 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Roadmap on Deep Learning for Microscopy
Mar 07, 2023
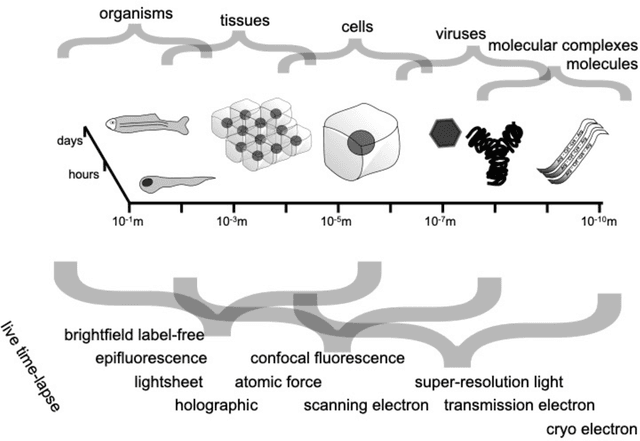
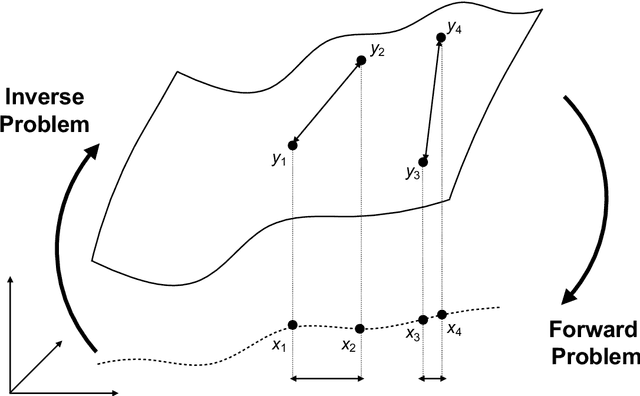
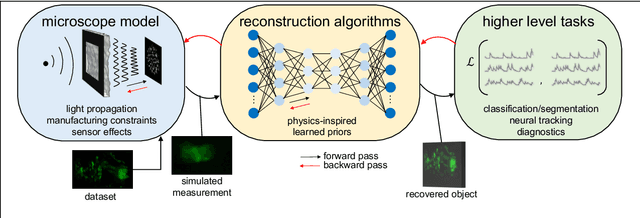

Through digital imaging, microscopy has evolved from primarily being a means for visual observation of life at the micro- and nano-scale, to a quantitative tool with ever-increasing resolution and throughput. Artificial intelligence, deep neural networks, and machine learning are all niche terms describing computational methods that have gained a pivotal role in microscopy-based research over the past decade. This Roadmap is written collectively by prominent researchers and encompasses selected aspects of how machine learning is applied to microscopy image data, with the aim of gaining scientific knowledge by improved image quality, automated detection, segmentation, classification and tracking of objects, and efficient merging of information from multiple imaging modalities. We aim to give the reader an overview of the key developments and an understanding of possibilities and limitations of machine learning for microscopy. It will be of interest to a wide cross-disciplinary audience in the physical sciences and life sciences.
Multi Modal Facial Expression Recognition with Transformer-Based Fusion Networks and Dynamic Sampling
Mar 19, 2023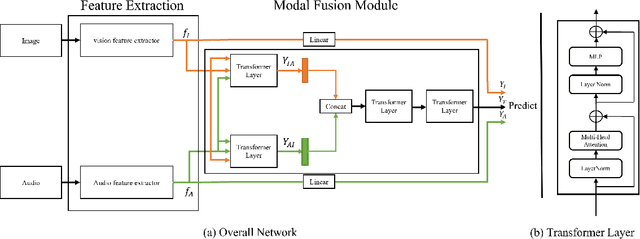
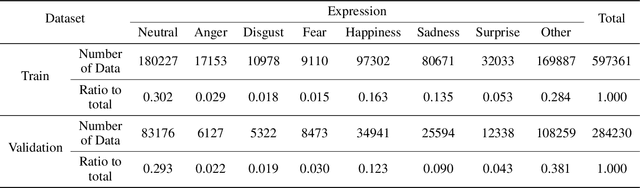
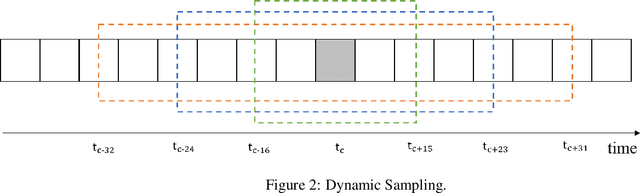
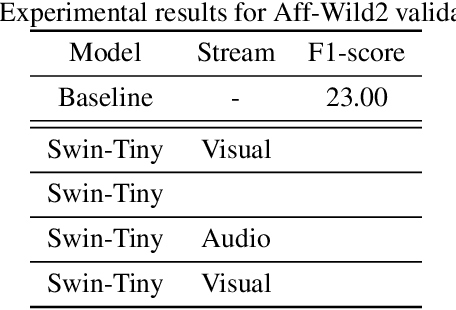
Facial expression recognition is an essential task for various applications, including emotion detection, mental health analysis, and human-machine interactions. In this paper, we propose a multi-modal facial expression recognition method that exploits audio information along with facial images to provide a crucial clue to differentiate some ambiguous facial expressions. Specifically, we introduce a Modal Fusion Module (MFM) to fuse audio-visual information, where image and audio features are extracted from Swin Transformer. Additionally, we tackle the imbalance problem in the dataset by employing dynamic data resampling. Our model has been evaluated in the Affective Behavior in-the-wild (ABAW) challenge of CVPR 2023.
RemoteTouch: Enhancing Immersive 3D Video Communication with Hand Touch
Feb 28, 2023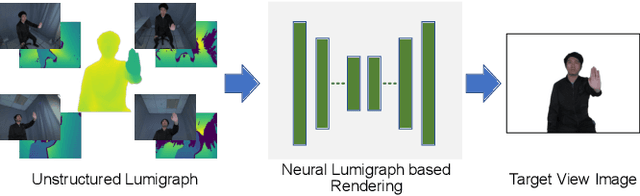

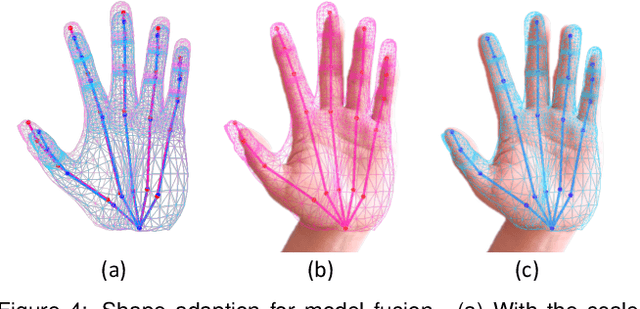

Recent research advance has significantly improved the visual realism of immersive 3D video communication. In this work we present a method to further enhance this immersive experience by adding the hand touch capability ("remote hand clapping"). In our system, each meeting participant sits in front of a large screen with haptic feedback. The local participant can reach his hand out to the screen and perform hand clapping with the remote participant as if the two participants were only separated by a virtual glass. A key challenge in emulating the remote hand touch is the realistic rendering of the participant's hand and arm as the hand touches the screen. When the hand is very close to the screen, the RGBD data required for realistic rendering is no longer available. To tackle this challenge, we present a dual representation of the user's hand. Our dual representation not only preserves the high-quality rendering usually found in recent image-based rendering systems but also allows the hand to reach the screen. This is possible because the dual representation includes both an image-based model and a 3D geometry-based model, with the latter driven by a hand skeleton tracked by a side view camera. In addition, the dual representation provides a distance-based fusion of the image-based and 3D geometry-based models as the hand moves closer to the screen. The result is that the image-based and 3D geometry-based models mutually enhance each other, leading to realistic and seamless rendering. Our experiments demonstrate that our method provides consistent hand contact experience between remote users and improves the immersive experience of 3D video communication.
Towards Enhanced Controllability of Diffusion Models
Feb 28, 2023
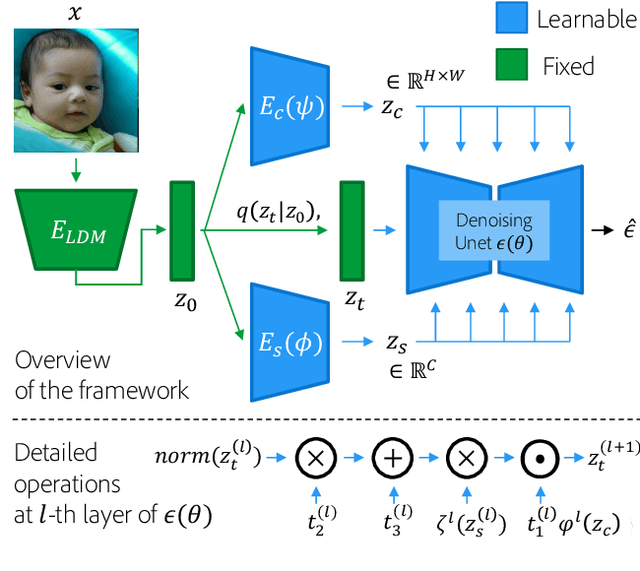
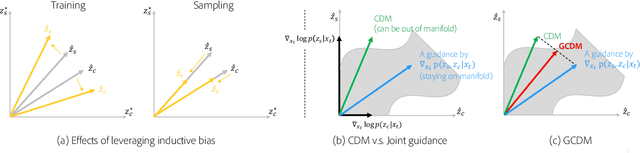

Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability and editability with diffusion models is underexplored relative to GANs. Inspired by techniques based on the latent space of GAN models for image manipulation, we propose to train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We extend the sampling technique from composable diffusion models to allow for some dependence between conditional inputs. This improves the quality of the generations significantly while also providing control over the amount of guidance from each latent code separately as well as from their joint distribution. To further enhance controllability, we vary the level of guidance for structure and style latents based on the denoising timestep. We observe more controllability compared to existing methods and show that without explicit training objectives, diffusion models can be leveraged for effective image manipulation, reference based image translation and style transfer.
SLLEN: Semantic-aware Low-light Image Enhancement Network
Nov 21, 2022
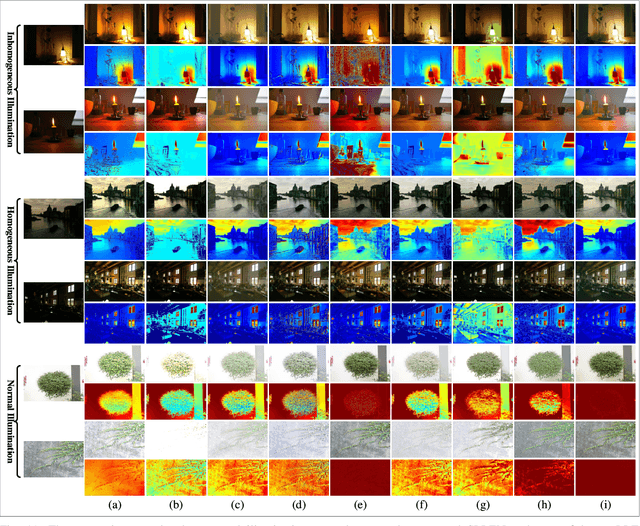

How to effectively explore semantic feature is vital for low-light image enhancement (LLE). Existing methods usually utilize the semantic feature that is only drawn from the semantic map produced by high-level semantic segmentation network (SSN). However, if the semantic map is not accurately estimated, it would affect the high-level semantic feature (HSF) extraction, which accordingly interferes with LLE. In this paper, we develop a simple yet effective two-branch semantic-aware LLE network (SLLEN) that neatly integrates the random intermediate embedding feature (IEF) (i.e., the information extracted from the intermediate layer of semantic segmentation network) together with the HSF into a unified framework for better LLE. Specifically, for one branch, we utilize an attention mechanism to integrate HSF into low-level feature. For the other branch, we extract IEF to guide the adjustment of low-level feature using nonlinear transformation manner. Finally, semantic-aware features obtained from two branches are fused and decoded for image enhancement. It is worth mentioning that IEF has some randomness compared to HSF despite their similarity on semantic characteristics, thus its introduction can allow network to learn more possibilities by leveraging the latent relationships between the low-level feature and semantic feature, just like the famous saying "God rolls the dice" in Physics Nobel Prize 2022. Comparisons between the proposed SLLEN and other state-of-the-art techniques demonstrate the superiority of SLLEN with respect to LLE quality over all the comparable alternatives.
Convolutional neural networks for medical image segmentation
Nov 17, 2022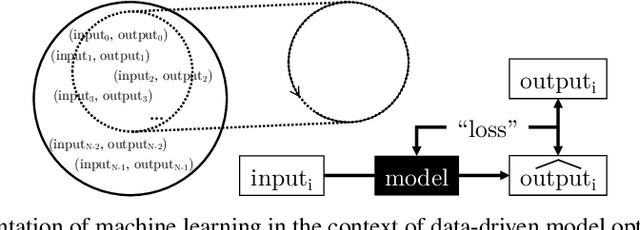
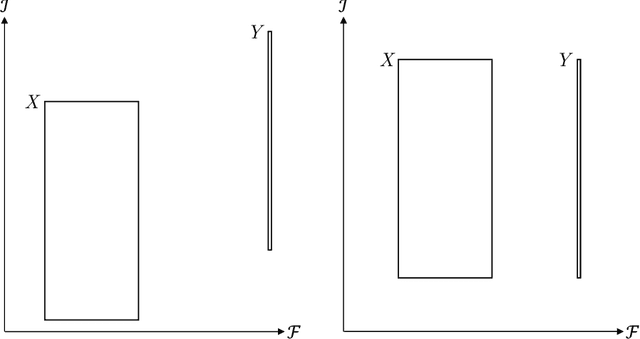
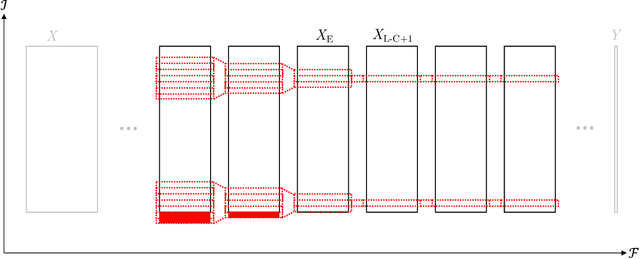
In this article, we look into some essential aspects of convolutional neural networks (CNNs) with the focus on medical image segmentation. First, we discuss the CNN architecture, thereby highlighting the spatial origin of the data, voxel-wise classification and the receptive field. Second, we discuss the sampling of input-output pairs, thereby highlighting the interaction between voxel-wise classification, patch size and the receptive field. Finally, we give a historical overview of crucial changes to CNN architectures for classification and segmentation, giving insights in the relation between three pivotal CNN architectures: FCN, U-Net and DeepMedic.
Few-shot Geometry-Aware Keypoint Localization
Mar 30, 2023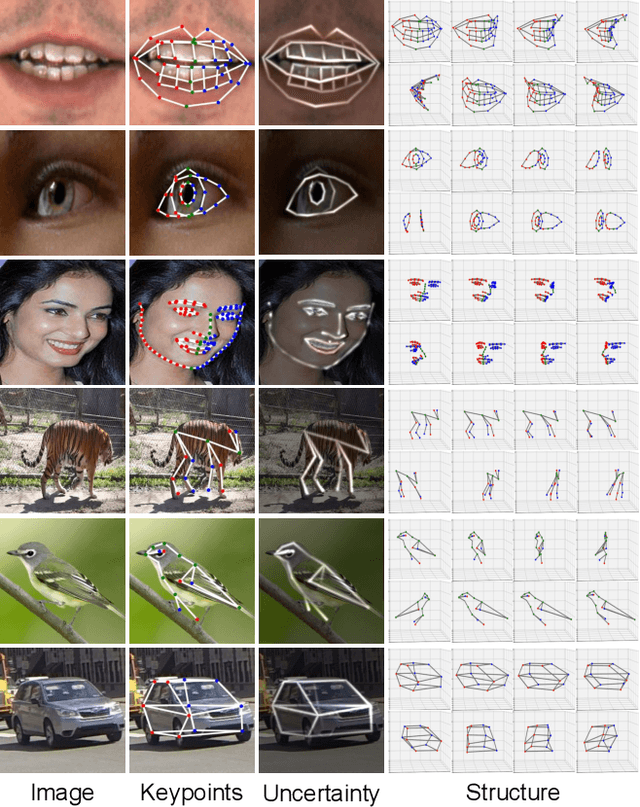
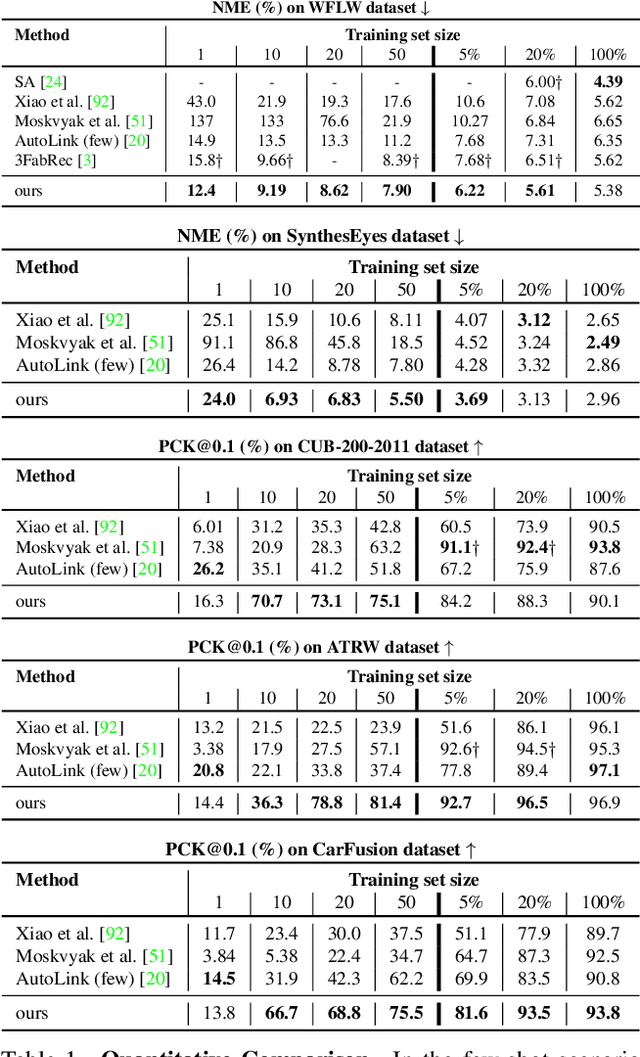
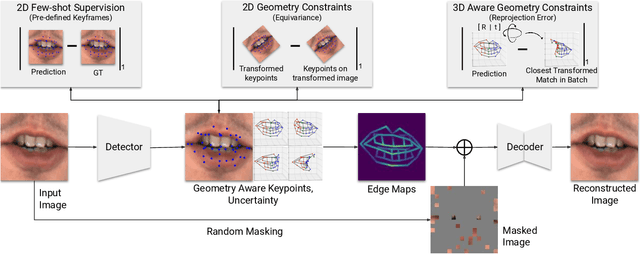
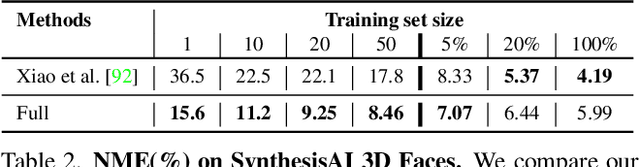
Supervised keypoint localization methods rely on large manually labeled image datasets, where objects can deform, articulate, or occlude. However, creating such large keypoint labels is time-consuming and costly, and is often error-prone due to inconsistent labeling. Thus, we desire an approach that can learn keypoint localization with fewer yet consistently annotated images. To this end, we present a novel formulation that learns to localize semantically consistent keypoint definitions, even for occluded regions, for varying object categories. We use a few user-labeled 2D images as input examples, which are extended via self-supervision using a larger unlabeled dataset. Unlike unsupervised methods, the few-shot images act as semantic shape constraints for object localization. Furthermore, we introduce 3D geometry-aware constraints to uplift keypoints, achieving more accurate 2D localization. Our general-purpose formulation paves the way for semantically conditioned generative modeling and attains competitive or state-of-the-art accuracy on several datasets, including human faces, eyes, animals, cars, and never-before-seen mouth interior (teeth) localization tasks, not attempted by the previous few-shot methods. Project page: https://xingzhehe.github.io/FewShot3DKP/}{https://xingzhehe.github.io/FewShot3DKP/
* CVPR 2023
Streaming Video Model
Mar 30, 2023
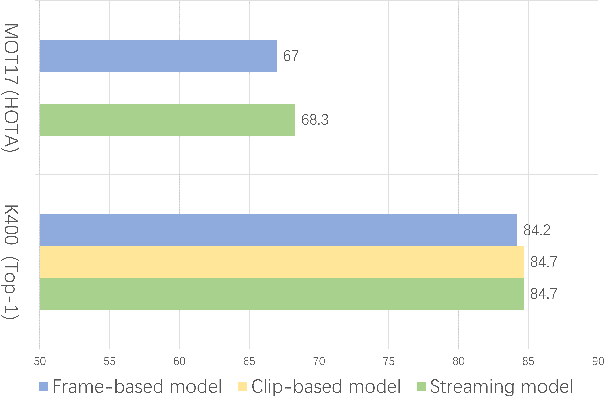
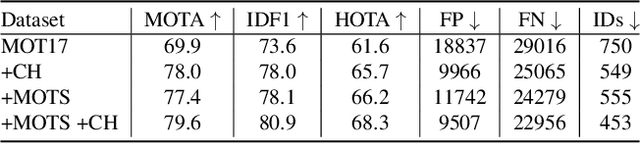
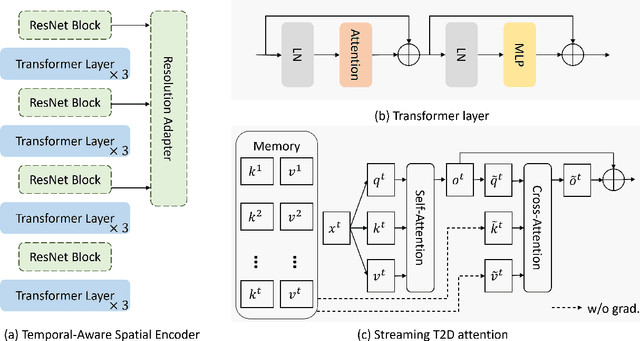
Video understanding tasks have traditionally been modeled by two separate architectures, specially tailored for two distinct tasks. Sequence-based video tasks, such as action recognition, use a video backbone to directly extract spatiotemporal features, while frame-based video tasks, such as multiple object tracking (MOT), rely on single fixed-image backbone to extract spatial features. In contrast, we propose to unify video understanding tasks into one novel streaming video architecture, referred to as Streaming Vision Transformer (S-ViT). S-ViT first produces frame-level features with a memory-enabled temporally-aware spatial encoder to serve the frame-based video tasks. Then the frame features are input into a task-related temporal decoder to obtain spatiotemporal features for sequence-based tasks. The efficiency and efficacy of S-ViT is demonstrated by the state-of-the-art accuracy in the sequence-based action recognition task and the competitive advantage over conventional architecture in the frame-based MOT task. We believe that the concept of streaming video model and the implementation of S-ViT are solid steps towards a unified deep learning architecture for video understanding. Code will be available at https://github.com/yuzhms/Streaming-Video-Model.
BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird's-Eye-View via Cross-Modality Guidance and Temporal Aggregation
Mar 30, 2023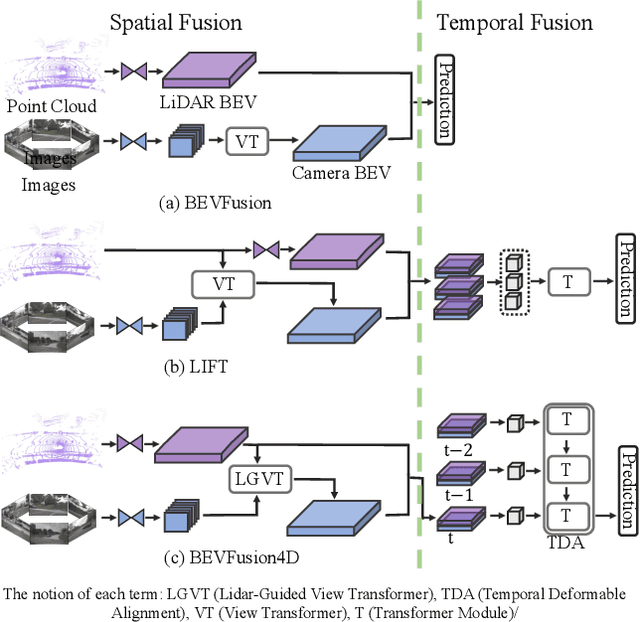
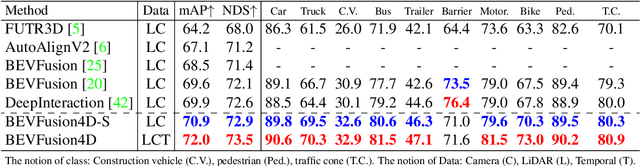

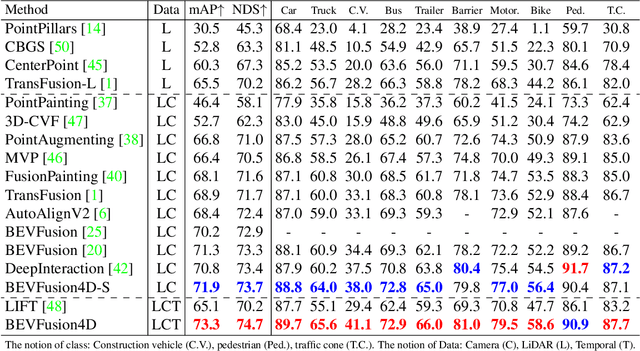
Integrating LiDAR and Camera information into Bird's-Eye-View (BEV) has become an essential topic for 3D object detection in autonomous driving. Existing methods mostly adopt an independent dual-branch framework to generate LiDAR and camera BEV, then perform an adaptive modality fusion. Since point clouds provide more accurate localization and geometry information, they could serve as a reliable spatial prior to acquiring relevant semantic information from the images. Therefore, we design a LiDAR-Guided View Transformer (LGVT) to effectively obtain the camera representation in BEV space and thus benefit the whole dual-branch fusion system. LGVT takes camera BEV as the primitive semantic query, repeatedly leveraging the spatial cue of LiDAR BEV for extracting image features across multiple camera views. Moreover, we extend our framework into the temporal domain with our proposed Temporal Deformable Alignment (TDA) module, which aims to aggregate BEV features from multiple historical frames. Including these two modules, our framework dubbed BEVFusion4D achieves state-of-the-art results in 3D object detection, with 72.0% mAP and 73.5% NDS on the nuScenes validation set, and 73.3% mAP and 74.7% NDS on nuScenes test set, respectively.
NeILF++: Inter-Reflectable Light Fields for Geometry and Material Estimation
Mar 30, 2023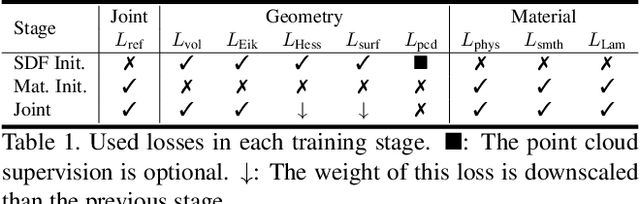

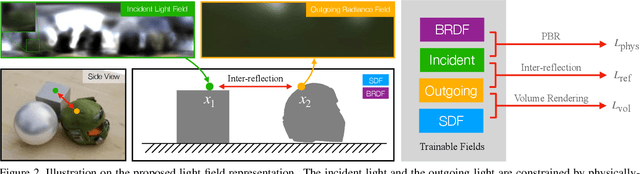
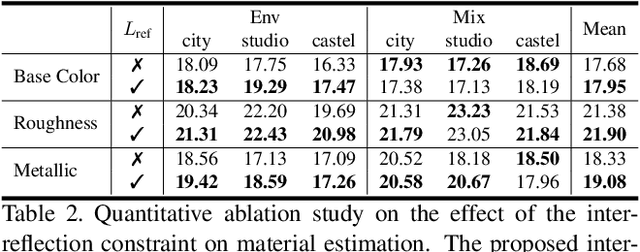
We present a novel differentiable rendering framework for joint geometry, material, and lighting estimation from multi-view images. In contrast to previous methods which assume a simplified environment map or co-located flashlights, in this work, we formulate the lighting of a static scene as one neural incident light field (NeILF) and one outgoing neural radiance field (NeRF). The key insight of the proposed method is the union of the incident and outgoing light fields through physically-based rendering and inter-reflections between surfaces, making it possible to disentangle the scene geometry, material, and lighting from image observations in a physically-based manner. The proposed incident light and inter-reflection framework can be easily applied to other NeRF systems. We show that our method can not only decompose the outgoing radiance into incident lights and surface materials, but also serve as a surface refinement module that further improves the reconstruction detail of the neural surface. We demonstrate on several datasets that the proposed method is able to achieve state-of-the-art results in terms of geometry reconstruction quality, material estimation accuracy, and the fidelity of novel view rendering.