 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025



Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation
Dec 05, 2024



Recent advances in video diffusion models have unlocked new potential for realistic audio-driven talking video generation. However, achieving seamless audio-lip synchronization, maintaining long-term identity consistency, and producing natural, audio-aligned expressions in generated talking videos remain significant challenges. To address these challenges, we propose Memory-guided EMOtion-aware diffusion (MEMO), an end-to-end audio-driven portrait animation approach to generate identity-consistent and expressive talking videos. Our approach is built around two key modules: (1) a memory-guided temporal module, which enhances long-term identity consistency and motion smoothness by developing memory states to store information from a longer past context to guide temporal modeling via linear attention; and (2) an emotion-aware audio module, which replaces traditional cross attention with multi-modal attention to enhance audio-video interaction, while detecting emotions from audio to refine facial expressions via emotion adaptive layer norm. Extensive quantitative and qualitative results demonstrate that MEMO generates more realistic talking videos across diverse image and audio types, outperforming state-of-the-art methods in overall quality, audio-lip synchronization, identity consistency, and expression-emotion alignment.
Filler Word Detection with Hard Category Mining and Inter-Category Focal Loss
Apr 12, 2023



Filler words like ``um" or ``uh" are common in spontaneous speech. It is desirable to automatically detect and remove them in recordings, as they affect the fluency, confidence, and professionalism of speech. Previous studies and our preliminary experiments reveal that the biggest challenge in filler word detection is that fillers can be easily confused with other hard categories like ``a" or ``I". In this paper, we propose a novel filler word detection method that effectively addresses this challenge by adding auxiliary categories dynamically and applying an additional inter-category focal loss. The auxiliary categories force the model to explicitly model the confusing words by mining hard categories. In addition, inter-category focal loss adaptively adjusts the penalty weight between ``filler" and ``non-filler" categories to deal with other confusing words left in the ``non-filler" category. Our system achieves the best results, with a huge improvement compared to other methods on the PodcastFillers dataset.
Streaming Video Model
Mar 30, 2023



Video understanding tasks have traditionally been modeled by two separate architectures, specially tailored for two distinct tasks. Sequence-based video tasks, such as action recognition, use a video backbone to directly extract spatiotemporal features, while frame-based video tasks, such as multiple object tracking (MOT), rely on single fixed-image backbone to extract spatial features. In contrast, we propose to unify video understanding tasks into one novel streaming video architecture, referred to as Streaming Vision Transformer (S-ViT). S-ViT first produces frame-level features with a memory-enabled temporally-aware spatial encoder to serve the frame-based video tasks. Then the frame features are input into a task-related temporal decoder to obtain spatiotemporal features for sequence-based tasks. The efficiency and efficacy of S-ViT is demonstrated by the state-of-the-art accuracy in the sequence-based action recognition task and the competitive advantage over conventional architecture in the frame-based MOT task. We believe that the concept of streaming video model and the implementation of S-ViT are solid steps towards a unified deep learning architecture for video understanding. Code will be available at https://github.com/yuzhms/Streaming-Video-Model.
Look Before You Match: Instance Understanding Matters in Video Object Segmentation
Dec 13, 2022



Exploring dense matching between the current frame and past frames for long-range context modeling, memory-based methods have demonstrated impressive results in video object segmentation (VOS) recently. Nevertheless, due to the lack of instance understanding ability, the above approaches are oftentimes brittle to large appearance variations or viewpoint changes resulted from the movement of objects and cameras. In this paper, we argue that instance understanding matters in VOS, and integrating it with memory-based matching can enjoy the synergy, which is intuitively sensible from the definition of VOS task, \ie, identifying and segmenting object instances within the video. Towards this goal, we present a two-branch network for VOS, where the query-based instance segmentation (IS) branch delves into the instance details of the current frame and the VOS branch performs spatial-temporal matching with the memory bank. We employ the well-learned object queries from IS branch to inject instance-specific information into the query key, with which the instance-augmented matching is further performed. In addition, we introduce a multi-path fusion block to effectively combine the memory readout with multi-scale features from the instance segmentation decoder, which incorporates high-resolution instance-aware features to produce final segmentation results. Our method achieves state-of-the-art performance on DAVIS 2016/2017 val (92.6% and 87.1%), DAVIS 2017 test-dev (82.8%), and YouTube-VOS 2018/2019 val (86.3% and 86.3%), outperforming alternative methods by clear margins.
TridentSE: Guiding Speech Enhancement with 32 Global Tokens
Oct 24, 2022



In this paper, we present TridentSE, a novel architecture for speech enhancement, which is capable of efficiently capturing both global information and local details. TridentSE maintains T-F bin level representation to capture details, and uses a small number of global tokens to process the global information. Information is propagated between the local and the global representations through cross attention modules. To capture both inter- and intra-frame information, the global tokens are divided into two groups to process along the time and the frequency axis respectively. A metric discriminator is further employed to guide our model to achieve higher perceptual quality. Even with significantly lower computational cost, TridentSE outperforms a variety of previous speech enhancement methods, achieving a PESQ of 3.47 on VoiceBank+DEMAND dataset and a PESQ of 3.44 on DNS no-reverb test set. Visualization shows that the global tokens learn diverse and interpretable global patterns.
An Anchor-Free Detector for Continuous Speech Keyword Spotting
Aug 09, 2022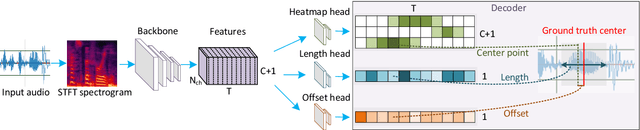
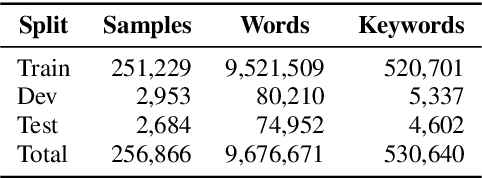
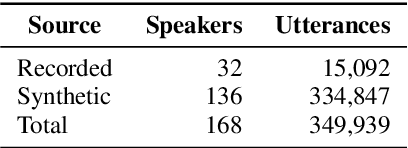

Continuous Speech Keyword Spotting (CSKWS) is a task to detect predefined keywords in a continuous speech. In this paper, we regard CSKWS as a one-dimensional object detection task and propose a novel anchor-free detector, named AF-KWS, to solve the problem. AF-KWS directly regresses the center locations and lengths of the keywords through a single-stage deep neural network. In particular, AF-KWS is tailored for this speech task as we introduce an auxiliary unknown class to exclude other words from non-speech or silent background. We have built two benchmark datasets named LibriTop-20 and continuous meeting analysis keywords (CMAK) dataset for CSKWS. Evaluations on these two datasets show that our proposed AF-KWS outperforms reference schemes by a large margin, and therefore provides a decent baseline for future research.
RetrieverTTS: Modeling Decomposed Factors for Text-Based Speech Insertion
Jun 28, 2022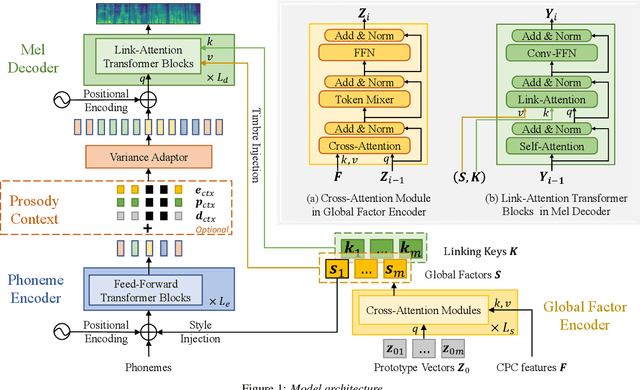
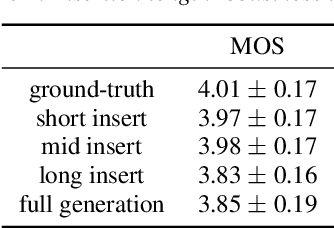
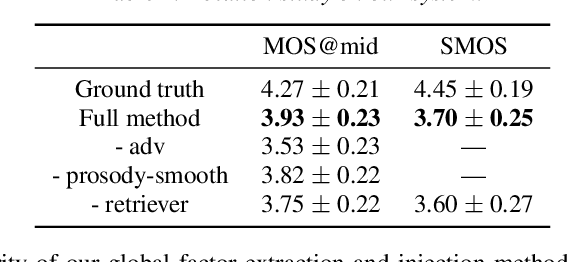
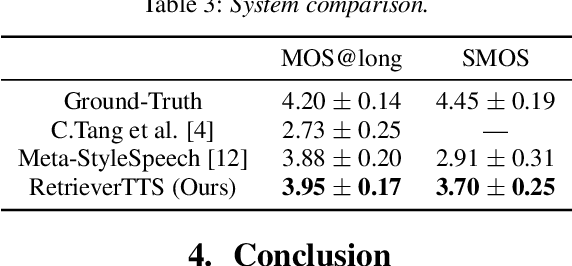
This paper proposes a new "decompose-and-edit" paradigm for the text-based speech insertion task that facilitates arbitrary-length speech insertion and even full sentence generation. In the proposed paradigm, global and local factors in speech are explicitly decomposed and separately manipulated to achieve high speaker similarity and continuous prosody. Specifically, we proposed to represent the global factors by multiple tokens, which are extracted by cross-attention operation and then injected back by link-attention operation. Due to the rich representation of global factors, we manage to achieve high speaker similarity in a zero-shot manner. In addition, we introduce a prosody smoothing task to make the local prosody factor context-aware and therefore achieve satisfactory prosody continuity. We further achieve high voice quality with an adversarial training stage. In the subjective test, our method achieves state-of-the-art performance in both naturalness and similarity. Audio samples can be found at https://ydcustc.github.io/retrieverTTS-demo/.
When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism
Jan 26, 2022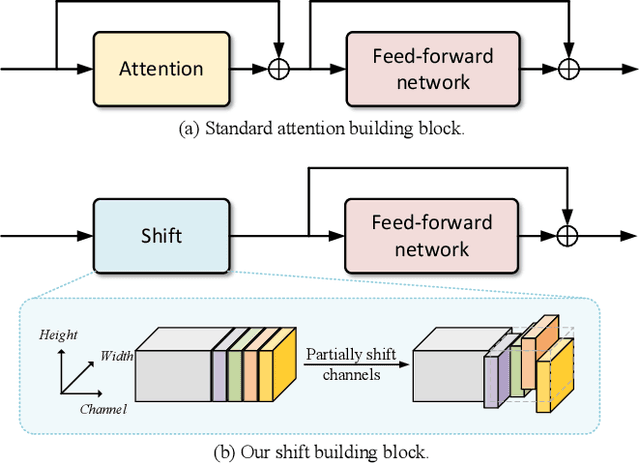
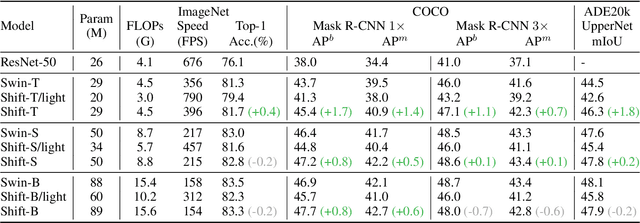
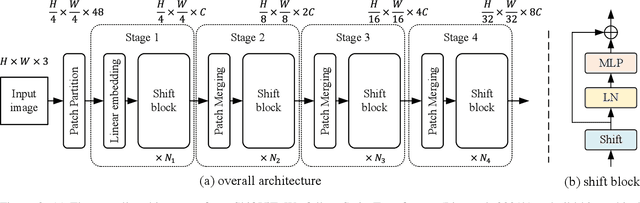
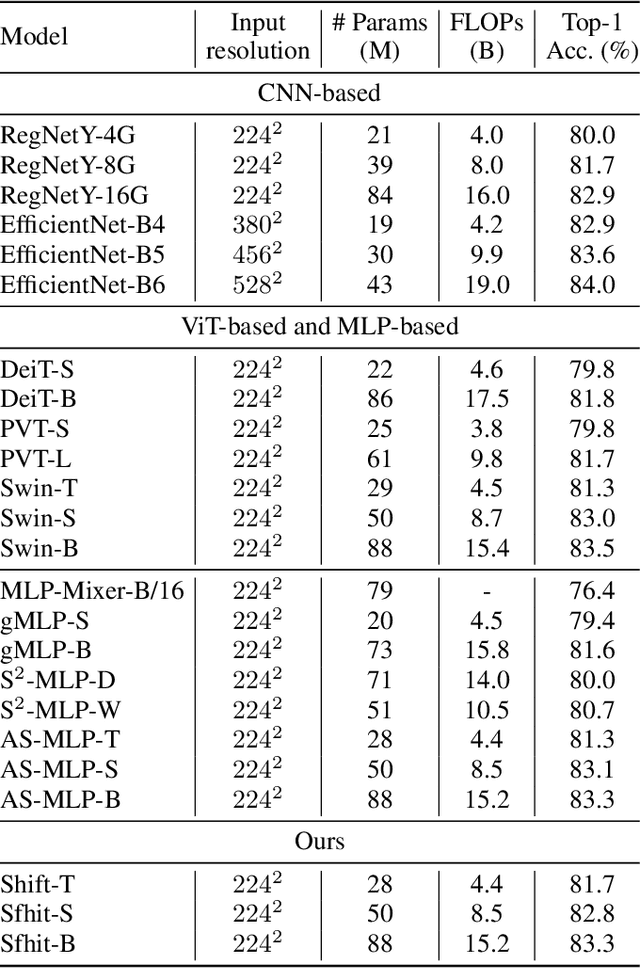
Attention mechanism has been widely believed as the key to success of vision transformers (ViTs), since it provides a flexible and powerful way to model spatial relationships. However, is the attention mechanism truly an indispensable part of ViT? Can it be replaced by some other alternatives? To demystify the role of attention mechanism, we simplify it into an extremely simple case: ZERO FLOP and ZERO parameter. Concretely, we revisit the shift operation. It does not contain any parameter or arithmetic calculation. The only operation is to exchange a small portion of the channels between neighboring features. Based on this simple operation, we construct a new backbone network, namely ShiftViT, where the attention layers in ViT are substituted by shift operations. Surprisingly, ShiftViT works quite well in several mainstream tasks, e.g., classification, detection, and segmentation. The performance is on par with or even better than the strong baseline Swin Transformer. These results suggest that the attention mechanism might not be the vital factor that makes ViT successful. It can be even replaced by a zero-parameter operation. We should pay more attentions to the remaining parts of ViT in the future work. Code is available at github.com/microsoft/SPACH.
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Sep 12, 2021
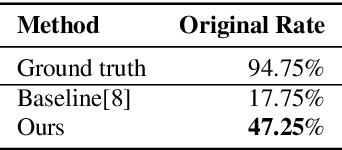
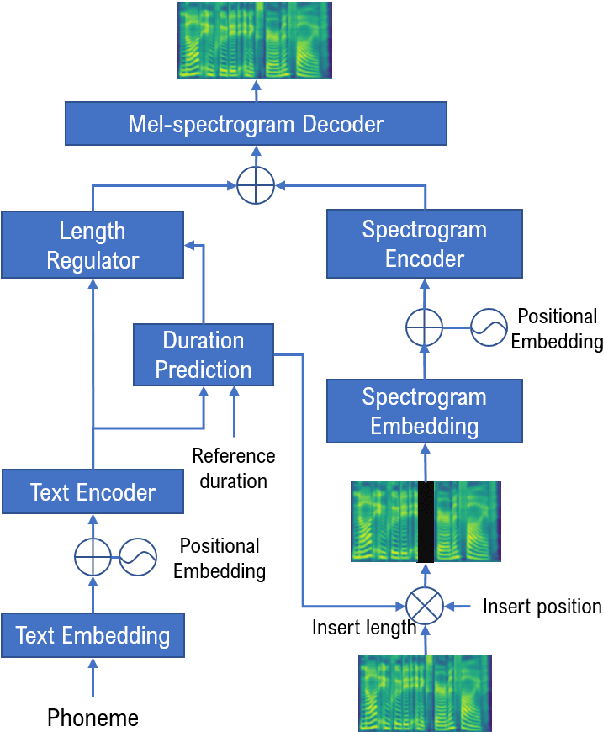
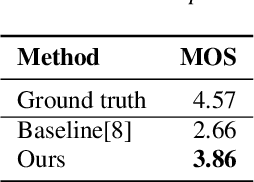
Given a piece of speech and its transcript text, text-based speech editing aims to generate speech that can be seamlessly inserted into the given speech by editing the transcript. Existing methods adopt a two-stage approach: synthesize the input text using a generic text-to-speech (TTS) engine and then transform the voice to the desired voice using voice conversion (VC). A major problem of this framework is that VC is a challenging problem which usually needs a moderate amount of parallel training data to work satisfactorily. In this paper, we propose a one-stage context-aware framework to generate natural and coherent target speech without any training data of the target speaker. In particular, we manage to perform accurate zero-shot duration prediction for the inserted text. The predicted duration is used to regulate both text embedding and speech embedding. Then, based on the aligned cross-modality input, we directly generate the mel-spectrogram of the edited speech with a transformer-based decoder. Subjective listening tests show that despite the lack of training data for the speaker, our method has achieved satisfactory results. It outperforms a recent zero-shot TTS engine by a large margin.