aggregate together deep features extracted from different video frames. The spatial consistency of the counting grid model is achieved by introducing a prior model estimated from a large corpus of video data. The counting grid model produces an intermediate tensor representation for each video, which automatically identifies and removes the feature redundancy across the different frames. The tensor representation is subsequently reduced to a fixed-size vector representation by averaging over the counting grid. When compared to existing methods on both event retrieval and event classification benchmarks, we achieve significantly better accuracy with much more compact representation.