 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Modal Facial Expression Recognition with Transformer-Based Fusion Networks and Dynamic Sampling
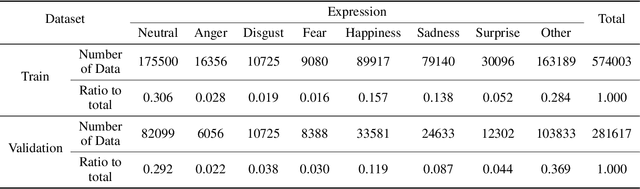
Mar 19, 2023Facial expression recognition is an essential task for various applications, including emotion detection, mental health analysis, and human-machine interactions. In this paper, we propose a multi-modal facial expression recognition method that exploits audio information along with facial images to provide a crucial clue to differentiate some ambiguous facial expressions. Specifically, we introduce a Modal Fusion Module (MFM) to fuse audio-visual information, where image and audio features are extracted from Swin Transformer. Additionally, we tackle the imbalance problem in the dataset by employing dynamic data resampling. Our model has been evaluated in the Affective Behavior in-the-wild (ABAW) challenge of CVPR 2023.
Facial Expression Recognition with Swin Transformer
Mar 25, 2022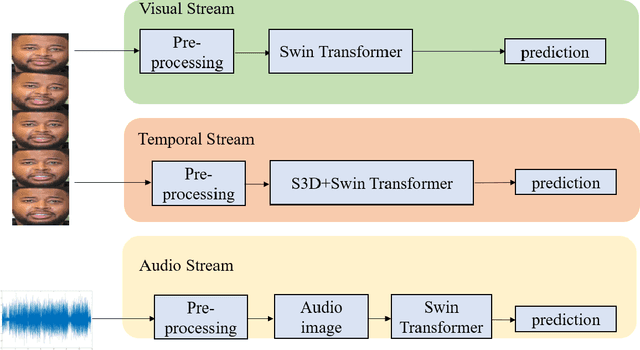

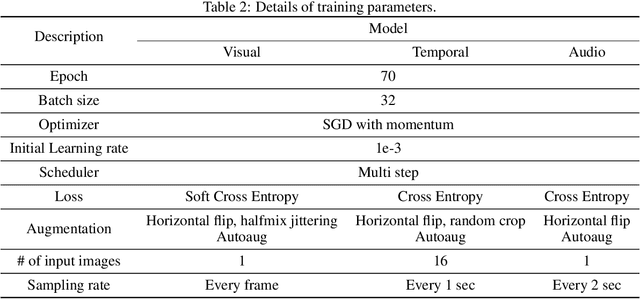
The task of recognizing human facial expressions plays a vital role in various human-related systems, including health care and medical fields. With the recent success of deep learning and the accessibility of a large amount of annotated data, facial expression recognition research has been mature enough to be utilized in real-world scenarios with audio-visual datasets. In this paper, we introduce Swin transformer-based facial expression approach for an in-the-wild audio-visual dataset of the Aff-Wild2 Expression dataset. Specifically, we employ a three-stream network (i.e., Visual stream, Temporal stream, and Audio stream) for the audio-visual videos to fuse the multi-modal information into facial expression recognition. Experimental results on the Aff-Wild2 dataset show the effectiveness of our proposed multi-modal approaches.