 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Mar 25, 2024
In recent years, advances in text-to-image (T2I) diffusion models have substantially elevated the quality of their generated images. However, achieving fine-grained control over attributes remains a challenge due to the limitations of natural language prompts (such as no continuous set of intermediate descriptions existing between ``person'' and ``old person''). Even though many methods were introduced that augment the model or generation process to enable such control, methods that do not require a fixed reference image are limited to either enabling global fine-grained attribute expression control or coarse attribute expression control localized to specific subjects, not both simultaneously. We show that there exist directions in the commonly used token-level CLIP text embeddings that enable fine-grained subject-specific control of high-level attributes in text-to-image models. Based on this observation, we introduce one efficient optimization-free and one robust optimization-based method to identify these directions for specific attributes from contrastive text prompts. We demonstrate that these directions can be used to augment the prompt text input with fine-grained control over attributes of specific subjects in a compositional manner (control over multiple attributes of a single subject) without having to adapt the diffusion model. Project page: https://compvis.github.io/attribute-control. Code is available at https://github.com/CompVis/attribute-control.
SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer
Mar 25, 2024Diffusion Transformer (DiT) has emerged as the new trend of generative diffusion models on image generation. In view of extremely slow convergence in typical DiT, recent breakthroughs have been driven by mask strategy that significantly improves the training efficiency of DiT with additional intra-image contextual learning. Despite this progress, mask strategy still suffers from two inherent limitations: (a) training-inference discrepancy and (b) fuzzy relations between mask reconstruction & generative diffusion process, resulting in sub-optimal training of DiT. In this work, we address these limitations by novelly unleashing the self-supervised discrimination knowledge to boost DiT training. Technically, we frame our DiT in a teacher-student manner. The teacher-student discriminative pairs are built on the diffusion noises along the same Probability Flow Ordinary Differential Equation (PF-ODE). Instead of applying mask reconstruction loss over both DiT encoder and decoder, we decouple DiT encoder and decoder to separately tackle discriminative and generative objectives. In particular, by encoding discriminative pairs with student and teacher DiT encoders, a new discriminative loss is designed to encourage the inter-image alignment in the self-supervised embedding space. After that, student samples are fed into student DiT decoder to perform the typical generative diffusion task. Extensive experiments are conducted on ImageNet dataset, and our method achieves a competitive balance between training cost and generative capacity.
Multi-Scale Texture Loss for CT denoising with GANs
Mar 25, 2024Generative Adversarial Networks (GANs) have proved as a powerful framework for denoising applications in medical imaging. However, GAN-based denoising algorithms still suffer from limitations in capturing complex relationships within the images. In this regard, the loss function plays a crucial role in guiding the image generation process, encompassing how much a synthetic image differs from a real image. To grasp highly complex and non-linear textural relationships in the training process, this work presents a loss function that leverages the intrinsic multi-scale nature of the Gray-Level-Co-occurrence Matrix (GLCM). Although the recent advances in deep learning have demonstrated superior performance in classification and detection tasks, we hypothesize that its information content can be valuable when integrated into GANs' training. To this end, we propose a differentiable implementation of the GLCM suited for gradient-based optimization. Our approach also introduces a self-attention layer that dynamically aggregates the multi-scale texture information extracted from the images. We validate our approach by carrying out extensive experiments in the context of low-dose CT denoising, a challenging application that aims to enhance the quality of noisy CT scans. We utilize three publicly available datasets, including one simulated and two real datasets. The results are promising as compared to other well-established loss functions, being also consistent across three different GAN architectures. The code is available at: https://github.com/FrancescoDiFeola/DenoTextureLoss
Can Language Beat Numerical Regression? Language-Based Multimodal Trajectory Prediction
Mar 27, 2024Language models have demonstrated impressive ability in context understanding and generative performance. Inspired by the recent success of language foundation models, in this paper, we propose LMTraj (Language-based Multimodal Trajectory predictor), which recasts the trajectory prediction task into a sort of question-answering problem. Departing from traditional numerical regression models, which treat the trajectory coordinate sequence as continuous signals, we consider them as discrete signals like text prompts. Specially, we first transform an input space for the trajectory coordinate into the natural language space. Here, the entire time-series trajectories of pedestrians are converted into a text prompt, and scene images are described as text information through image captioning. The transformed numerical and image data are then wrapped into the question-answering template for use in a language model. Next, to guide the language model in understanding and reasoning high-level knowledge, such as scene context and social relationships between pedestrians, we introduce an auxiliary multi-task question and answering. We then train a numerical tokenizer with the prompt data. We encourage the tokenizer to separate the integer and decimal parts well, and leverage it to capture correlations between the consecutive numbers in the language model. Lastly, we train the language model using the numerical tokenizer and all of the question-answer prompts. Here, we propose a beam-search-based most-likely prediction and a temperature-based multimodal prediction to implement both deterministic and stochastic inferences. Applying our LMTraj, we show that the language-based model can be a powerful pedestrian trajectory predictor, and outperforms existing numerical-based predictor methods. Code is publicly available at https://github.com/inhwanbae/LMTrajectory .
CPR: Retrieval Augmented Generation for Copyright Protection
Mar 27, 2024Retrieval Augmented Generation (RAG) is emerging as a flexible and robust technique to adapt models to private users data without training, to handle credit attribution, and to allow efficient machine unlearning at scale. However, RAG techniques for image generation may lead to parts of the retrieved samples being copied in the model's output. To reduce risks of leaking private information contained in the retrieved set, we introduce Copy-Protected generation with Retrieval (CPR), a new method for RAG with strong copyright protection guarantees in a mixed-private setting for diffusion models.CPR allows to condition the output of diffusion models on a set of retrieved images, while also guaranteeing that unique identifiable information about those example is not exposed in the generated outputs. In particular, it does so by sampling from a mixture of public (safe) distribution and private (user) distribution by merging their diffusion scores at inference. We prove that CPR satisfies Near Access Freeness (NAF) which bounds the amount of information an attacker may be able to extract from the generated images. We provide two algorithms for copyright protection, CPR-KL and CPR-Choose. Unlike previously proposed rejection-sampling-based NAF methods, our methods enable efficient copyright-protected sampling with a single run of backward diffusion. We show that our method can be applied to any pre-trained conditional diffusion model, such as Stable Diffusion or unCLIP. In particular, we empirically show that applying CPR on top of unCLIP improves quality and text-to-image alignment of the generated results (81.4 to 83.17 on TIFA benchmark), while enabling credit attribution, copy-right protection, and deterministic, constant time, unlearning.
NightHaze: Nighttime Image Dehazing via Self-Prior Learning
Mar 12, 2024
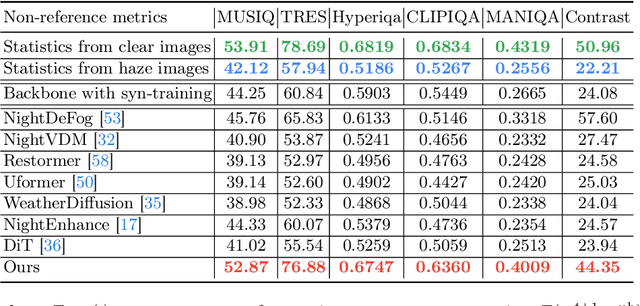
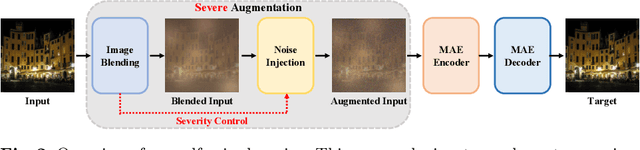
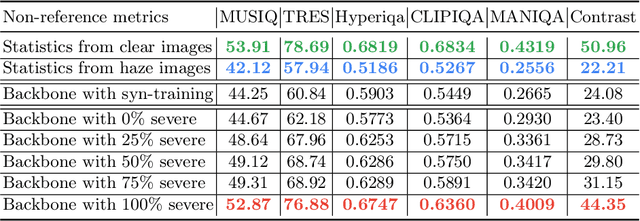
Masked autoencoder (MAE) shows that severe augmentation during training produces robust representations for high-level tasks. This paper brings the MAE-like framework to nighttime image enhancement, demonstrating that severe augmentation during training produces strong network priors that are resilient to real-world night haze degradations. We propose a novel nighttime image dehazing method with self-prior learning. Our main novelty lies in the design of severe augmentation, which allows our model to learn robust priors. Unlike MAE that uses masking, we leverage two key challenging factors of nighttime images as augmentation: light effects and noise. During training, we intentionally degrade clear images by blending them with light effects as well as by adding noise, and subsequently restore the clear images. This enables our model to learn clear background priors. By increasing the noise values to approach as high as the pixel intensity values of the glow and light effect blended images, our augmentation becomes severe, resulting in stronger priors. While our self-prior learning is considerably effective in suppressing glow and revealing details of background scenes, in some cases, there are still some undesired artifacts that remain, particularly in the forms of over-suppression. To address these artifacts, we propose a self-refinement module based on the semi-supervised teacher-student framework. Our NightHaze, especially our MAE-like self-prior learning, shows that models trained with severe augmentation effectively improve the visibility of input haze images, approaching the clarity of clear nighttime images. Extensive experiments demonstrate that our NightHaze achieves state-of-the-art performance, outperforming existing nighttime image dehazing methods by a substantial margin of 15.5% for MUSIQ and 23.5% for ClipIQA.
FluoroSAM: A Language-aligned Foundation Model for X-ray Image Segmentation
Mar 12, 2024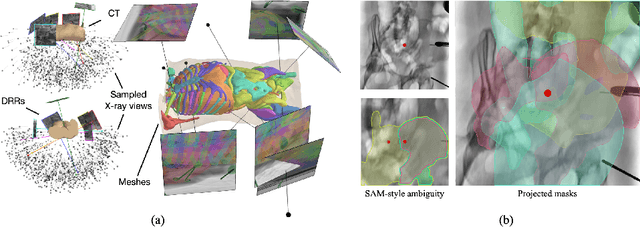
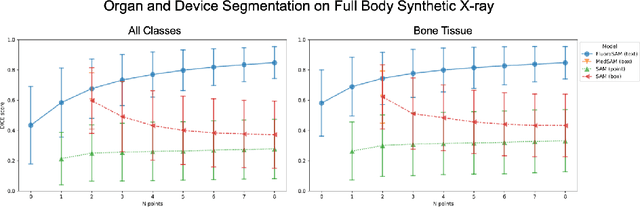
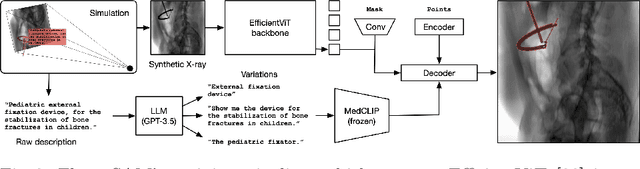
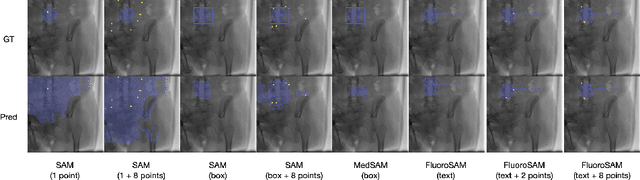
Automated X-ray image segmentation would accelerate research and development in diagnostic and interventional precision medicine. Prior efforts have contributed task-specific models capable of solving specific image analysis problems, but the utility of these models is restricted to their particular task domain, and expanding to broader use requires additional data, labels, and retraining efforts. Recently, foundation models (FMs) -- machine learning models trained on large amounts of highly variable data thus enabling broad applicability -- have emerged as promising tools for automated image analysis. Existing FMs for medical image analysis focus on scenarios and modalities where objects are clearly defined by visually apparent boundaries, such as surgical tool segmentation in endoscopy. X-ray imaging, by contrast, does not generally offer such clearly delineated boundaries or structure priors. During X-ray image formation, complex 3D structures are projected in transmission onto the imaging plane, resulting in overlapping features of varying opacity and shape. To pave the way toward an FM for comprehensive and automated analysis of arbitrary medical X-ray images, we develop FluoroSAM, a language-aligned variant of the Segment-Anything Model, trained from scratch on 1.6M synthetic X-ray images. FluoroSAM is trained on data including masks for 128 organ types and 464 non-anatomical objects, such as tools and implants. In real X-ray images of cadaveric specimens, FluoroSAM is able to segment bony anatomical structures based on text-only prompting with 0.51 and 0.79 DICE with point-based refinement, outperforming competing SAM variants for all structures. FluoroSAM is also capable of zero-shot generalization to segmenting classes beyond the training set thanks to its language alignment, which we demonstrate for full lung segmentation on real chest X-rays.
Deep unfolding Network for Hyperspectral Image Super-Resolution with Automatic Exposure Correction
Mar 14, 2024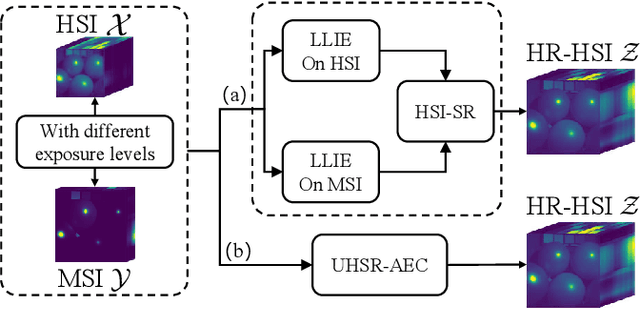
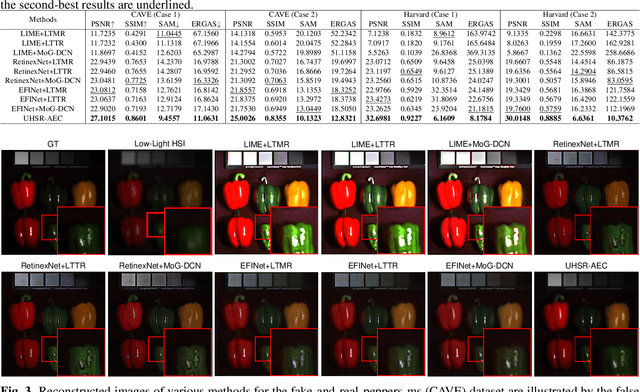
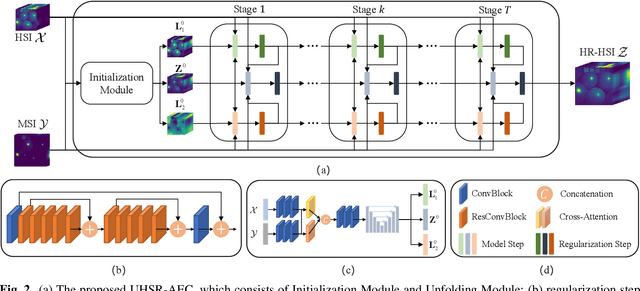
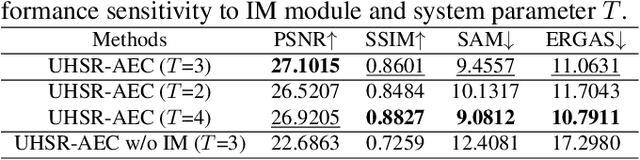
In recent years, the fusion of high spatial resolution multispectral image (HR-MSI) and low spatial resolution hyperspectral image (LR-HSI) has been recognized as an effective method for HSI super-resolution (HSI-SR). However, both HSI and MSI may be acquired under extreme conditions such as night or poorly illuminating scenarios, which may cause different exposure levels, thereby seriously downgrading the yielded HSISR. In contrast to most existing methods based on respective low-light enhancements (LLIE) of MSI and HSI followed by their fusion, a deep Unfolding HSI Super-Resolution with Automatic Exposure Correction (UHSR-AEC) is proposed, that can effectively generate a high-quality fused HSI-SR (in texture and features) even under very imbalanced exposures, thanks to the correlation between LLIE and HSI-SR taken into account. Extensive experiments are provided to demonstrate the state-of-the-art overall performance of the proposed UHSR-AEC, including comparison with some benchmark peer methods.
SCP-Diff: Photo-Realistic Semantic Image Synthesis with Spatial-Categorical Joint Prior
Mar 14, 2024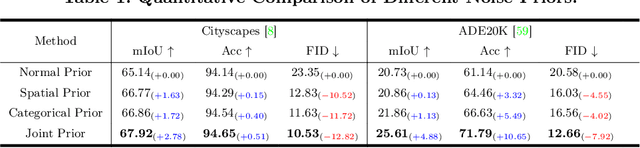
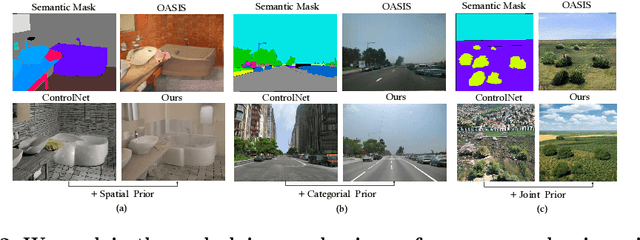
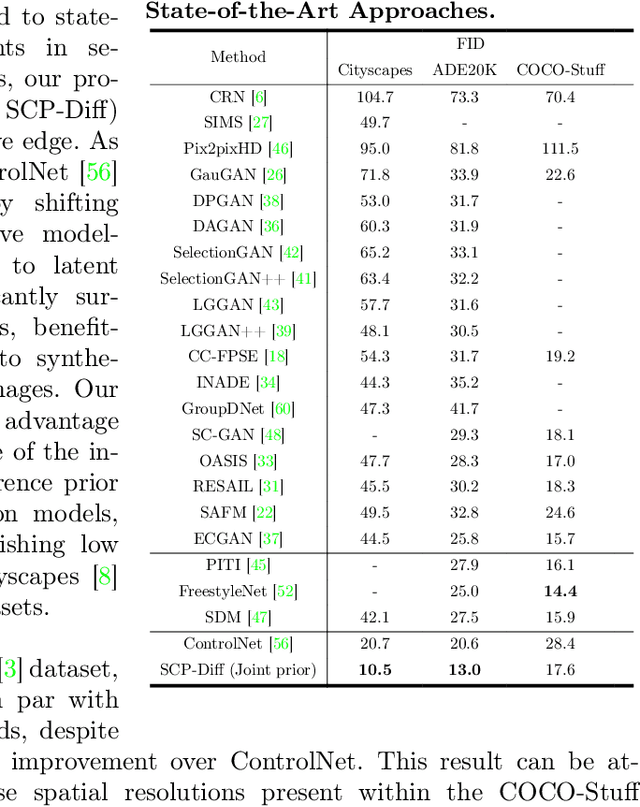
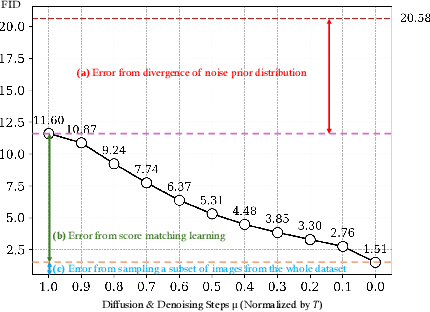
Semantic image synthesis (SIS) shows good promises for sensor simulation. However, current best practices in this field, based on GANs, have not yet reached the desired level of quality. As latent diffusion models make significant strides in image generation, we are prompted to evaluate ControlNet, a notable method for its dense control capabilities. Our investigation uncovered two primary issues with its results: the presence of weird sub-structures within large semantic areas and the misalignment of content with the semantic mask. Through empirical study, we pinpointed the cause of these problems as a mismatch between the noised training data distribution and the standard normal prior applied at the inference stage. To address this challenge, we developed specific noise priors for SIS, encompassing spatial, categorical, and a novel spatial-categorical joint prior for inference. This approach, which we have named SCP-Diff, has yielded exceptional results, achieving an FID of 10.53 on Cityscapes and 12.66 on ADE20K.The code and models can be accessed via the project page.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024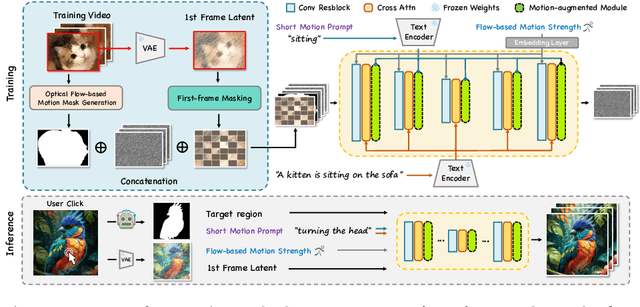
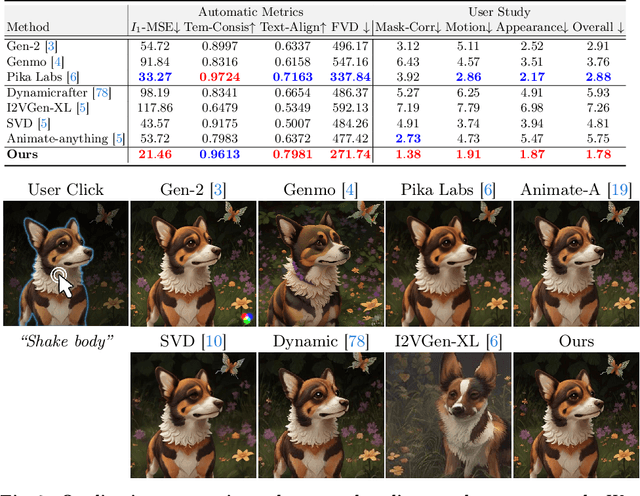

Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/