 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANDEM: Bi-Level Data Mixture Optimization with Twin Networks
Jun 03, 2026The capabilities of large language models (LLMs) significantly depend on training data drawn from various domains. Optimizing domain-specific mixture ratios can be modeled as a bi-level optimization problem, which we simplify into a single-level penalized form and solve with twin networks: a proxy model trained on primary data and a dynamically updated reference model trained with additional data. Our proposed method, Twin Networks for bi-level DatA mixturE optiMization (TANDEM), measures the data efficacy through the difference between the twin models and up-weights domains that benefit more from the additional data. TANDEM provides theoretical guarantees and wider applicability, compared to prior approaches. Furthermore, our bi-level perspective suggests new settings to study domain reweighting such as data-restricted scenarios and supervised fine-tuning, where optimized mixture ratios significantly improve the performance. Extensive experiments validate TANDEM's effectiveness in all scenarios.
Spectral Disentanglement and Enhancement: A Dual-domain Contrastive Framework for Representation Learning
Feb 09, 2026Large-scale multimodal contrastive learning has recently achieved impressive success in learning rich and transferable representations, yet it remains fundamentally limited by the uniform treatment of feature dimensions and the neglect of the intrinsic spectral structure of the learned features. Empirical evidence indicates that high-dimensional embeddings tend to collapse into narrow cones, concentrating task-relevant semantics in a small subspace, while the majority of dimensions remain occupied by noise and spurious correlations. Such spectral imbalance and entanglement undermine model generalization. We propose Spectral Disentanglement and Enhancement (SDE), a novel framework that bridges the gap between the geometry of the embedded spaces and their spectral properties. Our approach leverages singular value decomposition to adaptively partition feature dimensions into strong signals that capture task-critical semantics, weak signals that reflect ancillary correlations, and noise representing irrelevant perturbations. A curriculum-based spectral enhancement strategy is then applied, selectively amplifying informative components with theoretical guarantees on training stability. Building upon the enhanced features, we further introduce a dual-domain contrastive loss that jointly optimizes alignment in both the feature and spectral spaces, effectively integrating spectral regularization into the training process and encouraging richer, more robust representations. Extensive experiments on large-scale multimodal benchmarks demonstrate that SDE consistently improves representation robustness and generalization, outperforming state-of-the-art methods. SDE integrates seamlessly with existing contrastive pipelines, offering an effective solution for multimodal representation learning.
The Primacy of Magnitude in Low-Rank Adaptation
Jul 09, 2025Low-Rank Adaptation (LoRA) offers a parameter-efficient paradigm for tuning large models. While recent spectral initialization methods improve convergence and performance over the naive "Noise & Zeros" scheme, their extra computational and storage overhead undermines efficiency. In this paper, we establish update magnitude as the fundamental driver of LoRA performance and propose LoRAM, a magnitude-driven "Basis & Basis" initialization scheme that matches spectral methods without their inefficiencies. Our key contributions are threefold: (i) Magnitude of weight updates determines convergence. We prove low-rank structures intrinsically bound update magnitudes, unifying hyperparameter tuning in learning rate, scaling factor, and initialization as mechanisms to optimize magnitude regulation. (ii) Spectral initialization succeeds via magnitude amplification. We demystify that the presumed knowledge-driven benefit of the spectral component essentially arises from the boost in the weight update magnitude. (iii) A novel and compact initialization strategy, LoRAM, scales deterministic orthogonal bases using pretrained weight magnitudes to simulate spectral gains. Extensive experiments show that LoRAM serves as a strong baseline, retaining the full efficiency of LoRA while matching or outperforming spectral initialization across benchmarks.
DiscoVLA: Discrepancy Reduction in Vision, Language, and Alignment for Parameter-Efficient Video-Text Retrieval
Jun 10, 2025The parameter-efficient adaptation of the image-text pretraining model CLIP for video-text retrieval is a prominent area of research. While CLIP is focused on image-level vision-language matching, video-text retrieval demands comprehensive understanding at the video level. Three key discrepancies emerge in the transfer from image-level to video-level: vision, language, and alignment. However, existing methods mainly focus on vision while neglecting language and alignment. In this paper, we propose Discrepancy Reduction in Vision, Language, and Alignment (DiscoVLA), which simultaneously mitigates all three discrepancies. Specifically, we introduce Image-Video Features Fusion to integrate image-level and video-level features, effectively tackling both vision and language discrepancies. Additionally, we generate pseudo image captions to learn fine-grained image-level alignment. To mitigate alignment discrepancies, we propose Image-to-Video Alignment Distillation, which leverages image-level alignment knowledge to enhance video-level alignment. Extensive experiments demonstrate the superiority of our DiscoVLA. In particular, on MSRVTT with CLIP (ViT-B/16), DiscoVLA outperforms previous methods by 1.5% in R@1, reaching a final score of 50.5% R@1. The code is available at https://github.com/LunarShen/DsicoVLA.
FastVID: Dynamic Density Pruning for Fast Video Large Language Models
Mar 14, 2025



Video Large Language Models have shown impressive capabilities in video comprehension, yet their practical deployment is hindered by substantial inference costs caused by redundant video tokens. Existing pruning techniques fail to fully exploit the spatiotemporal redundancy inherent in video data. To bridge this gap, we perform a systematic analysis of video redundancy from two perspectives: temporal context and visual context. Leveraging this insight, we propose Dynamic Density Pruning for Fast Video LLMs termed FastVID. Specifically, FastVID dynamically partitions videos into temporally ordered segments to preserve temporal structure and applies a density-based token pruning strategy to maintain essential visual information. Our method significantly reduces computational overhead while maintaining temporal and visual integrity. Extensive evaluations show that FastVID achieves state-of-the-art performance across various short- and long-video benchmarks on leading Video LLMs, including LLaVA-OneVision and LLaVA-Video. Notably, FastVID effectively prunes 90% of video tokens while retaining 98.0% of LLaVA-OneVision's original performance. The code is available at https://github.com/LunarShen/FastVID.
LLaVA-MLB: Mitigating and Leveraging Attention Bias for Training-Free Video LLMs
Mar 14, 2025



Training-free video large language models (LLMs) leverage pretrained Image LLMs to process video content without the need for further training. A key challenge in such approaches is the difficulty of retaining essential visual and temporal information, constrained by the token limits in Image LLMs. To address this, we propose a two-stage method for selecting query-relevant tokens based on the LLM attention scores: compressing the video sequence and then expanding the sequence. However, during the compression stage, Image LLMs often exhibit a positional attention bias in video sequences, where attention is overly concentrated on later frames, causing early-frame information to be underutilized. To alleviate this attention bias during sequence compression, we propose Gridded Attention Pooling for preserving spatiotemporal structure. Additionally, we introduce Visual Summarization Tail to effectively utilize this bias, facilitating overall video understanding during sequence expansion. In this way, our method effectively Mitigates and Leverages attention Bias (LLaVA-MLB), enabling the frozen Image LLM for detailed video understanding. Experiments on several benchmarks demonstrate that our approach outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. Our code will be released.
TempMe: Video Temporal Token Merging for Efficient Text-Video Retrieval
Sep 02, 2024Most text-video retrieval methods utilize the text-image pre-trained CLIP as a backbone, incorporating complex modules that result in high computational overhead. As a result, many studies focus on efficient fine-tuning. The primary challenge in efficient adaption arises from the inherent differences between image and video modalities. Each sampled video frame must be processed by the image encoder independently, which increases complexity and complicates practical deployment. Although existing efficient methods fine-tune with small trainable parameters, they still incur high inference costs due to the large token number. In this work, we argue that temporal redundancy significantly contributes to the model's high complexity due to the repeated information in consecutive frames. Existing token compression methods for image models fail to solve the unique challenges, as they overlook temporal redundancy across frames. To tackle these problems, we propose Temporal Token Merging (TempMe) to reduce temporal redundancy. Specifically, we introduce a progressive multi-granularity framework. By gradually combining neighboring clips, we merge temporal tokens across different frames and learn video-level features, leading to lower complexity and better performance. Extensive experiments validate the superiority of our TempMe. Compared to previous efficient text-video retrieval methods, TempMe significantly reduces output tokens by 95% and GFLOPs by 51%, while achieving a 1.8X speedup and a 4.4% R-Sum improvement. Additionally, TempMe exhibits robust generalization capabilities by integrating effectively with both efficient and full fine-tuning methods. With full fine-tuning, TempMe achieves a significant 7.9% R-Sum improvement, trains 1.57X faster, and utilizes 75.2% GPU memory usage. Our code will be released.
Exploring Structured Semantic Prior for Multi Label Recognition with Incomplete Labels
Mar 24, 2023



Multi-label recognition (MLR) with incomplete labels is very challenging. Recent works strive to explore the image-to-label correspondence in the vision-language model, \ie, CLIP, to compensate for insufficient annotations. In spite of promising performance, they generally overlook the valuable prior about the label-to-label correspondence. In this paper, we advocate remedying the deficiency of label supervision for the MLR with incomplete labels by deriving a structured semantic prior about the label-to-label correspondence via a semantic prior prompter. We then present a novel Semantic Correspondence Prompt Network (SCPNet), which can thoroughly explore the structured semantic prior. A Prior-Enhanced Self-Supervised Learning method is further introduced to enhance the use of the prior. Comprehensive experiments and analyses on several widely used benchmark datasets show that our method significantly outperforms existing methods on all datasets, well demonstrating the effectiveness and the superiority of our method. Our code will be available at https://github.com/jameslahm/SCPNet.
* Accepted by IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023
Prompt Tuning with Soft Context Sharing for Vision-Language Models
Aug 29, 2022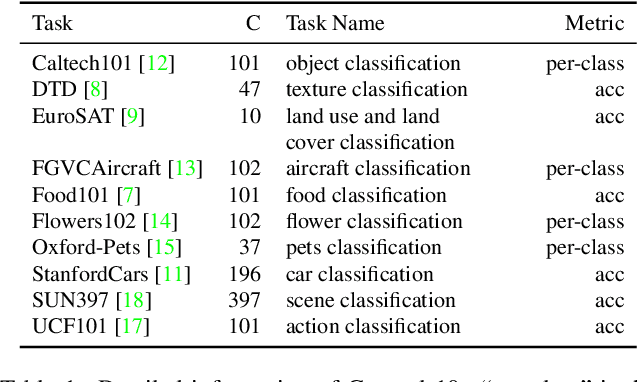
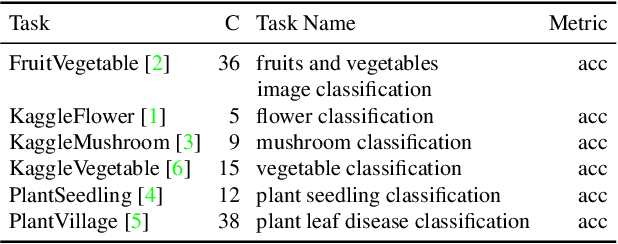

Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.